Utiliser les classe génériques des Collections
Objectifs : L'objectif de ce TP est de vous faire expérimenter avec la généricité en utilisant l'API des collections proposée par le JDK dans le package java.util
-
La javadoc de l'API collection (JDK 17)
Figure 3 : la javadoc de java.util. -
Pour un aperçu de l'API et la justification de la conception, vous pouvez consulter : The Collections Framework
-
Pour un tutoriel et un guide de programmation avec des exemples d'utilisation du framework collections, vous pouvez consulter : Collections Framework Tutorial
Attention : Les projets que vous devrez téléchargez pour les exerccies 1 et 2 sont des projets maven utilisant maven wrapper. Si vous travaillez sur linux, n'oubliez pas après avoir décompressé les fichiers .zip de changer les droits d'accès du script mvnw afin de le rendre exécutable en tapant la commande :
chmod oug+x mvnw
Exercice 1 : Lignes polygonales
En mathématiques, une ligne polygonale ou ligne brisée est une figure géométrique formée d’une suite de segments de droites reliant une suite de points.
Dans cet exercice il s'agit d'écire une classe LignePolygonale qui représente une ligne polygonale du plan \(Oxy\) et qui respecte les contraintes suivantes :
-
la ligne contient au moins deux sommets,
-
un même sommet peut être partagé par plusieurs lignes polygonales,
-
si un sommet peut appartenir à plusieurs lignes polygonales différentes, il n'est pas contre pas possible qu'il apparaisse plusieurs fois dans la même ligne polygonale.
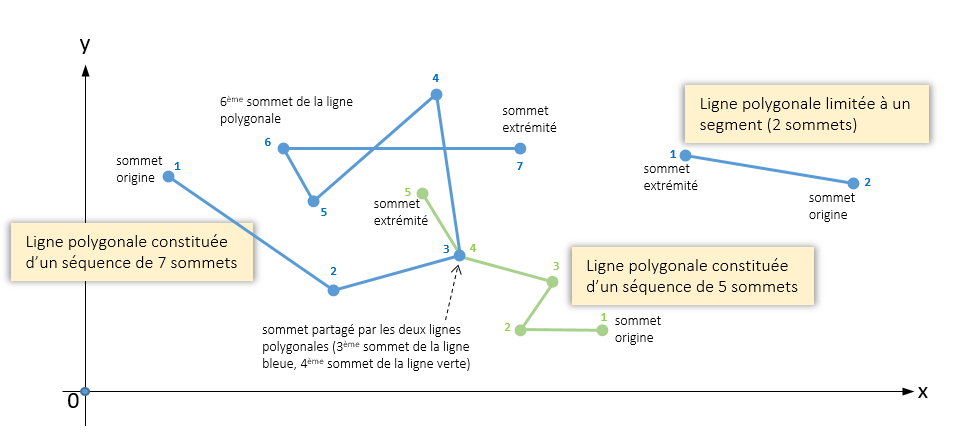
Les spécifications de la classe LignesPolygonale sont les suivantes (sachant que vous avez à votre disposition une classe Point donc javadoc est accessible ICI ) :
Les constructeurs proposés par la classe LignePolygonale permettent de définir une ligne polygonale contenant initialement uniquement deux points (la ligne est alors un segment de droite). Deux constructeurs sont possibles :
-
soit en passant en paramètre deux points (deux références d’objets Point) qui définiront respectivement le point origine et le point extrémité de la ligne polygonale,
-
soit en passant en paramètre 4 réels : l'abscisse et l'ordonnée de l’origine et l’abscisse et l’ordonnée de l’extrémité de la ligne.
Ces constructeurs doivent garantir le fait que la ligne polygonale n'est pas "dégénérée", c'est à dire que son origine et son extrémité ne sont pas identiques. Dans le cas contraire l'objet n'est pas créé et une exception de type java.lang.IllegalArgumentException (sous classe de java.lang.RunTimeException) est lancée.
Les méthodes de cette classe sont :
-
getOrigine qui retourne le premier sommet de la ligne.
-
getExtremite qui retourne le dernier sommet de la ligne.
-
getNbSommets qui retourne le nombre de sommets de la ligne.
-
getSommet qui retourne le \(i^{ème}\) sommet de la ligne, \(i \in [1..n]\) où \(n\) est le nombre de sommets de la ligne
-
supprimerSommet qui permet de supprimer le \(i^{ème}\) sommet de la ligne, \(i \in [1..n]\) où \(n\) est le nombre de sommets de la ligne. Bien entendu cette méthode n'a un sens que si la ligne contient plus de deux sommets. Dans le cas contraire une exception de type java.lang.IllegalArgumentException sera levée.
-
ajouterSommet qui ajoute un nouveau sommet à la ligne. Ce nouveau sommet sera ajouté après le sommet extrémité de la ligne (c’est-à-dire en fin de la liste des sommets qui définissent la ligne). On vérifiera que la contrainte n° 3 (un sommet ne peut apparaître plusieurs fois dans la même ligne polygone) est respectée. C'est à dire que le sommet à ajouter n’est pas identique à l'un des sommets déjà présents dans la ligne polygonale. Dans le cas contraire une exception de type java.lang.IllegalArgumentException sera levée.
Pour offrir plus de souplesse au programmeur cette méthode existe sous deux formes (surcharge) :
-
soit avec deux paramètres réels (l’abscisse et l’ordonnée du sommet à ajouter).
-
soit avec comme paramètre un point (référence d’un objet Point) fournissant les coordonnées du sommet à ajouter.
Pour faciliter les ajouts successifs de plusieurs sommets, la méthode ajouterSommet retourne la référence de la ligne (la référence de l’objet LignePolygonale qui reçoit le message). Ainsi pour ajouter trois sommets à une ligne polygonale, au lieu d’écrire
ligne.ajouterSommet(x1,y1) ; ligne.ajouterSommet(x2,y2) ; ligne.ajouterSommet(x3,y3) ;on pourra écrire
ligne.ajouterSommet(x1,y1).ajouterSommet(x2,y2).ajouterSommet(x3,y3) ; -
-
contient qui permet de tester si la ligne polygonale contient un sommet identique à un point donné.
-
getLongueur qui calcule la longueur de la ligne, c'est à dire la longeur des segments qui la composent.
-
toString qui renvoie une représentation textuelle (chaîne de caractères) de la ligne, plus précisément les coordonnées de chacun de ses sommets. Par exemple, pour une ligne de 4 sommets (0.0,0.0), (14.0,6.0), (25.0,-2.0), (5.0,-8.0), la chaîne retournée par cette méthode sera :
"LignePolygonale[1:(0.0,0.0),2:(14.0,6.0),3:(25.0,-2.0),4:(5.0,-8.0)]" -
equals qui permet de tester l'égalité de la ligne avec une autre ligne (deux lignes sont considérées égales si elles ont le même nombre de sommets et que tous les sommets de la première sont identiques aux sommets de la seconde et ce dans le même ordre).
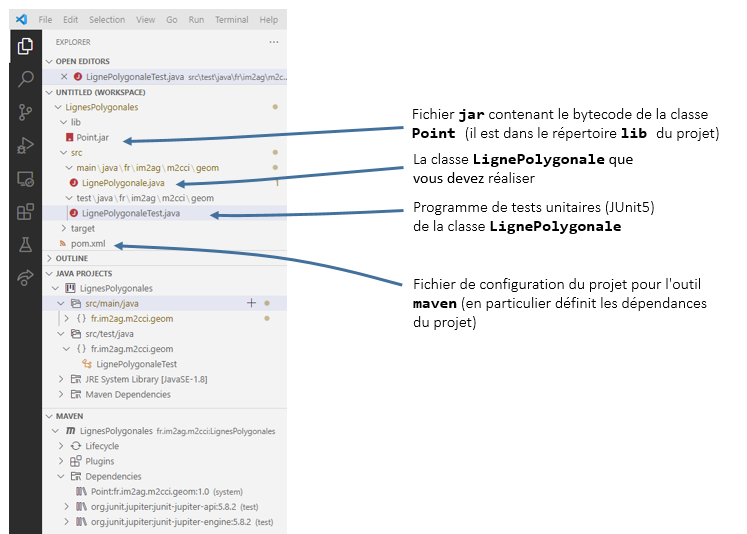
Adepte du TDD (Test Driven Development ou en français Développement Piloté par les Tests), le chef de projet qui vous a confié la tâche de coder la classe LignePolygonale a pris le soin de faire écrire auparavant, par un développeur chargé des tests, un programme de tests unitaires (en utilisant le framework Junit 5) de cette classe. Ce programme, LignePolygonaleTest se trouve dans le dossier Test Packages du projet maven LignesPolygonales (voir figure ci-dessous).
Question:
-
Téléchargez le fichier LignesPolygonales.zip archive du projet LignesPolygonales
-
Décompressez le fichier LignesPolygonales.zip et ouvrez le projet dans votre IDE.
-
En respectant les spécifications fournies, complétez le code de la classe LignePolygonale et vérifiez que les tests unitaires définis dans LignePolygonaleTest sont tous exécutés avec succès.
Vous ne devez pas modifier le code de LignePolygonaleTest.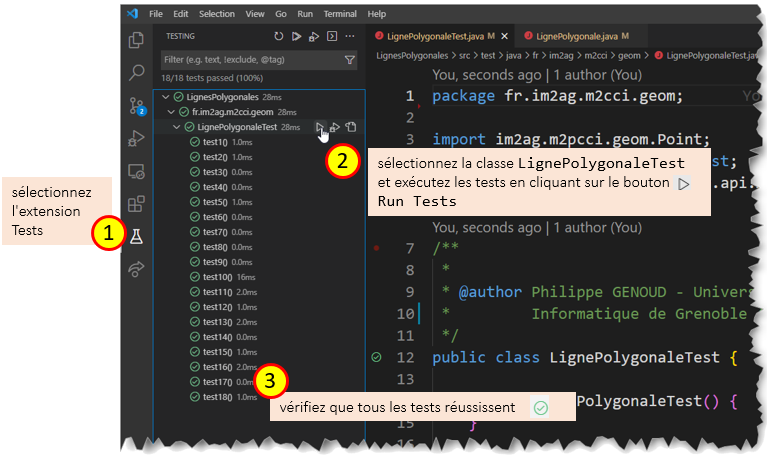
exécution des tests unitaires du projet LignesPolygonales. -
Le développeur des tests à oublié de tester la méthode supprimerSommet. Rajoutez un test unitaire permettant de vérifier son bon fonctionnement.
Exercice 2 : Gestion d'un panier électronique
En vue de l'écriture d'une application de e-commerce, il vous est demandé d'implémenter une classe permettant de gérer un panier électronique.
Le diagramme de classes UML ci-dessous (Figure 1) présente la manière dont le panier électronique d'un utilisateur est modélisé à l'aide de classes Java.
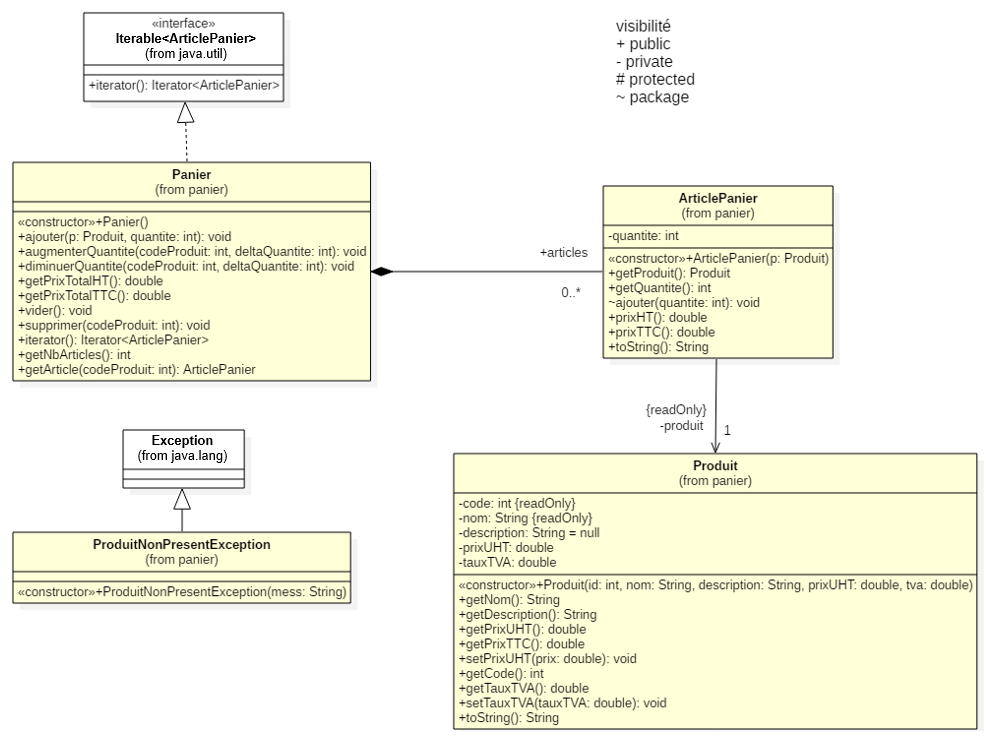
La classe Produit represente les produits vendus par le site. Un produit est défini par:
son code, un entier qui l'identifie de manière unique,
une chaîne de caractères correspondant au nom du produit,
une chaîne de caractères correspondant à la description du produit,
son prix hors taxes (HT), un réel,
le taux de TVA (Taxe à la Valeur Ajoutée), un réel (par exemple 19.6 si une TVA de 19,6% est appliquée au produit).
Chaque élément du panier est représenté par un objet ArticlePanier qui associe un objet Produit à une quantité donnée. Par exemple, si un utilisateur veut acheter deux exemplaires du livre "La griffe du chien" de Don Wislow et un DVD "Gran Torino"¨de Clint Eastwood, l'objet Panier représentant son panier électronique contiendra deux objets ArticlePanier:
le premier associant la quantité 2 à l'objet Produit représentant le livre "La griffe du chien",
le second associant la quantité 1 à l'objet Produit représentant le DVD "Gran Torino".
Les classes Produit et ArticlePanier ont déjà été écrites, la classe Panier a été spécifiée. Seul le squelette de la classe avec les commentaires documentant des différentes méthodes ont été écrits, les méthodes n'ont pas été implémentées. Par contre, dans une approche TDD (Test Driven Development) un programme JUnit pour les tests unitaires du panier a été écrit.

Votre travail va consister à écrire l'implémentation du Panier en respectant les spécifications qui vous sont fournies.
Question 1 :
- Téléchargez le projet maven contenant le code modélisant le panier élecronique : e-panier.zip
- Décompréssez le fichier e-panier, ouvrez le projet correspondant avec votre IDE et étudiez attentivement le code existant.
Question 2 :
Quelle structure de données parmi celles proposées par le package java.util vous semble-t-il judicieux d'utiliser pour stocker les articles du panier (représentés par des objets ArticlePanier) ? Justifiez votre réponse.
-
Quelle déclaration feriez vous pour l'attribut représenté par la relation de composition articles dans le diagramme de classes (Figure 1) ?
Réflechissez par vous même et ensuite comparez avec la réponse proposée en cliquant sur ce bouton
un Map (table associative) indexée par les numéros de produits et dont les valeurs seraient des objets ArticlePanier est certainement la structure de données qui rendra la programmation la plus facile. En effet si on regarde les méthodes de la classe panier, nombre d'entre elles nécessitent de rechercher l'article de panier correspondant à un produit à partir du code du produit (augmenterQuantite(), diminuerQuantite(), supprimer()...). Une table associative avec comme clés les codes de produit et comme valeurs les articles correspondant rendra les opérations de recherche, d'insertion et suppression triviales (via les methodes correspondantes de l'interface java.util.Map).
Sa déclaration serait:
private Map<Integer, ArticlePanier> articles = new HashMap<>();et nécessiterait les imports
import java.util.HashMap;
import java.util.Map;Question 3 : En utilisant la structure de données choisie à la question 2 implémentez la classe Panier et vérifiez que votre code fonctionne comme attendu en exécutant les tests unitaires définis dans la classe PanierTest. Tous les tests doivent réussir !
Vous devez respecter strictement les spécifications fournies dans les commentaires documentants de Panier et ne devez en aucun cas modifer le code du programme de tests PanierTest.
Avant de vous lancer dans la programmation, parcourez la documentation de l'interface définissant le type abstrait correspondant à la structure de données que vous avez choisie (question 2) afin d'utiliser au mieux les services qu'elle offre.
Exercice 3 : Indexation de textes
Le but de cet exercice est d'écrire un programme effectuant l'indexation de texte. Il s'agit à partir d'un fichier texte fourni en entrée de créer un index qui pour chaque mot rencontré donne :
- le nombre total d'occurences du mot dans le texte
- le texte étant découpé en pages , pour chaque page où le mot apparait , le nombre d'occurences du mot dans la page et les numéros de ligne où il apparait.
Le texte est dans un fichier .txt (au format UTF8) et est subdivisé en plusieurs pages, le début d'une page est marqué par une ligne débutant par un #.
Ci dessous, un exemple d'un tel texte et l'indexation obtenue pour le mot 'neque'
#page 1
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aenean placerat ornare lacus vel fringilla.
Nunc vel cursus neque. Etiam interdum libero at lectus tempus, vel maximus dui lobortis.
Ut aliquam eu justo non tristique. Integer vehicula odio nulla, at euismod nisi laoreet vitae.
...
#page 2
Fieri, inquam, Triari, nullo pacto potest, ut non dicas, quid non probes eius,
a quo dissentias. quid enim me prohiberet Epicureum esse, si probarem, quae ille diceret?
cum praesertim illa perdiscere ludus esset. Quam ob rem dissentientium inter se reprehensiones
non sunt vituperandae, maledicta, contumeliae, tum iracundiae, contentiones concertationesque
in disputando pertinaces indignae philosophia mihi videri solent.
...
#page 6
Quam quidem partem accusationis admiratus sum et moleste tuli potissimum esse
Atratino datam. Neque enim decebat neque aetas illa
orationi meae postulabat neque, id quod animadvertere poteratis,
pudor patiebatur optimi adulescentis in tali illum oratione versari.
Vellem aliquis ex vobis robustioribus hunc male dicendi locum suscepisset;
aliquanto liberius et fortius et magis more nostro refutaremus istam male dicendi
licentiam. Tecum, Atratine, agam lenius, quod et pudor tuus moderatur
...indexation de 'neque'
NEQUE nbre total d'occurences : 4
page 1, nbre d'occurences : 1, lignes: 2
page 6, nbre d'occurences : 3, lignes: 4 4 5 Dans les questions qui suivent il va s'agir d'écrire un programme permettant de lire un fichier texte au format précédent et de construire un objet index sur lequel on pourra ensuite effectuer les requêtes suivantes:
- indiquer si un mot est présent ou non dans l'index,
- obtenir pour un mot donné :
- son nombre total d'occurences,
- le détail des ses occurences,
- obtenir les entrées d'index :
- par ordre alphabétique,
- par ordre de nombre d'occurences décroissant.
Pour réaliser cette application vous allez procéder de manière progressive.
Etape 1 : lecture du fichier de données
Dans un premier temps vous allez vous contenter d'écrire un simple programme capable de lire un fichier texte et d'afficher sur la console pour chaque ligne :
- le numero de la page où elle se trouve.
- le numero de ligne dans la page
- le nombre mots qu'elle contient ainsi que chacun de ceux-ci en lettres majuscules.
La figure ci-dessous montre le résultat attendu pour le fichier Test.txt

Question 1 : Ecrivez ce programme en vous inspirant de ce qui a été fait dans le TP précédent (TP sur les exceptions) où vous lisiez des descriptions de formes dans un fichier texte.
-
Créez un nouveau projet maven d'application Java (par exempleTextIndexation),
-
Dans ce projet créez un répertoire data dans lequel vous recopierez les fichiers de données Test.txt et LoremIpsum.txt (téléchargez les fichiers en en effectuant un clic droit sur le lien et sélectionnant dans le menu contextuel l'item Enregistrer la cible du lien).
-
Créez une classe TextIndexBuilder contenant une méthode statique void createIndex(String nomFichier) qui lit ligne par ligne le fichier texte dont le nom est passé en paramètre et qui pour chaque ligne lue affiche:
- le numero de la page où elle se trouve.
- le numero de ligne dans la page
- le nombre mots qu'elle contient (si un mot est présent plusieurs fois dans la ligne, il sera compté autant de fois qu'il apparait)
- chacun des mots en lettres majuscules.
Attention : pensez à ignorer les caractères de ponctuation (
. , ;). -
Créez une classe AppliIndexation contenant une méthode main qui demande à l'utilisateur un nom de fichier et lit ce fichier en invoquant la méthode createIndex de votre classe TextIndexBuilder.
-
Exécutez votre programme avec le fichier de données Test.txt et vérifiez que vous obtenez bien un résultat similaire à celui montré dans la figure précédente.
La petite difficulté consiste à découper la ligne lue en ignorant les caractères de ponctuation. Dans le TP9, on utilisait la méthode split de String pour sauter un ou plusieurs espaces entre les différents éléments de la ligne
String[] tokens = ligne.toUpperCase().split("\\s+");Mais ici cela ne suffit plus, pour que le tableau tokens contiennent les mots sans les caractères de ponctuation plusieurs manières de procéder sont possibles :
-
remplacer dans la ligne toutes les occurrences de de
'.'','et';'par un caractère espace' 'puis utiliser split avec l'expression régulière précédente (voir la méthode replace de la classe String. -
modifier l'expression régulière utilisée par split pour qu'elle prenne en compte les caractères de ponctuation
String[] tokens = ligne.toUpperCase().split("((,?|\\.?|;?)\\s+)|(,?|\\.?|;?)$");
Pour en savoir plus sur les expressions régulières quelque slides sur celles-ci en JavaScript, sachant qu'en Java la syntaxe est similaire.
Etape 2 : Index simplifié
Maintenant que le programme de lecture du fichier de données est en place, vous allez créer un classe Index qui pour le moment mettra en oeuvre une version simplifiée de l'index, à savoir un index ne donnant que le nombre d'occurences de chaque mot dans le texte.
Les opérations définies pour un objet Index sont :
-
void ajouterOccurence(String mot) qui ajoute une occurence du mot à l'index,
-
int getNbreOccurences(String mot) qui retourne le nombre d'occurences du mot passé en paramètre.
-
Set<String> entrées() qui retourne l'ensemble des entrées (mots) de l'index
-
void afficherParOrdreAlphabetique() qui affiche sur la console les entrées d'index triées par ordre alphabétique. Par exemple pour le texte Test.txt on aura :

-
void afficherParNbreOccurences() qui affiche sur la console les entrées d'index triées par nombre d'occurences décroissant. Par exemple pour le texte Test.txt on aura :

Question 2
-
Implémentez la classe Index. Quelle structure de données vous parait-il judicieux d'utiliser ?
-
Modifiez la méthode createIndex de manière à ce qu'elle construise et retourne un objet Index dans lequel seront enregistrés le nombre d'occurences totales de chaque mot.
-
Modifiez votre programme principal AppliIndexation de manière à ce que, une fois l'index créé, vous affichiez son contenu dans l'ordre alphabétique puis par ordre de nombre d'occurrences. Exécutez le sur le fichier Test.txt, vous devriez obtenir quelque chose de similaire aux figures précédentes
-
Modifiez votre programme principal pour que l'utilisateur puisse choisir un mot et obtenir son nombre d'occurences (c'est opération doit pouvoir être renouvelée autant de fois que l'utilisateur le souhaite).
Etape 3 : Index détaillé
Vous allez maintenant modifier votre application de manière à ce que toute les fonctionnalités de l'index soient implémentées, c'est à dire que, en plus du nombre d'occurences d'un mot, il soit également possible d'obtenir une information détaillée, à savoir pour chaque mot présent dans l'index:
-
les numéros de pages où il apparait,
-
pour chacune de ces pages
-
le nombre d'occurences du mot dans la page,
-
les numéros des lignes où il apparait.
-
Par exemple, un fois le fichier Test.txt indexé, on souhaite avoir accès aux informations suivantes pour le mot FACTI.

Question 3.1 : Réflechissez à une structure de données pour la réalisation de l'index. Quelles classes doivent être définies, quels sont leurs attributs et méthodes, quelles relations les relient ? Réalisez diagramme de classes présentant votre modélisation objet de l'index.
Pour stocker les données de l'index vous pouvez utiliser une Map dont les clés seraient les mots et les valeurs des objets instances d'une classe IndexEntry. Les attributs d'un objet IndexEntry seraient:
- le mot indexé,
- son nombre total d'occurences,
- une liste d'occurences détailées.
Les occurences détaillées étant elles-même représentées par des objets instance d'une classe PageDetail et dont les attributs seraient:
- le numéro de la page,
- le nombre d'occurences du mot dans la page,
- la liste des numéros de lignes où le mot apparaît.
La figure ci-dessous montre le diagramme de classe correspondant

Question 3.2 : Modifiez votre application de manière à ce que toute les fonctionnalités de l'index soient implémentées.
Votre programme principal une fois l'index construit doit offrir à l'utilisateur le choix entre les opérations suivantes :
-
rechercher l'information détaillée pour un mot donné,
-
afficher l'index complet (et détaillé) par ordre alphabétique,
-
afficher l'index complet (et détaillé) selon le nombre d'occurrences décroissant,
-
changer l'index en choissant un autre fichier de données.