L'objectif de cette scéance de TP est de vous familiariser avec le modèle de données RDF et ses différents formats de sérialisation.
Exercice 1 : Explorer le web des données à partir de DBpedia
"DBpedia est un projet universitaire et communautaire d'exploration et extraction automatiques de données dérivées de Wikipédia. Son principe est de proposer une version structurée et sous forme de données normalisées au format du web sémantique des contenus encyclopédiques de chaque fiche encyclopédique. DBpedia vise aussi à relier à Wikipédia (et inversement) des ensembles d'autres données ouvertes provenant du Web des données." (http://fr.wikipedia.org/wiki/DBpedia)
a) Ressource DBpedia
A chaque page Wikipedia dont l'URL de la forme https://en.wikipedia.org/wiki/XXXXcorrespond une
ressource DBpedia dont l'URI est http://dbpedia.org/resource/XXXX où XXXX
désigne le sujet de la page. Par exemple, à la page consacrée à Grenoble
(https://en.wikipedia.org/wiki/Grenoble)
correspond la ressource http://dbpedia.org/resource/Grenoble.
-
Quelle l'URI désignant dans DBpedia l'Université Grenoble Alpes ?
Solution A n'utiliser qu'après avoir (un peu) cherché par vous même -
Que se passe-t-il lorsque vous saisissez cette URI dans la barre de navigation de votre navigateur ?
-
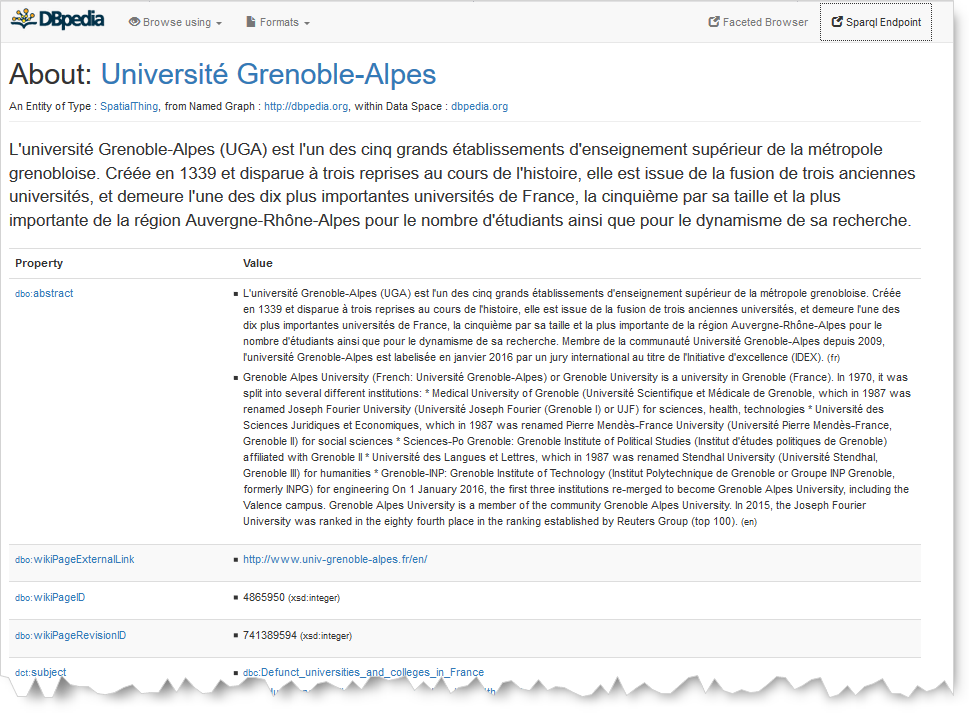
Que représente la page affichée dans le navigateur ?
-
Quelle est l'URL affichée dans la barre de navigation ? Pourquoi diffère-t-elle de l'URI que vous avez saisie ?
-
Quels ont été les échanges (requêtes et réponses HTTP) entre votre navigateur et le serveur
dbpedia.org?
-
-
Est-il possible de récupérer la description RDF de cette ressource dans le format de sérialisation Turtle ? Comment ?
Solution -
Recupérez la description en Turtle de la ressource DBpedia. Que contient la ligne 14 ?
Solution
b) Parcourir le graphe de données DBpedia
Le 3 juin 1950 Maurice Herzog et Louis Lachenal réussirent la première ascencion de l'Annapurna. Parmis les alpinistes qui participèrent à l'expédition ayant permis cette victoire se trouve Jean Couzy. Lui même a été le vainqueur de plusieurs sommets de l'Himalaya, mais savez-vous lesquels ? A quelles dates ? Et avec qui ?
Question 1: Faites une recherche sur le web pour trouver les réponses à ces questions.
Les informations précédentes sont présentes dans Wikipedia et ont été extraites pour être intégrées au graphe de données de DBpedia. On pourrait facilement les retrouver à l'aide d'une simple requête SPARQL, mais pour le moment nous allons nous contenter de les obtenir en parcourant manuellement DBpedia
Question 2: En partant de la ressource représentant Jean Couzy dans DBpedia retrouvez les informations de la question 1. Dessinez le graphe présentant les resources de DBpedia que vous avez parcourues et les prédicats les reliant.
SolutionDans vos réponses aux questions précédentes vous avez certainement du trouver le Makalu qui se situe dans l'Himalaya, à la frontière entre le Tibet (zone autonome Chinoise) et le Népal. Mais savez-vous dans laquelle des quatorze zones administratives* de ce pays se trouve le versant népalais de ce sommet ? Et quelle est la capitale de cette région ?
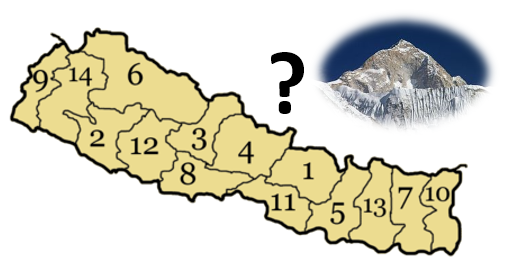
Question 3: Toujours en explorant le graphe RDF de DBpedia répondez à ces questions (région administrative où se trouve le versant népalais du Makalu et capitale de celle-ci) et complétez le dessin de votre graphe RDF.
Ces données ne sont pas directement dans le graphe DBpedia, mais dans un autre graphe de données auquel DBpedia est lié : Wikidata.
Wikidata is a free and open knowledge base that can be read and edited by both humans and machines. Wikidata acts as central storage for the structured data of its Wikimedia sister projects including Wikipedia, Wikivoyage, Wikisource, and others. Wikidata also provides support to many other sites and services beyond just Wikimedia projects! The content of Wikidata is available under a free license, exported using standard formats, and can be interlinked to other open data sets on the linked data web. http://www.wikidata.org
Les ressources DBpedia sont reliées aux ressources Wikidata par un lien owl:sameAs
Pouvez-vous trouver des sommets proches du Makalu ? Par exemple pourriez-vous nommer ces 4 sommets ?

Question 4: Toujours en vous servant des données DBpedia répondez à cette question.
Ces données ne sont pas directement dans le graphe DBpedia, mais dans un autre graphe de données issus du gazeeter open source Geonames.
GeoNames est une base de données géographiques gratuite et accessible par Internet sous une licence Creative Commons. L'interface est de type wiki et les utilisateurs peuvent ajouter des données, les améliorer ou corriger les données présentes.
La base de données1 contient plus de 8 millions de noms géographiques qui correspondent à plus de 6,5 millions de lieux existants. Ces noms sont classés en 9 catégories et 645 sous-catégories. Des données comme la latitude, la longitude, l'altitude, la population, la subdivision administrative, le code postal sont disponibles en plusieurs langues pour chaque emplacement. https://fr.wikipedia.org/wiki/GeoNames
Les ressources DBpedia sont reliées aux ressources issues de GeoNames par un lien owl:sameAs.
Dans DBpedia, ces ressources sont identifiées par des URI préfixées par le préfixe geodata:.
La video ci-dessous vous montre comment accéder aux données geonames depuis DBpedia.
Exercice 2: Le langage Turtle
Parmi les nombreux langages de sérialisation de RDF (N-Triple, RDF/XML, JSON-LD, ....), il est important de connaître Turtle, ceci pour plusieurs raisons:
- C'est un format concis et lisible, relativement facile à manipuler (éditer) comparativement aux autres formats de sérialisation du RDF,
- La syntaxe du langage SPARQL utilisé pour interroger des jeux de données RDF est basée sur Turtle pour représenter des motifs de graphes (graph patterns). Connaître Turtle vous facilitera donc l'apprentissage de SPARQL.
2.1 Lire du Turtle
Soit le fichier Turtle suivant :
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dbr: <http://dbpedia.org/resource/> .
@prefix geodata: <http://sws.geonames.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix schema: <http://schema.org/> .
@prefix ex: <http://example.net/people#> .
ex:Amelie_Ponet a foaf:Person ;
foaf:givenname "Amélie";
foaf:familyName "Ponet";
foaf:knows ex:Ivan_Noe.
ex:Ivan_Noe a foaf:Person, schema:Person ;
foaf:givenname "Ivan", "Iván"@hu ;
foaf:familyName "Noe" ;
foaf:birthday "1985-02-24"^^xsd:date ;
schema:address [ a schema:Address ;
schema:addressLocality "Grenoble" ;
schema:url dbr:Grenoble;
rdfs:seeAlso geodata:3014728
] ;
foaf:knows ex:Amelie_Ponet,
<https://www.w3.org/People/Berners-Lee/card#i> .Ce fichier décrit des personnes en utilisant en particulier les vocabulaires FOAF (Friend Of A Friend) et schema.org.
Question 1 : à quelles URIs correspondent foaf:Person et schema:Person ?
Tapez ces URIs dans votre navigateur. Que se passe-t-il ?
Pouvez vous obtenir un représentation RDF de ces ressources ?
Pour obtenir du RDF il faut utiliser la négociation de contenu en spécifiant dans les en-têtes Accept de la requête HTTP GET
un type MIME correspondant à du RDF : application/xml+rdf pour obtenir du code RDF/XML ou bien
text/turtle pour du code Turtle. Vous pouvez effectuer ces requêtes depuis la ligne de commande avec wget
ou curl (voir slide 22 du cours n°2 URIs).
Question 2 : donnez une représentation graphique du graphe RDF défini par le fichier turtle ci-dessus.
Solution à ne regarder qu'après avoir essayé de produire votre propre solution.
2.2 Ecrire du Turtle
Le graphe ci-dessous représente des données extraites du graphe de connaissances DBpedia concernant le chanteur/compositeur britannique Joe Strummer.
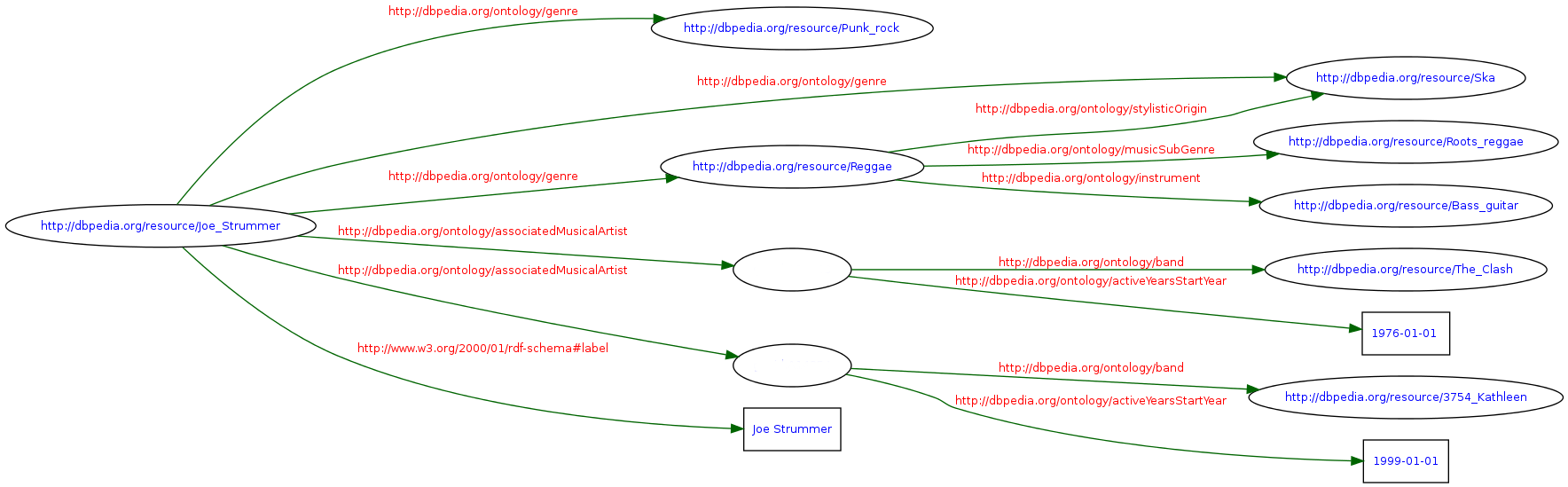
Question : écrivez une représentation de ce graphe en Turtle et vérifiez que celle-ci est syntaxiquement corrrecte.
Pour effectuer cette validation, vous pouvez utiliser soit des outils en ligne soit des outils en ligne de commande. Parmi ceux-ci en voici quelques uns :
- Outils en ligne.
- IDLab Turtle Validator basé sur le package NodeJS TurtleValidator.
- RDF Translator, outil de conversion pour les différents format de sérialisaton de RDF (Turtle, RDF/XML, RDFa....) basé sur la bibliothèque Python RDFLib.
- EASYRdf Converter, outil de conversion similaire à RDF Translator basé sur la librairie PHP EASYRDF
- Outils en ligne de commande.
- TurtleValidator : validateur écrit en JavaScript (NodeJS).
-
Le framework Java Jena de la fondation
Apache, en particulier les outils
en ligne de commande permettant lire et écrire des fichiers RDF.
Vous pouvez vous reporter à ce document pour plus d'informations sur l'installation de Jena sur votre poste de travail.
Exercice 3: Modéliser en RDF
La table suivante montre un échantillon des données que la librairie ARTEMIS Bookstore conserve sur les livres qu'elle possède en stock. Ces données sont pour le moment stockées dans un tableur, il s'agit de les représenter en utilisant le modèle de données RDF.
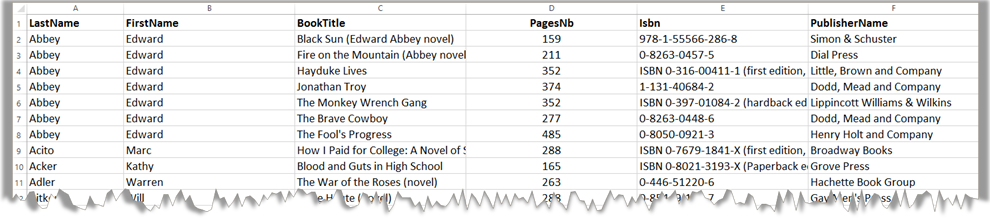
Question 1: dessinez un graphe RDF qui reflète le contenu de la table (vous ne vous intéresserez qu'aux données contenues dans les deux premières lignes de la table).
Pour les URIs vous pouvez utiliser les préfixes suivants:
-
http://www.artemisbokkstore.com/ontology#pour les ressources qui correspondent à une propriété ou une classe, -
http://www.artemisbokkstore.com/resource/pour les autres ressources.
Question 2: Créez un fichier texte artemis.ttl dans le lequel vous
écrirez une sérialisation de votre graphe en Turtle. Comme pour l'exercice 2.2 vérifiez que la syntaxe est correcte.
Exercice 4: Extraire des données RDFa
La page http://www.ebusiness-unibw.org/ de l'E-Business and Web Science Research Group de l'Université Militaire de Munich, contient des données structurées (décrites à l'aide de RDFa).
Question 1: Que contiennent ces données ? Représentez ces données en Turtle et dessinez le graphe RDF correspondant.
Vous pouvez bien entendu observer le code source de la page et produire manuellement le fichier turtle puis le graphe. Cependant de nombreux outils existent pour extraire le RDFa d'un document HTML et le convertir dans différents format. Pourquoi s'en priver ? Vous pouvez par exemple utiliser RDFa 1.1. Distiller and Parser ou des convertisseurs tels RDF Translator.
Question 2: Google search recommande d' utiliser JSON-LD plutôt que du RDFa pour annoter des documents web. Produisez une sérialisation en JSON-LD que vous pourriez subsituer au code RDFa dans la page http://www.ebusiness-unibw.org/ (pensez à utiliser un convertisseur pour produire la sérialisation en JSON-LD).
SolutionExercice 5 : Générer des données RDF.
Question 1: Ecrivez un programme Java qui lit le fichier CSV
artemisBookstoreData-v1.csv des données de la librairie
ArtemisBookstore vues à la question 1 de l'exercice 3 et produit un fichier RDF au format turtle
(artemisBookstoreData-v1.ttl).
Verfiez que votre fichier rdf en utilisant l'un des outils de validation vus dans les exercices précédants.
optionel: vous pouvez éventuellement modifier votre programme pour, lorsque vous parsez votre fichier,
créer un modèle RDF
avec l'API core de Jena et proposer une sortie dans différents
formats de sérialisation (RDF/XML, Turtle, JSON-LD...).
Pour vous aidez vous pouvez vous référer à l'introduction au framework Jena accessible depuis la page TPs du site web du cours.
Exercice 6 : Manipuler du RDF avec l'API Jena
Cet exercice est optionnel
Question 1: En utilisant l'API Jena Core ecrire un programme Java qui lit le fichier
RDF ((artemisBookstoreData-v1.ttl)) au format turtle que vous avez produit
à l'exercice précédent et qui étant donné le nom d'un auteur
trouve et affiche le titre de tous les livres dont il est l'auteur.