M2-SCCI Coding; Class project: CIRC Coder/Decoder
Topic: Implementing the Cross Interleaved Reed-Solomon Code of the audio CD.Students have to write 4 programs:
- Coder: encoding of a data file (of size, a multiple of 24 bytes):
using the CIRC algorithm
- Input: a file with arbitrary data;
- Output: a file encoded (of larger size)
- Decoder: decoding of the file, altered by a noise, using CIRC algorithm
- Input: the altered file
- Output: the file with corrected input data, or a message of failure.
- isolated errors (mechanic, physical default of the support, ...): occuring with low frequency (e.g. with probability lower than 1/10000).
- error bursts (scratches or dusts on the disk), characterized by their length and frequency; they affect several consecutive bytes.
Then, decompressing and help is obtain by: $ tar xvfz noise-generator.tgz ; cat noise-generator/ReadMe
The noise generator has the following specification:
- Input: the encoded file (on the standard input) and the options:
- -p <f1> where f1 is a float giving the probability of isolated errors
- -f <f2> where f2 is a float giving the frequency of error bursts
- -l <n3> where n3 is the maximal length of a burst (n3=0 for no burst)
- -d <n4> to force a burst at the position n4 of length n3
- -r for an arbitrary initialization of the random generator (default value: seed=0 deterministic)
- -v verbose mode
- -h
to display the help
- Output: the same file, perturbed with the noise (on the standard output)
$ bruiteur -p 0.01 -f 0.001 - l 100 < input_file > output_file
and to use it with the encoding/decoding:
$ CIRC_coding < test_file | noise-generator -p 0.01 -f 0.001 -l 100 | CIRC_decoding > output_file;
To test: use the program "diffbinfiles" comparing 2 binary files
$ diffbinfiles file1 file2
NB : you are free to modify/improve the noise-generator and adapt it to your experimenations by adding new options for example. But you have to leave the existing options unchanged (they will be used for the tests).
Work assignment (in groups of 2 students):
- Implement the CIRC block coder-decoder: using the same encoding as for the audio CDs
- Perform experiments with several noise configurations and compare the two
systems
- Check the isolated error correction capabilities
- Estimate experiementally the size (in bits) of an error burst, where the decoding become incorrect or impossible.
- Compare the computation time of coding and decoding (using a same file)
- Report: to be returned on or before Wednesday 14, March, by e-mail to clement.pernet@imag.fr:
- A directory containing the source code of the programs and the makefile (gcc / g++)
- a 2-3 pages report (as a pdf file). 3 pages max if it includes graphs:
- Student names
- Summary of the specificities of the implementation (technicalities/personal choices during the implementation, ...)
- Presentation of the experimental results (tables, graphs)
Informations on how to create a CIRC coder/decoder
Below are usefull informations: base field, generating matrices for the codes, taken from [1]. Additional material can be found in [3].- The Field F256 : addition/multiplication/division tables.
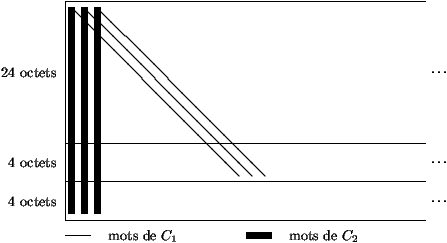
- The codes C1 and C2 Generating matrices
- Interleaved Coder/Decoder CIRC
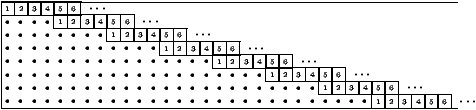
Decoding . the decoding of table in Figure 2 is first done column-wise, using a decoder for C2 correcting 1 error. If the column is not a word in C2 and the correction fail, the 28 symbols returned by the decoder are marked as erased. From the 109-ith decoded column, we begin to decode the diagonals (with delay 4), using a decoder for C1 fixing 4 erasing or less. In particular, this implies that the decoder of C1 will also receive the positions of erasing, together with the word to be decoded.
Références. This project is directly inspired by a project from Nicolas Sendrier [1]. The report [2] gives a more detailed description of the audio CD encoding. The page [3] enumerates several C/C++ programs for coding/decoding.
- [1] "Codeur/Décodeur du code CIRC du disque compact"; TP proposé par Nicolas Sendrier http://www.enseignement.polytechnique.fr/profs/informatique/Nicolas.Sendrier/X98/projet/ .
- [2] Codage d'un signal audio-numérique. Jean-Pierre Zanotti, Rapport de recherche INRIA n.3333, projet CODES.
- [3] http://www.eccpage.com/ Programmes C/C++ réalisant le codage et le décodage de différents codes correcteurs.
- [4] Reed-Solomon Codes and CD Encoding, Stan Hanley, David Joyner, SM4864001, 24 Avril 2002
- [5] http://www.cdpage.com/dstuff/BobDana296.html
- [6] http://www.ee.washington.edu/conselec/CE/kuhn/cdmulti/95x7/iec908.htm Format des CD - RW et standard IEC908 (avec dessin)
- [7] Info Cabouyt CD-ROMs