Chapitre I Contexte de la recherche et problèmes abordés (32 p.)
Après avoir retracé l'évolution des idées en lexicographie computationnelle de 1980 à 2012, en nous limitant à ses aspects liés aux recherches en TA et TAO (Traduction Assistée par Ordinateur), nous présentons l'état du domaine au début de notre thèse, et les problèmes importants et actuels à l'époque. À partir de là, et du contexte mixte (université-industrie) dans lequel se plaçait notre thèse, nous dégageons les thèmes de recherche qui nous ont paru les plus intéressants, et sur lesquels nous avons principalement travaillé.
I.1 Évolution des idées de 1980 à 2012 (18 p.)
I.1.1 1980— : approches visant à faire le lien entre dictionnaires pour les systèmes de TA et pour les humains
I.1.1.1 "Ouverture" des dictionnaires de TA aux traducteurs (1 p.)
Par rapport aux dictionnaires de TA internes et invisibles, comment "ouvrir" ou "rendre accessibles" les dictionnaires de TA aux vrais utilisateurs, et pas seulement aux développeurs de systèmes de TA, est la première étape d'interaction pour les humains.
Visulex pour Ariane-G5 (1982). Le système Ariane-G5 [Guillaume, P., 1989 ; Boitet, C., 1990] est un environnement de développement pour la TAO. Un linguiste peut créer un système de TA en Ariane-G5 sans compétences en informatique. Un système de TA sous Ariane-G5 peut avoir jusqu'à 56 fichiers[1] de dictionnaires pour un couple de langues. Chaque fichier de dictionnaire contient un type d'information, et utilise des codes ("formats" ou "conditions") définis dans d'autres fichiers. Pour rendre accessibles ces dictionnaires de TA aux traducteurs, on a construit le système Visulex [Bachut, D. & Verastegui, N., 1984] en 1981-1982. C'est un outil qui permet de visualiser synthétiquement les informations lexicales d'un système de TA développé en Ariane-G5. Pour chaque unité lexicale (UL) sélectionnée, Visulex cherche toutes les informations relatives. Il produit une "vue double" de la BDLex de ce système de TA, avec en regard les codes (des variables, des formats et des dictionnaires), et leurs commentaires.
ConverserForHealthcare (Spoken Translation Inc.). La société Spoken Translation Inc. a été créée par Mark Seligman en 1998 [Boitet, C. et al., 2009]. ConverserForHealthcare est un logiciel de TA anglais↔espagnol pour le domaine de la santé, pour les communications orales entre le personnel médical et les patients et leurs familles. Comme on a vraiment besoin de désambiguïsation lexicale, il faut rendre compréhensibles intuitivement les sens distingués dans les dictionnaires du système de TA utilisé de façon interne et codés (par des conditions sur des attributs syntaxiques et sémantiques). On le fait via des "gloses", des définitions ou des icônes.
Idée guide 1 Établir et maintenir des correspondances étroites entre informations lexicales formelles (codées) et "naturelles" (exprimées en termes usuels).
Définition 1. Les informations lexicales formelles sont définies de manière "exacte" (ex. respecter certaines règles syntaxiques), et sont compréhensibles/lisibles par les machines.
Définition 2. Au contraire des informations lexicales formelles, les informations lexicales naturelles sont définies de manière usuelle, en langue naturelle, et sont orientées vers les humains.
I.1.1.2 Intégration des dictionnaires des traducteurs dans des aides à la traduction (1,75 p.)
Dictionnaires "main gauche" ("shoe box"). En 1982, Alan K. Melby (BYU, Brigham Young University) a implémenté une intégration de dictionnaires personnels "main gauche" sur les premiers micro-ordinateurs [Melby, A., 1989]. Cette aide dictionnairique était couplée très simplement à l'interface de traduction[2]. On pouvait consulter les dictionnaires en faisant un "copier/coller" d'un mot. Melby considérait cette fonction comme un support "pur" de premier niveau.
TansActive d'ALPS (Utah). Ce système a été créé par le groupe linguistique de BYU en 1980. C'est un des premiers systèmes de TA interactifs sur PC (sous CP/M). Il a une fonction de consultation des mots dans un dictionnaire bilingue pour un texte en cours de traduction. Cette fonction est accessible dans un panneau de dictionnaire en bas de l'interface de traduction. Si le mot n'est pas dans le dictionnaire, on peut aussi l'ajouter.
Système CAT de Weidner. Le système de TA de Weidner (Weidner Communications Corporation) a été créé en 1977 [Perscheid, M. M., 1985]. Il y a deux versions : une version mono-utilisateur, appelée MicroCAT, et une version pour plusieurs utilisateurs collaboratifs, appelée MacroCAT. Ce système permet la gestion de dictionnaires à distance. Une fois les textes sources entrés dans le système, celui-ci compare le résultat d'analyse morphologique de ce texte avec ses dictionnaires. Si certains mots ne sont pas dans les dictionnaires, le système les envoie aux terminologues ou aux lexicographes pour compléter leurs dictionnaires au fur à mesure du processus de traduction. Ce système permet aussi aux traducteurs, de contribuer aux dictionnaires.
TM/2.
TranslationManager/2 ou TM/2 [TM/2, 1992]
est un système d'aide à la traduction utilisé par IBM. Il a été conçu un peu avant 1990 pour la plate-forme OS/2. Ce système utilise une mémoire de
traductions en réseau pour faciliter la réutilisation des traductions
existantes. Il supporte des dictionnaires préparés, ainsi que la création de
dictionnaires à la volée ou en mode batch. Les dictionnaires externes en format
SGML peuvent aussi être intégrés dans TM/2. Comme la
plupart des utilisateurs ont besoin de leurs propres dictionnaires, et comme ces
dictionnaires sont beaucoup plus adaptés à leurs exigences, IBM avait prévu de
fournir ce service comme un service local. En 2002[3], IBM l'a retiré de la commercialisation,
mais il a toujours été et est encore utilisé pour faire les traductions
internes d'IBM, non seulement par les employés d'IBM, mais aussi par les
agences de traduction externes et les traducteurs à temps partiel travaillant
pour IBM. En 2010, TM/2 a été mis en source ouvert[4]
et a été renommé OpenTM/2[5].
PAHO. PAHO (Pan American Health Organization) a commencé à créer ses systèmes de TA en 1980 pour le couple de langues anglais-espagnol [Vasconcellos, M. & León, M., 1985]. Les premiers systèmes (1980-1985) furent Spanam (espagnol→anglais), puis Engspan (anglais→espagnol). Beaucoup plus tard, on intégra le portugais (anglais↔portugais en juillet 2003, et espagnol↔portugais en mars 2004). Ces systèmes permettent d'importer de nouveaux termes non traduits dans les dictionnaires des systèmes de TA grâce à un outil de fusion de dictionnaires après les retours des traducteurs. C'est un des premiers systèmes reliant effectivement les dictionnaires de TA et les dictionnaires pour traducteurs.
I.1.1.3 Prototypage de dictionnaires intégrant les deux aspects (0,5 p.)
Dictionnaires furcoïdes. Les dictionnaires furcoïdes ou multicible[6] [Boitet, C. & Nedobejkine, N., 1986] sont des dictionnaires avec une seule langue source et plusieurs langues cibles. L'indexage (voir la Définition 3) des entrées source vers les entrées cible est monodirectionnel. En 1986-91, le GETA a construit trois dictionnaires bicible dans le domaine des télécommunications, pour le français, l'anglais et le japonais, durant le contrat DGT-KDD-GETA-Champollion. Ces dictionnaires ont été implémentés en Prolog[7] avec le SGBD (système de gestion de base de données) du commerce CLIO.
Définition 3. L'indexage d'une entrée source vers des entrées cible consiste à associer aux traductions possibles des conditions sur l'occurrence de l'entrée dans le contexte syntaxique ou sémantique permettant de les choisir.
Par exemple, "manquer: X ~ de Y → X lacks Y; X ~ à Y: X misses Y", ou "prix (achat) → price; ~ (récompense) → prize", ou "layer (gen.) → couche; ~ (PAO) calque".
EuroLang Optimizer. EuroLang Optimizer [Brace, C., 1994] est un outil d'aide à la traduction pour six langues sources et vers onze langues européennes cibles, réalisé dans le cadre du projet européen Eureka Eurolang, et présenté en 1994 par SITE/Eurolang (une filiale de iTEP/Sonovision). Cet outil est intégrable dans Microsoft Word, Framemaker et Interleaf comme un plugin et peut prétraduire un nouveau document en utilisant une mémoire de traductions et une base de données terminologiques sur serveur. Si le système ne trouve pas de résultat, il appelle un système de TA (on avait choisi LogosTM). Le résultat fusionné est un document coloré, dans lequel les différentes couleurs représentent les correspondances parfaites (exact matches), les correspondances floues (fuzzy matches), les termes techniques connus, et les traductions obtenues par TA. Mais la société Site/Eurolang a arrêté ce système en 1995 après avoir perdu un appel d'offres de la CEE face à Trados.
I.1.1.4 Exemples de "bonnes pratiques" et de "cercles vertueux" (1 p.)
PAHOMTS. Nous avons déjà mentionné au I.1.1.2 PAHOMTS, le système de TA de la PAHO (Pan American Health Organization), entre l'anglais, l'espagnol et le portugais, basé sur l'approche transfert. Ce système est développé par des linguistes informaticiens et des traducteurs de PAHO TR (Translations Services unit), et est utilisé pour traiter plus de 90% des traductions quotidiennes [Aymerich, J. & Camelo, H., 2009] (4,5 millions de mots par an en moyenne). Grâce à sa fonction d'import de nouveaux mots par un outil de fusion de dictionnaires après les retours de traducteurs, chaque dictionnaire contient aujourd'hui plus de 150.000 mots, locutions, et règles contextuelles, dans sa dernière version 4.11, sortie en décembre 2014.
BehaviorTran. C'est
un système de TA (anglais↔chinois) basé sur des règles de transfert, écrit en
C, et développé par la NTHU
(National Tsing Hua University, Taiwan) et Behavior Design Corporation à partir de 1985 [Hsu,
Y.-L. U. & Su, K.-Y., 1997]. Il a commencé à être utilisé
pour un service commercial en juillet 1989. Pour ses
dictionnaires, il y a six niveaux différents : (1) dictionnaire général, (2)
dictionnaire général de tournures connexes (ex. in order to), (3) dictionnaire de
tournures non connexes (ex. turn…on), (4) dictionnaire spécialisé, (5)
dictionnaire du client, (6) dictionnaire du projet. S'il y a plusieurs entrées trouvées dans des
dictionnaires différents, le système utilise un ordre de priorité : le
dictionnaire du projet a la plus haute priorité, puis le dictionnaire du
client, ensuite le dictionnaire spécialisé, et enfin le dictionnaire général.
Pensée, Yakushite.net (Oki
Electric). Pensée [Shimohata, S. et
al., 1999], un
système de TA japonais↔anglais, a été commercialisé en 1986 pour la partie japonais→anglais et en 1988 pour la partie anglais→japonais. Sa version Web, Yakushite.net
[Murata, T. et al., 2003] permet de contribuer avec des termes ou des
schémas liés à des termes. C'est un des
premiers systèmes de TAO intégrant directement une contribution lexicale
humaine aux ressources lexicales utilisées par un système de TA. Ces données
lexicales sont enregistrées dans une base lexicale, et ces dictionnaires
peuvent être intégrés directement dans le système Pensée après une validation manuelle.
Systèmes de TA et THAM et leurs liaisons. Dans certains cas[8], les traductions par les mémoires de traductions
sont bien adaptées. Dans d'autres cas[9], les traductions automatiques sont bien adaptées.
Enfin, dans certaines situations[10], la traduction humaine est la seule bonne méthode.
Il y a beaucoup de sociétés qui ont cherché à utiliser à la fois les systèmes
de TA et de THAM, mais sans les intégrer au niveau des ressources lexicales. Par
exemple, chez IBM, TM/2TM puis OpenTM/2TM est couplé avec LMT[11], chez EuroLang, EuroLang
Optimizer est couplé avec LogosTM. Les deux
systèmes sont indépendants et ont très peu de liaison.
Le manque d'intégration entre ces deux systèmes est mauvais du
point de vue économique [Boitet, C., 1996], et aussi pour les traducteurs, du point de vue du
dictionnaire. En effet, les traducteurs peuvent faire évoluer les dictionnaires
de THAM, mais pas les dictionnaires de TA. Donc, les résultats de la TA perdent
leur cohérence terminologique avec les dictionnaires de THAM.
Idée guide 2 Pour les dictionnaires,
la plus grande difficulté est l'incohérence entre les dictionnaires pour
traducteurs, les dictionnaires pour humains, et les dictionnaires pour la TA.
Idée guide 3. Sans bonne liaison, ou mieux intégration, entre informations lexicales formelles[12] et naturelles[13], elles ne peuvent pas rester cohérentes, et les unes ou les autres deviennent de moins en moins utiles dans les applications impliquant une synergie homme-machine.
I.1.2 1985— : tentatives pour unifier les informations générales et terminologiques (1 p.)
BDTAO. Les chercheurs du GETA ont étudié comment
centraliser tous les types d'information
lexicale dans une base lexicale dès 1986 [Boitet, C. &
Nedobejkine, N., 1986]. La société B'VITAL a
construit son système industriel BV/aéro/F-E et sa BDLex BDTAO en
1987. Concrètement, elle a fusionné les dictionnaires
généraux monolingues et les dictionnaires terminologiques de systèmes de TA
écrits en Ariane-G5 dans une
BDLex. Elle a ensuite construit (par programme) les dictionnaires du système de
TA (ici écrit en Ariane) à partir de cette BDLex.
BDTAO a été conçue
spécifiquement pour les systèmes de TA, et indépendamment d'un système particulier. Cette méthode a eu un
succès partiel : on arrivait à produire tous les dictionnaires des systèmes
de TA de type Ariane-G5, sauf
les dictionnaires de transfert lexical des unités lexicales générales. C'est le premier système commun de gestion de BDLex
et il a été utilisé dans plusieurs systèmes de TA.
Ontoterminologie. Le néologisme
"ontoterminologie" a été introduit en 2007 par Christophe Roche [Roche,
C., 2007]. En fait, ce concept a été
défini sous d'autres
noms et utilisé en TA bien avant. C'est en effet une des bases de l'approche "KBMT" (Knowledge-based
MT) introduite dans KBMT-89 à CMU (Carnegie Mellon University) [Nirenburg,
S. & Defrise, C., 1990], puis déployée dans KANT et
CATALYST pour Caterpillar [Mitamura,
T. & Nyberg, E., 1992].
Définition 4. La terminologie [ISO 1087-1] est définie comme "l'étude scientifique des notions et des termes en usage dans les langues de spécialité".
Définition 5. Une ontologie (informatique)[14] est un ensemble structuré de termes et de concepts représentant les sens d'un champ d'informations, que ce soit par les métadonnées d'un espace de noms, ou par les éléments d'un domaine de connaissances. L'ontologie constitue en soi un modèle de données représentatif d'un ensemble de concepts dans un domaine, ainsi que des relations entre ces concepts.
Définition 6. Une ontoterminologie [Roche, C., 2007] est une terminologie dont le système notionnel est une ontologie formelle.
Ch. Roche insiste sur l'importance des principes épistémologiques qui président à la conceptualisation du modèle — c'est l'ontologie dans sa définition première. Il insiste également sur la nécessité d'une approche scientifique de la terminologie où l'expert joue un rôle fondamental — c'est l'ontologie dans ses définitions plus récentes où la logique et les langages de représentation des connaissances tiennent une place prépondérante. Enfin, une ontoterminologie met en relation le modèle conceptuel et les termes (d'usage ou normés) qui en parlent, tout en distinguant les définitions formelles des concepts (spécifications logiques) des définitions en langue naturelle des termes (explications linguistiques).
Conclusion
Idée guide 4. L'unification des informations
lexicales générales et des terminologies est un besoin réel pour les systèmes
de TA et THAM, et a été réalisée dès 1992 par le système opérationnel KANT/CATALYST
basé sur KBMT-89.
I.1.3 1992— : dictionnairique avec évolution vers les réseaux et le contributif (8,25 p.)
I.1.3.1 1992— : travaux sur la construction de dictionnaires informatisés (5,25 p.)
I.1.3.1.1 Le FeM (3 p.)
Cette section est largement reprise d'une présentation de Ch. Boitet, directeur du projet.
a. Lancement du projet
Le FeM [Gaschler, J. & Lafourcade, M., 1994] est un dictionnaire monodirectionnel trilingue (français vers anglais et malais). Le but de ce projet était la création d'un dictionnaire français→malais informatisé et papier, mais on y a ajouté l'anglais, qui avait servi de "pont" initial. Il a été lancé en coopération entre le service Culturel de l'Ambassade de France à Kuala Lumpur, le Dewan Bahasa dan Pustaka (l'Institut de Langue et de Littérature, Malaisie), l'Universiti Sains Malaysia et l'équipe GETA avec l'association Champollion.
b. Structure du dictionnaire
On développa d'abord une version 0 avec une structure de dictionnaire en séquence : français-anglais et anglais-malais. Des problèmes apparurent rapidement. Chaque sens en français était souvent traduit en 2 ou 3 sens en anglais, chaque sens en anglais était éventuellement traduit en 1 ou 2 sens en malais. Quand on créa le dictionnaire français-malais en supprimant l'anglais, des doublons apparurent dans le dictionnaire.
On modifia ensuite la structure des entrées pour qu'elles mènent parallèlement et non plus en séquence du français à l'anglais et du français au malais. Le dictionnaire devint donc "furcoïde" (voir I.1.1.3). Puis on ajouta le thaï en 1997 [Lafourcade, M., 1997] et le vietnamien fin 1998. On réalisa également une version "glossaire informatique" du FeM. Voici un exemple d'un article du dictionnaire FeM.
|
|
|
|
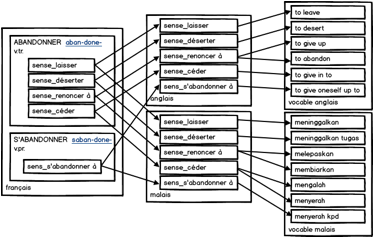

Figure 1 : Exemple de structure "furcoïde" d'un article du dictionnaire FeM
c. Méthode de construction du dictionnaire
La première méthode de construction a été proposée et
implémentée par Ch. Boitet à Penang en 1991 en une semaine environ. C'était une
BD en 4D[15]
avec les interfaces en français, anglais et malais. Mais 4D ne fonctionnait que
sur Mac, et pas sur Windows, ce qui ne convenait pas aux lexicographes de l'UTMK[16]
(Universiti Sains Malaysia, Penang). D'autre part,
l'interface "BD" avec une fiche par
mot ne convenait pas pour les articles "généraux" à structure
complexe.
Voyant cela, il proposa et mit en place 2 semaines plus tard l'utilisation de Microsoft WordTM comme "éditeur pseudo-syntaxique", pour plusieurs raisons : (1) il fonctionnait sur Mac et sur PC, (2) les lexicographes le connaissaient déjà, (3) il était déjà installé sur toutes les machines, (4) pour les traitements informatiques, on pouvait travailler sur des fichiers RTF (Rich Text Format) équivalents. La méthode consiste à prédéfinir des styles (de paragraphe) particuliers pour les éléments logiques (mot-vedette, prononciation etc.). Il est ensuite assez facile d'analyser les fichiers RTF et d'importer le contenu dans une base de données (Postgres).
En pratique, la construction du FeM a consisté à travailler en pipeline sur une trentaine de fichiers (1 ou 2 par lettre initiale), puis à consolider le tout dans la BDLex. Ensuite, on a produit à partir de la BDLex (1) les fichiers Word, un par lettre, utilisés pour "remplir" les gabarits PageMaker du dictionnaire papier final, et (2) les données des outils informatiques de consultation.
d.
Consultation du FeM :
version imprimée et versions électroniques
En 1996. La première version de l'outil ALEX 1.0, développée par M. Lafourcade [Lafourcade, M., 1996] a été livrée en mai 1996. Cet outil permettait non seulement la consultation par les entrées, mais aussi par le contenu des articles. Il permettait également de filtrer les informations, de les trier et de les compter, etc. Mais cet outil, programmé en MCL (Macintosh Common Lisp), ne fonctionnait que sur Mac.
Une version électronique en Microsoft
WinHelp a été développée pour Windows (par Ee Churn, une informaticienne
de l'UTMK). C'est une version basique de consultation.
Une version imprimée (le dictionnaire français-malais "Kamus Perancis-Melayu Dewan") a été publiée à Kuala Lumpur [Gut, Y. et al., 1996] en juillet 1996. Dans ce dictionnaire, on a supprimé l'anglais et bien révisé et complété le malais avec l'aide de spécialistes.
En 1998. L'anglais a été complété par P. Lafourcade. Pour cette version, G. Sérasset a développé une application en Java. Cette application fonctionne sur tous les systèmes, mais ne permet que la consultation.
Vers 1999-2000. M. Lafourcade a développé une version sur Internet, wALEX.
En 2003. La partie malaise des entrées a été révisée encore une fois, cette fois-ci non pas par le DBP, mais par L. Metzger et la Maison du Monde Malais (MMM, La Rochelle), et on a intégré cette version dans la BDLex du projet Papillon.
I.1.3.1.2 Informatisation du DEC
Le dictionnaire DEC (Dictionnaire Explicatif et Combinatoire) [Mel'tchuk, I., 1992] est un dictionnaire très complexe. En novembre 1994, dans le cadre d'une collaboration post-doctorale avec le RALI (UdM)[17] et l'OLST[18], Gilles Sérasset a défini un projet visant à informatiser le DEC et à mettre à disposition des lexicologues des outils simplifiant la création d'articles du DEC [Sérasset, G., 1996]. Ce projet a été mené à bien durant plusieurs séjours d'été à Montréal.
Il y avait une version disponible sous forme de fichiers Word correspondant à la version imprimée du DEC. Hai Doan-Nguyen a participé avec son outil RECUPDIC[19] à la récupération de ces ressources lexicales [Doan-Nguyen, H., 1998b]. En fait, il a fait cette opération deux fois. La première fois, en 1995, il a travaillé sur la forme RTF, comme M. Lafourcade l'avait fait pour le FeM. Il a donc écrit en H-grammar un premier "récupérateur" travaillant sur cette forme, et produisant une représentation des articles comme des objets Common Lisp (LISPO). Ça a marché moyennement bien, car la forme RTF était trop compliquée, avec des balises parasites[20] qu'il a passé beaucoup de temps à corriger.
La seconde fois, en 1996, il l'a récupéré avec une approche différente, qui s'est révélée nettement plus efficace et plus rapide. Il a d'abord utilisé une macro VisualBasic pour transformer et normaliser le fichier, de façon à ce qu'il ne contienne plus que des caractères normaux (ISO-646). Par exemple, il a marqué les définitions avec §§D, les chaînes en indice par #[d et #]d, et de façon similaire les chaîne en gras, en exposant, les symboles spéciaux, etc. À ce point, il a fini la normalisation à la main, bien plus rapidement que sur du RTF. Il a écrit en H-grammar un nouveau récupérateur, beaucoup plus simple, travaillant sur cette forme normalisée en texte brut, et obtenu un résultat un peu meilleur que la première fois, et beaucoup plus vite. Il a enfin utilisé PRODUCDIC[21] pour convertir le dictionnaire récupéré vers le format de DECID.
DECID est un véritable éditeur spécialisé, créé par G. Sérasset, et écrit lui aussi en Common Lisp[22] [Sérasset, G., 1996]. L'interface de DECID est directement inspirée de la version papier du DEC. Cet éditeur, facile à utiliser, et par construction très bien adapté au DEC, a servi plusieurs années à l'OSLT.
I.1.3.1.3 Problème de l'asymétrie et introduction de quelques termes
Pour tous les types
de dictionnaire de traduction (Définition 7), il y a un
problème qui n'a jamais été résolu. C'est le problème de la non-symétrie :
on ne peut pas inverser la source et la cible d'un volume
(Définition 8) pour obtenir un nouveau volume de même
qualité allant de la langue cible vers la langue source. Le problème vient de la
différence de niveau d'information entre source et cible(s). Cela crée un "bruit" énorme, que ce
soit en inversion (ex. fr→zh├ zh→fr) ou en composition
(ex : fr→en + en→my├ fr→my).
Définition 7. Un dictionnaire de traduction est composé d'un ou plusieurs volumes, chacun relatif à une des langues considérées.
Définition
8.
Un volume d'un dictionnaire est un
ensemble d'articles, accédés par des mots-vedettes (lemmes en général), décrivant
des mots d'une même langue. Un article d'un dictionnaire de traduction contient
les traductions du mot identifié dans la ou les langues cibles considérées.
Définition 9. Un article de dictionnaire comporte au moins le mot-vedette, et le plus souvent d'autres informations (prononciation, classe grammaticale, définition, gloses identifiant des sens, ou lexies, exemples, etc.), ainsi que des traductions s'il s'agit d'un dictionnaire de traduction.
Idée
guide 5. La non-symétrie des dictionnaires
de traduction classiques est une difficulté majeure.
I.1.3.1.4 Travaux de MSR[23] (équipe venant d'IBM)[24] (2 p.)
En 1978, Gorges Heidorn du groupe d'IBM de Yorktown-Heights créa le langage spécialisé PLNLP (Programming Language for Natural Language Processing), à l'aide duquel le groupe construisit une grammaire de l'anglais extraordinairement couvrante pour l'époque, PEG (PLNLP English Grammar) [Jensen, K., 1986][25]. La grammaire PEG a été utilisée dans les systèmes EPISTLE puis CRITIQUE destinés à la correction orthographique, grammaticale, terminologique, phraséologique et stylistique, pour les documents d'IBM. En parallèle, cette équipe a mené un projet de longue haleine avec l'université de Lancaster pour la production d'un grand corpus arboré, le Lancaster/IBM Treebank. Les linguistes de Lancaster utilisaient un éditeur d'arbres pour choisir le meilleur arbre parmi les résultats de l'analyseur PEG.
Au début des années 80, ce groupe a aussi utilisé PEG pour développer avec IBM-Japon un système de TA vers le japonais, SHALT-1. Pour obtenir des structures logico-sémantiques rendant la traduction vers le japonais moins lourde, ils ajoutèrent à PEG un module supplémentaire, dit "relationnel". SHALT-1 a été utilisé (et l'est peut-être encore) pour traduire en interne les documentations techniques d'IBM, en enchaînant TA, post-édition et révision.
Au printemps 1991, tout ce groupe quitta IBM. S. Richardson, G. Heidorn, and K. Jensen (au moins) fondèrent le NLPG (Natural Language Processing Group) à Microsoft Research. Bill Dolan et Lucy Vanderwende y arrivèrent en 1992. Ezra Black rejoignit ATR (Nara, Japon) où il créa un nouvel analyseur qui fut la base du projet ATR/Lancaster Treebank[26]. Pour des raisons contractuelles, le groupe du NLPG dut attendre 4 ans avant de pouvoir travailler de nouveau sur l'analyse, la correction et la TA. Mais G. Heidorn créa dès 1992 G, une version améliorée de PLNLP.
En 1991, le tout nouveau NLPG commença à développer MindNet [Dolan, W. et al., 1993 ; Richardson, S. D. et al., 1998], une structure de données destinée à l'acquisition et au stockage de connaissances sémantiques, sur laquelle L. Vanderwende fit ensuite une bonne partie de sa recherche. Une des premières idées fut d'extraire les connaissances sémantiques des dictionnaires informatisés, et pour cela de commencer à les transformer en une base de connaissances lexicales. Il apparut que MindNet serait tout à fait adapté. MSR se procura les droits d'utilisation de la version électronique de l'AHD3 (American Heritage Dictionary, 3nd Edition), et le NLPG le transforma en un réseau lexical (de type réseau de Hopfield) implémenté en MindNet. Les nœuds correspondent aux divers éléments des articles (mot-vedette, glose, sens, définition…) et les arcs portent des poids positifs pour les attractions (par exemple entre une définition et les mots qu'elle contient) et négatifs pour les répulsions (par exemple entre deux sens séparés).
Pour désambiguïser les sens des mots apparaissant dans les définitions, K. Jensen écrivit en G un parseur des définitions du dictionnaire. Cela permit de lever la plupart des ambiguïtés syntaxiques (sur les parties du discours, ou POS). Pour la désambiguïsation sémantique, le NLPG utilisa un algorithme de type recuit simulé (simulated annealing), ce qui permit de relier chaque mot d'une définition au nœud représentant son sens dans le réseau.
Quand l'analyseur fut plus avancé et permit d'analyser des phrases complètes et plus seulement des définitions, cette méthode fut adaptée à la désambiguïsation lexicale de phrases, sous le nom de lexical priming (amorçage lexical). On analyse la phrase à traiter, on relie les nœuds lexicaux de l'arbre obtenu (une logical form) aux nœuds de ces mots dans le MindNet, ce qui l'étend temporairement, on les "chauffe", puis on laisse "refroidir". Les nœuds des sens (lexies) les plus probables dans le contexte de la phrase sont les plus "chauds" [Dolan, W. B. & Richardson, S. D., 1996].
Ensuite, le NLPG fit de même pour le LDOCE (Longman Dictionary of Contemporary English), et unifia ces deux dictionnaires dans un seul réseau lexical implémenté en MindNet.
À partir de 1996, le NLPG se mit à travailler sur la TA. Il développa des parseurs (dits plus tard "experts") et des générateurs en G pour 7 ou 8 autres langues. Pour le transfert, n'ayant pas de dictionnaires de traduction disponibles, ni d'outils pour écrire des transferts structuraux complexes, ses membres se tournèrent vers l'apprentissage automatique. En analysant les traductions de leurs documents techniques (faites par des professionnels), ils obtinrent de gros corpus d'arbres (dits logical forms, ou formes logiques) alignés, de type <LF_eng, LF_fra>, <LF_eng, LF_esp>, etc., à partir desquels on peut automatiquement apprendre la phase de transfert (lexical aussi bien que structural !).
Au moyen de calculs statistiques (information mutuelle, etc.), on compile, pour chaque paire de langues, une structure MindNet, dans laquelle sont stockés des morceaux des arbres source (arbrelets, ou treelets), auxquels sont associés les morceaux les plus probables de leur correspondant en langue cible.
Pour traduire une phrase, on l'analyse, on cherche (par un algorithme
de type Viterbi) une meilleure couverture de l'arbre obtenu, par des arbrelets
source, et on effectue une descente récursive de l'arbre source en construisant
un arbre cible avec les arbrelets cible. Si l'arbre cible obtenu n'est pas une
forme logique cible bien formée, on le corrige avec quelques règles ad hoc (expertes, donc). On utilise
ensuite le générateur de la langue cible et on obtient une traduction. Le
système de TA obtenu est donc hybride.
Entre 1998-2001, MSR présenta ce système à plusieurs reprises. Ensuite, comme Microsoft traduit vers au moins 45 langues et ne peut pas développer des analyseurs et générateurs couvrants et corrects pour tant de langues, le NLPG s'est tourné vers l'apprentissage direct des deux phases successives de transfert et de génération. On aligne donc chaque LF_eng avec la traduction correspondante, sous forme d'une suite de mots ou de vecteurs (liste de propriétés, dont le lemme, la classe, le nombre, le mode, le temps…). L'étape d'analyse reste experte (avec un choix probabiliste), ainsi que l'étape de génération morphologique (si on aligne avec des suites de vecteurs), et le "transfert descendant" est appris par des méthodes statistiques.
Notons pour finir que, dans tous les cas, on peut si on le souhaite intégrer dans le système un dictionnaire bilingue appris à partir des alignements, ou bien construit manuellement ou semi-automatiquement.
I.1.3.1.5 Versions électroniques de dictionnaires commerciaux (0,25 p.)
Il y a beaucoup de dictionnaires commerciaux (par exemple, Larousse, Petit Robert, Oxford etc.) qui ont été produits sous forme électronique à partir de bases de données. Ils sont construits, depuis près de 20 ans, en utilisant des outils d'exploration de grands corpus. Par exemple, à l'aide de concordanciers, les éditeurs des dictionnaires comme Collins, Longman, Larousse, etc. cherchent la fréquence des expressions et de leurs usages dans différents sens dans des corpus récents et variés [Monteleone, M., 2003].
Grâce à Internet, il y a beaucoup de dictionnaires consultables en ligne[27], par exemple, Reverso de Softissimo[28], Cambridge Dictionaries[29] etc., et plus récemment, sur les téléphones mobiles. Ces dictionnaires sont uniquement consultables, mais presque jamais téléchargeables[30]. Nous avons ajouté une liste de ressources informatisées et téléchargeables en annexe (Annexe 1).
I.1.3.2 1995 ou 1998 : vers la construction contributive de dictionnaires en ligne (3 p.)
Deux ou trois ans après la naissance d'Internet (début des années 1990), on a commencé à étudier les apports possibles des contributions en ligne à un dictionnaire.
I.1.3.2.1
Yakushite.net
(OKI electric) (0,5 p.)
Yakushite.net a été introduit au I.1.1.4. Le but de cet environnement est de faire construire les dictionnaires du système de TA Pensée de façon contributive par des traducteurs humains, via Internet. Les dictionnaires sont organisés de façon hiérarchique en dictionnaires et sous-dictionnaires.
Le service Web Yakushite.net a été mis en service le 18 septembre 2001. Toutes les fonctions sont directement intégrées dans le système Pensée grâce à un module spécial. Le service Web permet la traduction, la post-édition, la gestion de dictionnaires et la gestion de communautés (gestion des contributeurs, propagation des bulletins et service de FAQ) [Shimohata, S. et al., 1999].
|
Figure 2 : Architecture de Yakushite.net |
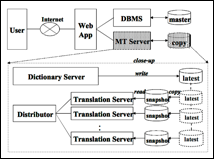
L'architecture de Yakushite.net est très intéressante. Il y a deux niveaux de dictionnaire : un SGBD
pour les utilisateurs, et un serveur spécial de dictionnaires pour le système
de TA Pensée. Voir la Figure 2. Après une contribution d'un contributeur, le résultat est stocké dans
les deux dictionnaires.
OKI a arrêté le service Web Yakushite.net en octobre 2014 à cause du manque de ressources financières. En effet, Yakushite.net était sponsorisé par une société de services de traduction, intéressée uniquement par certains domaines spécifiques. Après sa disparition, les services ont été arrêtés.
I.1.3.2.2
Projet UNL (0,75 p.)
En décembre 1996, le projet UNL fut lancé par l'IAS (Institute of Advanced Studies) de l'UNU (Université des Nations Unies) à Tokyo. Le directeur et concepteur d'UNL est Hiroshi Uchida. Le but de ce projet était de réaliser les communications multilingues pour que tout le monde puisse surmonter les barrières linguistiques à un horizon de 10 ans.
Il s'agit de développer un langage intermédiaire pivot, puis de traduire rapidement entre ce langage intermédiaire et chaque langue naturelle par un enconvertisseur et un déconvertisseur.
Les trois premières années (1997-1999) ont été utilisées pour finaliser les spécifications du langage intermédiaire UNL, faire des développements informatiques pour les 12 langues sélectionnées (arabe, chinois, espagnol, français, hindi, indonésien, italien, japonais, portugais, russe, swahili[31] et thaï) avec 14 partenaires, et, à cause de la présence à l'UNU d'un doctorant mongol, une étude seulement préliminaire pour le mongol. L'anglais servait de langue de travail. Le vocabulaire d'UNL est d'ailleurs volontairement basé sur l'anglais, mais il n'y avait pas de groupe UNL venant d'un pays anglophone. C'est le centre de Tokyo qui a le premier réalisé un déconvertisseur et un enconvertisseur de l'anglais. Le centre de Moscou (IPPI) en a ensuite réalisé une autre version dans ETAP-3, comme sous-produit de la construction du déconvertisseur et de l'enconvertisseur du russe.
En 2001, la fondation UNDL a été établie à Genève pour promouvoir l'application réelle d'UNL. Les outils EnCo et DeCo sont fournis par UNDL, pour créer les enconvertisseurs et déconvertisseurs. Plus précisément, pour chaque enconvertisseur et déconvertisseur, on a besoin d'un dictionnaire d'UW (Universal Words) ↔ LN (langue naturelle) et d'un ensemble de règles (écrites en EnCo et en DeCo).
Pour unifier la liste des UW, l'UNL-C (UNL Center, Tokyo) a développé l'outil UWGate. Cet outil permet de manipuler la BD des UW via Internet. Avec UWGate, on peut exporter un dictionnaire UW-LN vers un fichier ayant le format attendu par EnCo et DeCo. Il offre une application graphique sur Windows à distance, appelé UWGatePlus. Malheureusement, UWgate marchait mal. En fait, il était mal conçu (échanges seulement par courriel) et beaucoup trop lent (et assez souvent, on n'avait aucun retour).
Le GETALP a lancé en 2011 le projet GBDLex-UW++ dans le cadre du projet ANR Traouiéro et du consortium UNL++ (lui-même lancé en 2004 lors du colloque LREC à Lisbonne, en coopération avec l'IPPI (le centre de langue du russe) et l'UPM (le centre de langue de l'espagnol). Ce projet a pour but d'unifier les dictionnaires des UW de différents groupes (voir l'Annexe 2) et de construire pour de multiples usages une grande base lexicale multilingue (en au moins 4 langues et UNL). Nous le présenterons en détail au II.4.3.
I.1.3.2.3
Projet Papillon (1 p.)
On donne en Annexe 3 un historique assez détaillé du projet Papillon. Deux points importants sont qu'il a produit deux bases lexicales en ligne, de taille et d'ambition lexicologique très différentes, et que G. Sérasset et M. Mangeot en ont tiré une plate-forme générique de construction de BDLex multilingues en ligne, Jibiki.
La première base lexicale, Papillon-CDM, est une version opérationnelle depuis plus de 15 ans de la BDLex multilingue créée par M. Mangeot pour sa thèse vers 2000. Grâce à un ensemble de balises XML appelé CDM (Common Dictionary Markup), il était arrivé à "récupérer" des dictionnaires informatisés classiques (monolingues ou multilingues furcoïdes) quelconques, pourvu qu'ils soient en XML, et à les présenter de façon homogène à travers une interface Web unique[32]. Très rapidement, on y intégra de nombreux dictionnaires mis en "source ouvert" par leurs auteurs (le GETA et l'USM pour le FEM et le dictionnaire russe→français tiré du système de TA RUS-FRA, Jim Breen pour JMDict, avec ses 90000 entrées en japonais→anglais, Ulrich Apel pour ses 200000 ou 250000 articles en japonais↔allemand, J-Y. Desperrier pour la traduction en japonais→français de 15000 articles du JMDict, Ho Ngoc Duc pour ses 41000 et 39000 articles en français↔vietnamien, etc.).
En 2016, Papillon-CDM contient 2 millions d'articles concernant les langues : allemand, anglais, français, japonais, malais, vietnamien, chinois, russe, peul, wolof et fas. Les articles concernant des langues africaines viennent du projet DILAF, mené depuis 2008 par M. Mangeot.
On peut consulter plusieurs dictionnaires à la fois, avec lemmatisation de la forme recherchée, télécharger tout ou partie de la base, sous forme XML, et y contribuer par une interface générée automatiquement à partir de la structure CDM.
La seconde base lexicale, Papillon-NADIA, a été prévue comme une version structurée selon l'architecture générale NADIA proposée dans la thèse de G. Sérasset (un volume monolingue pour chaque langue, où chaque article correspond à une lexie (Définition 10), et un volume central d'acceptions interlingues ou axies (Définition 11). Pour chaque volume, on voulait adopter une structure conforme à la lexicologie explicative et combinatoire d'Igor Mel'čuk qui a défini la notion de lexie. On choisit en 2000 non pas la structure du DEC, jugée trop complexe, mais la structure générique DiCo de Mel'čuk et Polguère [Mel'čuk, I. & Polguère, A., 2006], qui en est une simplification et était en cours d'implémentation sous FrameMaker.
Les schémas XML des volumes monolingues de type DiCo et du pivot (acceptions interlingues ou axies) ont été écrits en 2001 (puis améliorés), et un petit nombre d'articles en français, japonais et anglais a été mis dans ces formats pour validation.
Définition 10. Une lexie est un sens de mot dans un dictionnaire.
Définition 11. Une axie est une classe d'équivalence de lexies synonymes.
I.1.3.2.4 Projet IToldU (0,75 p.)
IToldU [Bellynck, V. et al., 2005] (Industrial Technical On Line Dictionary for Universities) est un site pédagogique destiné à faire développer par les étudiants, dans le cadre de leur apprentissage de l'anglais, des dictionnaires techniques anglais-français, dans le cadre de l'enseignement de l'anglais à l'EFPG (École Française de Papeterie et industries Graphiques, renommée PAGORA en 2008). Ce projet a été lancé par V. Bellynck et J. Kenwright et a fonctionné durant 3 ans (2003-2006). Il a permis la construction collaborative d'un dictionnaire terminologique anglais→français de microstructure très simple : terme-en, terme-fr, domaine, exemple d'usage.
Selon V. Bellynck, l'un des objectifs était de "motiver les étudiants à participer à la constitution d'un savoir commun en valorisant l'effort fourni, et d'éviter une surcharge de travail à l'enseignant".
IToldU a été un vrai succès du point
de vue des contributions, sans doute parce que le travail avec cet outil
donnait 1/3 de la note d'anglais. Pendant l'année scolaire 2003-2004, on a
obtenu 17020 entrées bilingues (français et anglais) avec environ 250 étudiants
répartis en 12 classes, et 5 professeurs d'anglais. Les professeurs pouvaient
évaluer les contributions des étudiants via une interface réservée aux
professeurs. Les équivalents étaient corrects à 90%. Par contre, les exemples
d'usage n'étaient bons qu'à 60% environ, et cela parce que cette notion avait
été mal expliquée aux étudiants. Cela fut amélioré en 2004-05 (on obtint
environ 6000 nouveaux articles, avec 90% et 85% de qualité).
Le problème rencontré en 2005-06 fut que les étudiants se mirent à "détourner" l'environnement, par exemple en allant juste après un cours monopoliser les mots de la "chasse aux mots" proposée durant le cours, au détriment des autres étudiants. Il aurait fallu avoir des ressources supplémentaires pour développer une version permettant aux professeurs d'anglais de définir eux-mêmes de nouvelles activités pédagogiques et des stratégies pour les contrôler et les évaluer.
La ressource produite par le projet IToldU a récemment été intégrée à Pivax-2, voir II.4.2.1.
Idée
guide 6. Une base lexicale contributive ne
peut bien fonctionner que si (1) on peut motiver les contributeurs, et (2) un
ou des animateurs (non-informaticiens) peuvent définir de nouvelles tâches et organiser
puis contrôler eux-mêmes le fonctionnement de l'outil.
I.1.4 1991—: évolution vers des bases lexicales (4,5 p.)
I.1.4.1 Bases lexicales permettant la symétrie (1,5 p.)
On a posé le problème
de la non-symétrie dans les dictionnaires au I.1.3.1.1. À cause de ce problème, on ne peut pas
inverser ou composer des dictionnaires classiques en conservant leurs qualités.
À partir des années 1990, on a construit des BDLex symétriques grâce aux
notions de lexie (sens de mot dans un dictionnaire) et d'acception (sens de mot
en usage).
Définition 12. Une acception est un ensemble de lexies synonymes. On appelle axème une acception monolingue, et axie une acception interlingue (pouvant regrouper des lexies de différentes langues).
Par exemple, le mot
français bleu correspond à plusieurs lexies : bleu_nm#couleur, bleu_nm#fromage, bleu_nm#contusion, bleu_adj#couleur, bleu_adj#cuisson, etc. Un axème pour le sens de résultat d'un choc pourrait être axème_n#18903, regroupant la lexie bleu_nm#contusion
et la lexie ecchymose_nf#contusion.
Ces idées ont été
introduites par Étienne Blanc, linguiste-informaticien, quand il créa la BDLex PARAX [Blanc, E.,
1999]. Le but était de créer une base de données lexicales
multilingues à acceptions interlingues basée sur HyperCard[35].
Depuis, il l'a convertie en Revolution[36],
puis en LiveCode.
Dans cette BDLex, il y a un dictionnaire pour l'espace lexical (Définition 13, reprise ici telle quelle de la
thèse de H.-T. Nguyen) d'UNL, qui
contient des UW.
Définition 13. On appelle "espace lexical" d'une langue l'ensemble structuré de ses unités, à des niveaux de plus en plus abstraits ou génériques : formes, lemmes, racines (dans certaines langues) familles dérivationnelles plus ou moins productives, prolexèmes (réunissant par exemple US, USA et Etats-Unis), et "acception" ou "sens de mots"... sans oublier qu'il y a à tous ces niveaux des unités simples et des unités complexes (mots composés, lexies ou acceptions complexes).
Au début du projet
UNL, l'équipe de Hiroshi
Uchida à Tokyo avait créé environ 100K UW, à partir des ressources de projets
précédents (essentiellement, EDR). Chaque
groupe en a ensuite créé de nouvelles, en fonction des nouveaux mots à traiter
dans sa langue. Dans PARAX, il y a 5 volumes monolingues (français,
japonais, chinois, espagnol et russe). Chaque volume de langue contient de 30K
à 60K entrées. Chaque mot est relié à un ou plusieurs sens (lexies), et chaque
sens est relié à un UW.
Dans le
dictionnaire français, les entrées contiennent une description morphosyntaxique
assez complète, utilisée pour construire les dictionnaires du français de
systèmes de TA du labo. Cela n'a pas été fait pour les autres langues.
|
|
Exemple pour FRA |
|
[biens] {CAT(CATN),GNR(MAS),NUM(PLU)} "goods(icl>functional
thing)"; [catalogue]
{CAT(CATN),GNR(MAS),N(NC)}"catalog(agt>thing,obj>thing)"; [centaines] {CAT(CATN),N(NP)} "hundreds of"; |
|
|
Exemple pour ESP |
|
|
[necesidad] {VAR} "need(icl<abstract thing)"; [necesidad] {VAR} "need(icl>thing)";
[nivel] {VAR} "level(icl>thing)";
[no ambiguo] {VAR} "unambiguous"; |

Figure 3 : Structure et exemples de PARAX
|
|
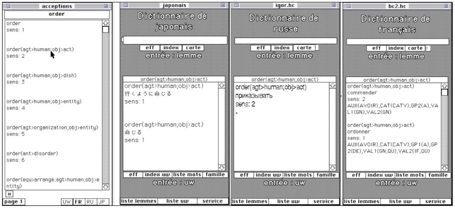
Figure 4 : Interface de consultation en colonnes de PARAX
I.1.4.2 Structure générique (microstructures et macrostructures) (1,5 p.)
Chaque système de
gestion de BDLex est basé sur des connaissances en linguistique, en lexicographie
et en informatique. Les structures d'organisation de dictionnaires sont donc hétérogènes. Dans sa thèse, G.
Sérasset [Sérasset,
G., 1994b] a construit Sublim, un système universel de BDLM (Base de Données
Lexicales Multilingue). Dans ce système, on décrit la structure d'une BDLex en
utilisant deux langages, Lexard et Lingard. Ces deux langages sont réalisés en CLOS (Common Lisp
Object System)[37].
Le langage Lexard permet d'écrire
des descriptions à deux niveaux : (1) le niveau des métadonnées telles que le type de dictionnaire (monolingue,
bilingue unidirectionnel, bilingue bidirectionnel ou interlingue), la langue du
dictionnaire, le propriétaire du dictionnaire etc., et (2) le niveau de la macrostructure (Définition 14) de la BDLex, qui regroupe tous les
dictionnaires avec des commentaires etc.
(define-monolingual-dictionary
english :language
"English" :owner "CRL-NMSU") |
|
(define-lexical-database ULTRA :owner "CRL-NMSU" :comment "Une base
lexicale fondée sur une approche interlingue" :dictionaries (english german
spanish japanese chinese IR)) |
Figure 5 : Exemples de métadonnées et de macrostructure
décrites dans SUBLIM
en Lexard
Définition 14. La macrostructure d'une BDLex est la description de son architecture générale, c'est à dire des types de ses volumes et de leurs relations.
Le langage Lingard permet de
décrire la microstructure (Définition 15)
des dictionnaires.
Définition 15. La microstructure d'un dictionnaire est la structure de ses articles, c'est à dire l'organisation de ses entrées.
En Lingard, on peut
décrire la structure informatique d'une unité lexicale en utilisant des constructeurs de base du langage,
prédéfinis (ensemble, arbre, graphe, liste, automate, énumération, etc.). Voir
la Figure 6.
|
(def-linguistic-class french_entry (feature-structure (lexical_unit
string) (Part-of-Speech (one-of "n.m"
"n.f" "v.t" "v.i" "v.pr."
"a" "adv" "loc" "prep")) (example (set-of string)) (indexer string) (quality (one-of "manual" "auto"
"reviewed")) (properties
(set-of property)) (uws (set-of
string)))) |
Figure 6 : Exemple de microstructure décrite dans SUBLIM en Lingard
L'idée de définir la structure d'une BDLex multilingue a été adoptée dans le projet Papillon [Mangeot, M. & Sérasset, G., 2001 ; Boitet, C. et al., 2002 ; Mangeot, M., 2002] (voir I.1.3.2.3). Pour cela, on a utilisé XML au lieu de MCL. Mais, en pratique, seul le niveau des microstructures a été décrit de cette façon, au moyen de schémas XML avec variantes. Les variantes permettent de spécifier certains attributs et leurs valeurs, comme le genre, le cas, les dialectes, qui diffèrent pour chaque langue. Les métadonnées ont également été définies en XML, sous une forme proche du langage XML Plist.
Par contre, la macrostructure de chaque base a été définie de façon seulement semi-formelle, en décrivant les relations entre les volumes. La macrostructure à "pivot par axies" de PARAX a été réutilisée telle quelle pour Papillon-Nadia [Sérasset, G., 1994a], LexAlp (voir II.1.3.2) [Sérasset, G., 2008], et (avec quelques extensions) PIVAX-1 (voir II.2).
Pour Papillon-CDM [Boitet, C. et al., 2002], la macrostructure se réduit à un ensemble de volumes, sans relations particulières entre eux. Le point intéressant est l'utilisation de pointeurs CDM (Définition 16) pour accéder aux dictionnaires électroniques intégrés dans la base comme s'ils étaient tous de même microstructure. On les présentera en détail au II.1.2.
Définition 16. CDM (Common Dictionary Markup) est une DTD (extensible) définissant un ensemble de balises XML correspondant aux types d'information des dictionnaires en source ouvert existants. Un pointeur CDM associé à une balise CDM <bbb> et à un dictionnaire Dic est un chemin Xpath permettant d'accéder à l'information correspondant à <bbb> dans Dic.
Cette technique permet d'importer très rapidement un dictionnaire dans la BDLex Papillon-CDM, de présenter l'ensemble des dictionnaires de façon unifiée, et de faire des recherches multicritère sur tout ou partie des dictionnaires de la base. Pour chaque dictionnaire, les pointeurs CDM sont stockés dans un fichier de métadonnées, de nouveau sous forme XML.
I.1.4.3 Ingénierie des BDLex contributives (1,5 p.)
Jibiki. G. Sérasset et M. Mangeot ont adopté une architecture à 3 couches pour implémenter les BDLex contributives : une couche de présentation (responsable de l'interface avec les utilisateurs), une couche "métier" (qui fournit les services) et une couche "données" (responsable du stockage des données). La plate-forme Jibiki a été implémentée avec ces trois couches, et développée principalement par M. Mangeot [Mangeot, M. & Chalvin, A., 2006] et G. Sérasset [Sérasset, G., 2004 ; Sérasset, G., 2008]. C'est une plate-forme générique en ligne de gestion, de création et de consultation de BDLex contributives. Elle a été principalement réalisée en Java sous l'environnement Enhydra[38] avec le SGBD PostgreSQL, les connexions avec la BD étant réalisées par un pilote JDBC de type 4[39].
|
|
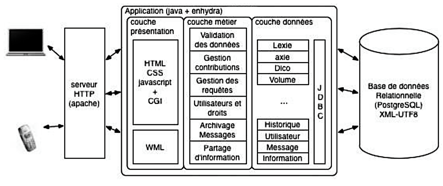
Figure 7 : Architecture à 3 couches de la plate-forme Jibiki
Cette plate-forme a été conçue en 2003, après plusieurs évolutions du projet Papillon. Elle permet de construire et de mettre en œuvre des BDLex contributives en ligne de différentes architectures. C'est une sorte de "framework". Jibiki a été utilisé dans plusieurs projets, comme Papillon (dont le logiciel a été réimplémenté en Jibiki) [Mangeot, M. et al., 2003], LexALP [Sérasset, G., 2008], MotÀMot [Mangeot, M. & Nguyen, H. T., 2009], GDEF [Mangeot, M. & Chalvin, A., 2006], Pivax-1 [Nguyen, H.-T. et al., 2007] et DiLAF.
Il y a ici deux niveaux de généricité, Jibiki se plaçant au niveau d'un métamodèle : chaque type de BDLex réalisé en Jibiki (comme LexALP) peut être considéré comme un modèle de BDLex, et les BDLex concrètes en sont des instances. Ainsi, on pourrait déployer plusieurs bases terminologiques différentes de type LexALP.
Après une dizaine d'années d'utilisation assez satisfaisante, des problèmes de rapidité et de passage à l'échelle sont apparus, principalement lors du projet OMNIA, quand on a voulu faire un grand nombre de recherches d'un seul coup dans une base PIVAX-1 (par exemple, 50 quand on cherchait tous les mots d'une légende de photo de Belga-News), ainsi qu'un traitement sur les résultats. Les causes de ces problèmes semblaient être la complexité de la macrostructure, et la grande taille des données. La taille elle-même ne pouvait pas être la seule cause, car elle était du même ordre de grandeur que celle de Papillon-CDM.
Au début de ma thèse en 2012, M. Mangeot avait prévu une
grande mise à jour de Jibiki, nommée Jibiki-2,
et j'y ai participé. Cette mise à jour a consisté à modifier la structure de la
couche "données" et les algorithmes d'interaction avec le SGBD. Avec Jibiki-2, le temps de réponse est beaucoup plus court (voir II.4.2.2).
Wiktionary/MediaWiki. Aujourd'hui, Wiktionary est le dictionnaire contributif le plus connu au monde. Ce projet a commencé en décembre 2002. Il a été construit avec le logiciel MediaWiki qui est le moteur de wiki de Wikipedia. La première version (appelée UseModWiki) a été développée en Perl, puis améliorée et réécrite par Magnus Manske et Lee Daniel Crocker en PHP avec le SGBD MySQL à partir de 2002. C'est en 2003 que le moteur a été appelé MediaWiki.
La structure générale de MediaWiki[40] a quatre couches : utilisateur, réseau, logique et données. La base de données contient le code wiki des pages et de nombreuses informations auxiliaires sur les pages, les utilisateurs, etc. Elle contient aussi les versions précédentes de toutes les pages. Quand une page est consultée, le code wiki est converti en Xhtml, ou bien ce code est pris du cache et envoyé à l'utilisateur, qui utilise son navigateur pour afficher le Xhtml.
|
Couche
utilisateur |
Client Web |
||
|
Couche réseau |
Serveur Web
Apache |
||
|
Couche logique |
Scripts PHP de MediaWiki |
||
|
PHP |
|||
|
Couche données |
Système de
fichiers |
Base de données
MySQL |
Système de
cache |
Figure 8 : Architecture de MediaWiki
Synthèse (0,75 p.)
Nous venons de voir l'évolution des idées en lexicographie computationnelle depuis 1980, date à laquelle on peut faire remonter la naissance de cette discipline.
Depuis 1980, on a cherché à faire le lien entre dictionnaires pour les systèmes de TA et pour les humains. Il faut reconnaître que les succès ont été très rares, que les difficultés sont réelles, et que les conséquences sont très dommageables. En effet, si les informations des dictionnaires de TA et des dictionnaires pour humains ne peuvent pas rester cohérentes, les unes ou les autres deviennent de moins en moins utiles dans les applications impliquant une synergie homme-machine, comme les outils d'aide à la traduction.
La seconde difficulté majeure, reconnue depuis 1985, est l'unification des dictionnaires généraux et des dictionnaires terminologiques, en les stockant (directement) dans une même base de données relationnelle, et en les transformant automatiquement vers les dictionnaires des systèmes de TA.
À partir de 1992, et de l'avènement d'Internet, la dictionnairique a évolué vers les réseaux et le contributif. La consultation en ligne est devenue très répandue. Par contre, même avec le Web 2.0 et les nouvelles possibilités de contribution, la construction contributive de dictionnaires s'est avérée très difficile à mettre en œuvre. Pour ce qui est des dictionnaires multilingues, on ne peut guère noter que Yakushite.net et Wiktionary.
Enfin, en parallèle, on s'est dirigé vers la conception de bases lexicales multilingues symétriques, pour surmonter les problèmes liés à l'asymétrie de dictionnaires de traduction. En passant par une base lexicale multilingue symétrique (de type PARAX ou NADIA), contenant des dictionnaires monolingues de lexies et des liens entre lexies synonymes (ce qu'on a appelé plus haut axies), on devrait pouvoir créer des dictionnaires inversés, ou composés, sans perte de qualité.
Nous allons maintenant décrire plus précisément la situation au départ de cette thèse, et dans son contexte particulier, académique et industriel.
I.2 Situation et problèmes en 2012 (8 p.)
Au début de cette thèse, le contexte de la recherche sur les bases lexicales était complexe et multiple. D'autre part, comme il s'agissait d'une thèse CIFRE (université-industrie), les problèmes jugés les plus intéressants n'étaient pas les mêmes des deux côtés.
Nous présenterons d'abord la situation au laboratoire, puis les intérêts de L&M, et enfin les thèmes émergents au niveau de la communauté du TALN, comme l'extraction de termes bilingues et d'expressions polylexicales.
I.2.1 Au GETALP
I.2.1.1 Projets dérivés des thèses de G. Sérasset et de M. Mangeot (1 p.)
Pivax. J'ai commencé à m'intéresser aux bases lexicales contributives lors d'un stage de M2P-GI, puis d'un stage "prédoc", les deux dans le cadre du projet ANR Traouïéro (2011-2013), et plus précisément de la sous-tâche Pivax++. Il s'agissait d'améliorer Pivax et de le rendre vraiment opérationnel. Pivax [Nguyen, H.-T. et al., 2007 ; Nguyen, H.-T., 2009 ; Nguyen, H. T. & Boitet, C., 2009] est une BDLex multilingue contributive orientée vers les systèmes de TA hétérogènes et diverses autres utilisations. Elle contenait non seulement d'assez gros volumes monolingues de langues naturelles (français, anglais, espagnol, russe…), mais aussi des dictionnaires d'UW (lexèmes interlingues) venant de plusieurs projets UNL, tout le WordNet anglais (v3), et l'ontologie du projet OMNIA. Le projet Traouïéro visait en particulier à opérationnaliser l'outil Pivax et à promouvoir la construction d'une base de données contenant au moins 4 langues et 1M UW.
Jibiki.
Papillon, Lexalp, et Pivax ont été construits sur Jibiki [Mangeot,
M., 2006 ; Mangeot, M. & Chalvin, A., 2006 ; Sérasset, G. et al., 2006], une plate-forme générique de développement
contributif de BDLex. Cette plate-forme avait été créée par G. Sérasset et M.
Mangeot, et ce dernier commençait la création d'une nouvelle version, Jibiki-2.
Papillon. Ce projet a
été présenté plus haut. En 2012, l'objectif en ce qui le concernait était de
reprogrammer son logiciel de base de Jibiki-1 en
Jibiki-2, et de continuer à y ajouter des données venant de divers projets
dictionnairiques comme MotÀMot et DILAF.
LexALP. Il s'agit
d'un projet européen InterReg (janvier 2005 - février 2008), visant
à harmoniser la terminologie en aménagement du territoire et développement
durable au sein de la Convention Alpine afin de permettre aux six pays participant
à cette convention (Autriche, France, Allemagne, Italie, Suisse et Slovénie) de
communiquer et de coopérer efficacement dans quatre langues officielles (français,
allemand, italien et slovène). À la fin du projet, la BDLex LexALP contenait plus de 13K entrées [Sérasset,
G. et al., 2006 ; Sérasset, G., 2008]. En 2012, ce projet n'était plus
actif au laboratoire, mais la BDLex était toujours disponible.
Dbnary. G. Sérasset
a commencé le projet Dbnary en 2012 (juste au début
de cette thèse). Ce projet vise
à extraire des données lexicales structurées en rdf (conforme au modèle LEMON), à
partir des différentes éditions des wiktionnaires. En 2015, il y a des
extracteurs pour 21 langues, qui produisent une "édition" par semaine[41].
GDEF. GDEF [Mangeot,
M. & Chalvin, A., 2006] est un projet visant à créer un Grand
Dictionnaire bilingue Estonien-Français, commencé en 2003. La BDLex
sous-jacente est basée sur Jibiki. Le GDEF contient actuellement plus de 16K
entrées.
MotÀMot. C'est un autre projet (2009-2012) basé sur Jibiki [Mangeot, M. & Nguyen, H. T., 2009 ; Mangeot, M. & Touch, S., 2010]. Il vise à élaborer un système lexical multilingue par le biais de la construction de dictionnaires bilingues ciblés sur des langues peu informatisées d'Asie du Sud-Est. Pour l'instant, il est limité au français et au khmer. Le volume français contient 13 249 entrées, le volume khmer 23 766, et le volume des axies 32 402.
UNL/U++C (UNL++). Ce projet [Boitet, C. et al., 2007 ; Nguyen, H.-T., 2009] est une variante du projet UNL. Il s'agit des travaux du consortium U++C, visant à construire des dictionnaires UW++-LN à partir des dictionnaires UW-LN existants (par unification des ensembles d'UW des différents groupes). Ces dictionnaires sont stockés dans Pivax.
I.2.1.2 La génération de mini-dictionnaires, une nouvelle application générique (0,5 p.)
Il s'agit de construire à la volée et très rapidement un "mini-dictionnaire" spécifique d'une sélection de texte. Cela serait très utile non seulement pour la "lecture active en langue étrangère", mais dans beaucoup d'autres contextes.
Durant le projet ANR OMNIA (2008-2011), Hong-Thai Nguyen a fabriqué des mini-dictionnaires associés aux légendes des photos dans des archives comme Belga-news, Flicker, etc. En parallèle, dans le cadre du projet SECTra_w/iMAG, Cong-Phap Huynh et H.-T. Nguyen ont cherché à implémenter l'idée d'aide lexicale proactive associée à chaque segment, en faisant calculer à Pivax-1 un mini-dictionnaire (bilingue ou multilingue) pour chaque segment de la mémoire de traductions associé à un document ou à un site Web. Ils ont alors rencontré quelques difficultés inattendues, puis n'ont pas eu le temps d'implémenter complètement leur solution.
Ces difficultés concernaient la définition exacte du format d'un mini-dictionnaire : il doit être très simple, et aussi permettre aux utilisateurs de corriger ou de compléter une entrée, avec certaines restrictions bien sûr, puis de le renvoyer à la base lexicale pour qu'elle mette à jour les informations. D'où un problème de synchronisation, puisque plusieurs intervenants peuvent en même temps modifier la base lexicale et les mini-dictionnaires. D'autre part, l'idée de calculer tous les mini-dictionnaires en arrière-plan s'est alors heurtée au manque d'un système de gestion de travaux (files d'attente, priorités, etc.).
I.2.1.3 Résultats de thèses antérieures non liées à Jibiki (1 p.)
RÉCUPDIC/PRODUCDIC. Ces deux logiciels ont été réalisés par H. Doan-Nguyen durant sa thèse (soutenue en décembre 1998) [Doan-Nguyen, H., 1998a]. RÉCUPDIC est un système de récupération de ressources dictionnairiques à partir de leur format d'origine, par transformation en une structure plus profonde (LISPO) avec des informations explicites. PRODUCDIC est un outil destiné à la production de nouveaux ensembles lexicaux à partir de résultats de RÉCUPDIC. Il offre 7 fonctions (sélection, extraction, regroupement, inversion, enchaînement, combinaison parallèle et combinaison en étoile). Ces deux logiciels sont implémentés en LISP (CLOS). Ils ont été réutilisés dans la thèse de M. Mangeot [Mangeot, M., 2001] et dans la thèse de H.-T. Nguyen [Nguyen, H.-T., 2009].
Jeminie. Il s'agit d'une plate-forme pour structurer les BDLex, produire et filtrer les acceptions bilingues ou multilingues, et évaluer la qualité de BDLex à acceptions interlingues. Elle a été créée par Aree Teeraparbseree dans le cadre de sa thèse [Teeraparbseree, A., 2005].
MulLinG. MulLinG (MultiLevel Linguistic Graphs) [Archer, V., 2009] est une bibliothèque C++ spécialisée pour la programmation linguistique d'algorithmes d'extraction de connaissances lexicales, et réalisée par Vincent Archer dans le cadre de sa thèse. Le modèle sous-jacent est un modèle de graphe linguistique multiniveau dans lequel les arcs sont internes à un niveau, ou vont d'un niveau à un niveau supérieur. Les opérateurs génériques permettent des applications multiples.
Robodico. Robodico [Nguyen, H.-T., 2009] est un programme associé à Pivax, réalisé par H.-T. Nguyen. Il a pour but d'extraire des ressources lexicales à partir de sites de bases terminologiques ou de dictionnaires en ligne comme IATE[42]. Il simule les paramètres des requêtes HTTP, puis récupère les pages Html et en extrait les ressources. J'ai récupéré cet outil et l'ai mis à jour pour accéder aux ressources d'IATE durant ma thèse.
SEPT
et Préterminologie. Il
s'agit d'un Système pour Éliciter une PréTerminologie (SEPT),
développé par Mohammad Daoud dans le cadre de sa thèse [Daoud, M., 2010]. Ce système permet de construire et de maintenir
des structures de graphe de préterminologie multilingue. Il a défini le
terme "préterminologie" pour désigner une
terminologie non validée, obtenue à partir de ressources non conventionnelles
(comme des traces de consultation de sites Web).
I.2.2 Chez L&M (1,75 p.)
I.2.2.1 Une BDLex simple destinée aux glossaires multilingues (0,75 p.)
Lingua et Machina [Lingua&Machina, 2015] propose des outils linguistiques, Similis [Planas, E., 2005] et Libellex [Brown de Colstoun, F. et al., 2011]. C'est sur ce deuxième produit, Libellex, que j'ai principalement travaillé durant cette thèse. Libellex est une application Web de gestion des écrits multilingues en entreprise. Cette plate-forme intègre divers outils d'aide à la traduction (concordances bilingues, outils d'extraction et de gestion de terminologies, mémoires de traductions, systèmes de traduction automatique et outils de gestion de projets de traduction).
La fonction de gestion de terminologies de Libellex (Libellex Termino) a été conçue en juillet 2010 par Estelle Delpech [Delpech, E., 2013]. Il y a une BDLex pour cette fonction liée à Libellex, implémentée en Oracle. Les utilisateurs principaux de cette fonction sont des traducteurs. La conception de cette BDLex est bien adaptée aux glossaires, mais pas aux termes généraux.
Le projet ANR MeTRICC[43] a
duré entre décembre 2008 et décembre 2011, et s'est terminé juste avant le
début de ma thèse. Ce projet avait pour but l'extraction de ressources
terminologiques à partir de corpus comparables. Il y a une BDLex liée à ce
projet pour stocker les termes extraits. Ces analyses et extractions sont
réalisées vers des formats UIMA[44].
E. Delpech a proposé de réutiliser la structure de BDLex du projet MeTRICC dans Libellex. Libellex a été étendu pour pouvoir travailler avec les lexiques extraits de corpus comparables au format d'échange de MeTRICC.
Les formats TBX[45] (TermBase eXchange) et TEI[46] (Text Encoding Initiative) sont des formats adaptables. Le format TEI_MeTRICC et le format TBX_MeTRICC sont deux adaptations aux besoins de MeTRICC et sont utilisés comme formats d'échange dans MeTRICC. La BDLex de MeTRICC a été conçue à partir de ces deux formats.
On trouvera la définition des structures de TBX et de TBX-MeTRICC et la structure de BDLex de MeTRICC au III.1.2.3.
I.2.2.2 Problèmes perçus (1 p.)
I.2.2.2.1
Limitation du schéma conceptuel (1 §.)
Comme Libellex a réutilisé la même structure de BDLex que MeTRICC, sa BDLex a été également conçue à partir des formats d'échange TEI_MeTRICC et TBX_MeTRICC. Dans cette BDLex, il n'y a donc pas de niveau pour représenter les sens, ce qui est la source de nombreux problèmes.
En effet, le format TBX standard, tel que décrit dans l'ISO 30042, a été spécifiquement conçu pour encoder des données terminologiques créées par des humains et sans ambiguïtés. Les données terminologiques sont organisées en "concepts", les termes étant de simples désignations de ces concepts dans différentes langues. Les relations sémantiques (synonymie, antonymie, etc.) relient des concepts, et non des termes. Elles sont donc indépendantes des langues.
Mais, dans TBX-MeTRICC, le schéma
conceptuel est limité à l'équivalence de termes. E.
Delpech a expliqué cela de la façon suivante dans la spécification du format TBX-MeTRICC sur l'intranet de Lingua et Machina.
"Les données terminologiques
générées automatiquement sont ambiguës, typiquement, un terme source est associé
à plusieurs termes cible (traductions candidates). Il n'existe pas de notion de
concept : les outils d'extraction terminologique ne reconnaissent que des
termes, charge au terminologue de les associer ensuite à des concepts. En plus,
dans un contexte multilingue, avec une perspective d'application à la traduction,
l'organisation en "concepts" présente peu d'avantages. Cette
organisation suppose l'existence de concepts universaux, indépendants des
langues et une structuration des concepts identique de langue à langue. Cela ne
correspond pas à la réalité que connaissent les traducteurs : chaque
langue impose un découpage différent de la réalité et il est très difficile de
maintenir un parallélisme entre les langues."
I.2.2.2.2 Une conséquence: le problème des abréviations (1 §.)
Il y a des besoins réels dans l'industrie. Par exemple, EDF,
client de L&M, a demandé un traitement
complet des acronymes, et un autre client, Wesco, voulait nourrir un
dictionnaire d'abréviations. En 2012, Libellex-termino ne pouvait
pas traiter ce type de problème. Comme il n'y a pas de niveau pour traiter les sens, c'était très difficile à faire. Il s'agit
d'import, d'export, de manipulation, d'édition des acronymes et d'autres abréviations. La
seule chose qu'on pouvait faire en 2012,
c'était créer une relation entre deux termes
de la même langue, et cette relation ne pouvait être que "variante de terme"[47].
En 2013, un autre client,
ExaleadSuggest, nous a demandé de traiter leur terminologie avec les relations "vedette, synonyme, variante non typée, variante de
type abréviation, et variante de type acronyme" entre termes monolingues.
En même temps, Louis Vuitton a demandé à L&M un traitement de la relation
hyperonymie/hyponymie des termes monolingues en utilisant le
mot-clé "parent-enfant", par exemple, "couleur" est parent
de "rouge" et "rouge"
est enfant
de "couleur".
I.2.2.2.3 Dépendance d'un logiciel propriétaire (1 §.)
La BDLex de Libellex a été développée sous Oracle. Pendant ma thèse, vers 2014-15, L&M a fait une migration d'Oracle vers PostgreSQL. À partir de ce moment, je ne pouvais plus modifier la structure de BDLex, mais l'API (en SQL) est restée la même, au moins en ce qui concernait ma partie.
I.2.3 Dans la "communauté scientifique" du TAL (3,75 p.)
I.2.3.1 Extraction de termes techniques (1 p.)
Au début de ma thèse, il y avait beaucoup d'activités sur l'extraction de termes en contexte monolingue et multilingue, et sur l'extraction d'expressions polylexicales (termes et prédicats composés).
La thèse de Violeta Seretan [Seretan, V., 2008] propose (et évalue sur des données en 4 langues, anglais, français, espagnol et italien) une procédure principale d'extraction de collocations binaires qui se base sur l'application de la contrainte de proximité syntaxique aux éléments d'une collocation candidate, à la place de la contrainte de proximité linéaire qui est la plus répandue dans les travaux existants. Ses résultats sont bien meilleurs que ceux des approches linéaires, mais sa méthode suppose la disponibilité, pour chaque langue considérée, d'un analyseur du type et de la qualité de FIPS [Wehrli, E., 2007], qui produit des arbres syntaxiques. Malgré tout, c'est une voie d'avenir.
La thèse d'Estelle Delpech [Delpech, E., 2013] a reçu le prix de thèse de l'ATALA en 2014. C'était aussi une thèse CIFRE avec L&M. Elle concernait l'extraction de lexiques bilingues à partir de corpus comparables, appliquée à la traduction spécialisée. E. Delpech a travaillé d'une part pour le projet ANR MeTRICC, et d'autre part pour la fonction de terminologie de Libellex chez L&M. Sa conclusion est que ces techniques ne produisent rien de réellement intéressant et utilisable pour la traduction professionnelle, et qu'il faut d'abord faire un travail terminologique, qui produit à la fois les termes et leurs traductions (c'est d'ailleurs ce que font les gros donneurs d'ordres comme IBM). Il y a cependant toujours des recherches de ce type en cours.
CAMELEON[48] (Collaborative and Automatic Methods for the Multilingualisation of Lexica and Ontologies). Ce projet collaboratif réunissait des équipes françaises (GETALP du LIG et MELODI de l'IRIT) et des équipes brésiliennes (UFRGS, PUCRS et UFSCAR). Ce projet a commencé en 2010 et s'est terminé en 2014.
Le projet ANR MeTRICC (MEmoire de Traductions, Recherche d'Information et Corpus Comparables) venait juste de se terminer début 2012. Nous l'avons déjà mentionné au I.2.2.1. Comme la thèse d'Estelle Delpech [Delpech, E., 2013], il avait pour but l'extraction de ressources terminologiques à partir de corpus comparables. Malgré les résultats négatifs (et de principe) de cette thèse, ce thème continue d'être actif dans la communauté du TALN.
Presque en parallèle, le projet européen TTC[49] (Terminology Extraction, Translation Tools and Comparable corpora) s'est déroulé du 1er janvier 2010 au 31 décembre 2012. Les participants étaient le LINA (Nantes), l'INLP (Institute for Natural Language Processing) de Stuttgart, UL (University of Leeds), Sogitec, Syllabs, TILDE et Eurinnov. Il visait à exploiter les possibilités offertes par les corpus comparables pour améliorer les performances des outils informatiques de traduction. Il s'agissait de traiter des domaines techniques dans un contexte massivement multilingue où il est nécessaire de traduire un même document dans beaucoup de langues.
Le projet chinois (No. 07JC870006) "Research on text mining applied to plagiarism detection" (文本挖掘技术在论文抄袭判定中的研究) et son sous-projet "Chinese Text Keywords Extraction Based on Fuzzy Processing" (基于模糊处理的中文文本关键词提取方法) a été lancé par Anhui Finance and Economics University (Anhui, Chine) entre 2007 et 2012. Ce projet a proposé des algorithmes sur les extractions de mots-clés pour le chinois.
Les workshops CHAT
(Creation, Harmonization and Application of Terminology Resources)[50] ont
eu lieu en 2011 et en 2012.
I.2.3.2 Extraction d'expressions polylexicales (EPL) (0,25 p.)
En ce qui concerne le traitement des EPL (expressions polylexicales[51]), il y a une activité plus récente, mais assez forte.
Workshops MWE (MultiWord Expressions) : cette série de workshops[52] a commencé en 2003, sur un rythme annuel. On parle de plus en plus de "PLE" (PolyLexical Expressions).
La thèse de Carlos Ramisch [Ramisch, C., 2012] a abordé le problème du traitement des EPL dans les applications de TAL. La plate-forme MWEtoolkit [Ramisch, C., 2012] a été développée dans le cadre de sa thèse et a été utilisée dans le projet CAMELEON. C'est une plate-forme générique en source ouvert permettant de faire plusieurs traitements sur les EPL, y compris les extractions et les évaluations. Toute une communauté l'utilise maintenant.
Le thème de l'extraction d'EPL à partir de corpus parallèles a été envisagé depuis longtemps, mais ne semble pas encore avoir été réellement abordé. Pour l'étudier avec profit, il faudrait sans doute inclure l'allemand dans les langues considérées, mais cela suppose une certaine connaissance de cette langue.
I.2.3.3 Projets de BDLex "sémantiques" (1,25 p.)
WordNet
[Miller, G. A. et al., 1990] a pour but de répertorier,
classifier et mettre en relation de diverses manières le contenu sémantique et
lexical de la langue anglaise. Il y a de nombreux projets dérivés, comme EuroWordNet (néerlandais,
italien, espagnol, allemand, français, tchèque et estonien) [Vossen, P., 1998] et IndoWordNet (18 langues utilisées en Inde) [Chakrabarti, D. et al., 2002].
FrameNet [Fillmore, C. J. & Atkins, B. T. S., 1998] a été lancé depuis 1997. L'objectif est d'élaborer une ressource linguistique accessible par les humains et les machines. Cette ressource décrit initialement le lexique anglais selon les principes des cadres conceptuels, chaque unité lexicale étant illustrée par des exemples annotés manuellement. À ce jour, il y a plusieurs projets FrameNet pour diverses langues (coréen, chinois, brésilien, allemand, japonais, suédois, etc.).
ProLex[53]. Ce projet de lexique syntaxique et sémantique de noms propres, basé sur le concept de prolexème, dû au célèbre linguiste et sémiologue Eugène Coseriu, a été lancé par le laboratoire d'informatique de l'université François-Rabelais de Tours. Dans sa thèse, Mickaël Tran [Tran, M., 2006] a développé ProlexBase, un outil supportant un lexique multilingue de type ProLex, et proposé la stratégie "prolexème" [Grass, T. et al., 2004 ; Tran, M. & Maurel, D., 2006]. Voici la définition de prolexème dans la thèse de M. Tran :
Définition 17. Dans notre modèle (Prolexbase), le prolexème correspond à une projection du nom propre conceptuel dans une langue donnée.
Chaque
prolexème d'une langue donnée sera donc relié à un seul et unique nom propre
conceptuel. C'est en se basant sur cette relation que l'on va pouvoir traduire
les prolexèmes d'une langue vers une autre. Le concept de prolexème peut aussi
se définir comme une classe d'équivalence de synonymes. Pour simplifier, nous
considérons aussi le prolexème comme le lemme associé aux différentes formes
d'un nom propre qui apparaissent dans les différents textes d'une langue
donnée. Il peut ainsi être considéré comme la forme vedette d'un ensemble de
dérivés et d'alias [Tran, M., 2006].
BabelNet [Navigli, R. & Ponzetto, S. P., 2010] est un grand réseau lexical multilingue qui fournit des entrées lexicales (plus de 9 millions) dans plus de 50 langues, reliées entre elles par une grande quantité de relations sémantiques. Il a été créé automatiquement en utilisant les ressources de Wikipédia et de WordNet, et la traduction automatique.
OMNIA
[Rouquet, D. et al., 2013] (2008-2011) fut un projet
financé par l'ANR, avec comme participants XRCE (Xerox), LIG (GETALP), et ECL
(LIRIS). Ce projet visait à filtrer des documents contenant du texte et des
images, dans un contexte de grandes masses de données.
Cjk.org
[Halpern, J., 2002 ; Halpern, J., 2006 ; CJK, 2015],
construit une très grosse base qui contient environ 24 millions d'entrées en
japonais, chinois (simplifié et traditionnel), coréen, anglais et arabe, et comprenant
un riche ensemble d'attributs grammaticaux et sémantiques, surtout pour des
noms propres (donc des entités nommées).
HowNet [Dong, Z. et al., 2010] a été construit à partir de 1988. C'est une base de connaissances du sens commun (online common-sense knowledge base) pour l'anglais et le chinois qui repose sur des annotations exprimant des relations entre concepts et des relations entre attributs de concepts.
Il y a 5 points principaux pour les différences entre WordNet (WN) et HowNet (HN) : (1) WN est orienté vers les humains et HN vers les machines ; (2) les annotations de WN sont faites par des humains et celles de HN par des programmes ; (3) WN est basé sur les mots et HN sur les concepts ; (4) WN a des "synsets" qui sont des ensembles de quasi-synonymes, et HN a des sémèmes qui sont des composants de sens ; (5) WN a des définitions en langue naturelle alors que HN utilise des définitions exprimées dans un langage formel, avec des balises.
L'Annexe 4 contient des réponses détaillées du Prof. Dong Zhen Dong à un certain nombre de nos questions.
Ressources ontologiques. Il y a beaucoup d'ontologies disponibles, par exemple, UMLS[54] (Unified Medical Language System) pour les concepts biomédicaux, ou les ressources de la FAO (AGROVOC[55] et FAOTERM[56]) pour l'ontologie de l'agriculture et pour l'ontologie de la géopolitique.
TOTh. La conférence Terminologie et Ontologies : Théories et applications (TOTh) a lieu chaque année en juin à Annecy depuis 2007 ; elle est organisée par l'institut Porphyre, la société française de terminologie, et l'Université de Savoie.
TIA. Le groupe TIA (Terminologie et Intelligence Artificielle) organise des conférences depuis 1995 : TIA'95 (Villetaneuse), TIA'97 (Toulouse), TIA'99 (Nantes), TIA'01 (Nancy), TIA'03 (Strasbourg), TIA'05 (Rouen), TIA'07 (Nice), TIA'09 (Toulouse), TIA 2011 (Paris), TIA 2013 (Villetaneuse), TIA 2015 (Grenade).
I.2.3.4 Création contributive de dictionnaires pour la TA (0,75 p.)
Yakushite.net (voir I.1.3.2.1) est une plate-forme Web grâce à laquelle des traducteurs peuvent consulter et augmenter (aspect contributif) des dictionnaires en ligne, organisés en un hiérarchie. Ces dictionnaires sont automatiquement intégrés dans le système TA Pensée de OKI Electric (Japon).
Apertium
[Forcada, M. L. et al., 2011 ; Apertium, 2015]. Dans le cadre du projet Apertium, il y a 218 dictionnaires monolingues en 93 langues
différentes, avec plus de 3,8M entrées, et 236
dictionnaires bilingues en 235 couples de langues différents, avec plus de 2,5M
entrées[57].
L'outil associé DicsToolsSuite aide les utilisateurs
(non-programmeurs) à faire de la création contributive de dictionnaires Xml grâce à des interfaces conviviales.
|
|
1. Zone pour dictionnaires
sélectionnés (on peut importer ou exporter un dictionnaire) 2. Statut de dictionnaires
(reperatoire de fichier, nombre de lemmes, nombre de symboles… ) 3. Zone principale pour
manipulation 4. Composants pour la
communication (pour affichage des erreurs, des informations d'utilisateur
etc.) 5. Barre d'outils et status de
mémoire (affichage de la mémoire utilisée par l'application) 6. Zone pour afficher les
messages de traitement 7. Zone pour la base de
données (désactivée temporairement) |
Figure 9 : Interface de DicsToolsSuite
UNL. On a déjà mentionné le projet UNL au I.1.3.2.2. En France, les dictionnaires initiaux ont été contribués par très peu de personnes, contribuant chacune des volumes assez grands. Le dernier projet, appelé GBDLex-UW++, a été supporté par Pivax-1 à Grenoble. C'est H.-T. Nguyen qui a préparé l'environnement pour qu'on puisse faire de la création contributive, et qui a mis les dictionnaires initiaux en ligne. Malheureusement, le projet n'a plus été "animé" depuis son départ. Il faut cependant noter les très importantes contributions de V. Dikonov de l'IPPI (plus de 800000 UW avec leurs traductions dans 4 à 5 langues).
I.2.3.5 Désambiguïsation lexicale (0,5 p.)
VideoSense[58].
Dans le cadre de ce projet (2009-2013), on a proposé d'utiliser un répertoire
de sens "pivot" artificiels pour la désambiguïsation de données
textuelles multilingues accompagnées de vidéo. Comme candidats à être ce répertoire
pivot, il y avait UNL[59] et
WordNet[60],
mais leurs représentations des sens ont des problèmes comme la polysémie et l'incomplétude.
Finalement, on a utilisé les vecteurs conceptuels (avec "émergence") pour
représenter les sens. Mais… ces vecteurs ne donnent qu'une représentation
"thématique" des sens, et de plus les résultats dans les campagnes
d'évaluation ont été très décevants.
SemEval (Semantic Evaluation). Depuis 1998, il y a eu plusieurs campagnes[61] (semeval-senseval) destinées à évaluer la désambiguïsation lexicale. Les évaluations ont concerné 18 langues : arabe, basque, tchèque, chinois, catalan, hollandais, danois, anglais, estonien, français, japonais, italien, coréen, allemand, espagnol, suédois, roumain, turc.
Thèses et mémoires. Il y a eu plusieurs thèses et mémoires autour de ce thème, avant 2012, comme la thèse de D. Schwab [Schwab, D., 2005], celle de L. Audibert [Audibert, L., 2003], ou le mémoire de master de B. Brosseau-Villeneuve [Brosseau-Villeneuve, B., 2010].
Il y a aussi des recherches sur l'estimation des coefficients de confiance dans les systèmes de TA, par exemple la thèse de N.Q. Luong [Luong, N. Q., 2014].
I.3
Thèmes de recherche abordés[62] (4,25 p.)
I.3.1 Thèmes encore ouverts (3,25 p.)
Au début de cette thèse, 8 thèmes étaient encore ouverts dans notre contexte : trois thèmes "lexicographiques", trois thèmes concernant la conception de services, et deux thèmes plus liés au génie logiciel (GL).
I.3.1.1 Trois thèmes "lexicographiques" (2 p.)
I.3.1.1.1 Concevoir des BDLex "métier", contenant des éléments plus ou moins "situés"
La difficulté de l'unification dans une même base lexicale de lexèmes (simples ou composés) généraux, de termes techniques, d'abréviations, de noms propres et d'entités nommées semble provenir du fait qu'ils sont plus ou moins "situés".
Un lexème général comme chemin,
ou boire, ou vite a une
acception (sens en usage) que ne dépend pas d'un contexte d'interprétation
particulier. Nous dirons qu'il est général,
ou non situé.
Un terme technique comme ampoule a des sens dépendant de domaines particuliers (électricité, médecine, religion), mais pas du lieu ni du temps. Nous dirons qu'il est terminologique.
Une abréviation comme CNAM peut
signifier Caisse Nationale d'Assurance Maladie ou Conservatoire National des Arts et Métiers. Un toponyme
comme Rome renvoie à une ville, certes, mais
s'agit-il de la capitale de l'Italie, de Rome (New-York), ou d'autres villes de
ce nom aux USA ? Pour l'interpréter correctement, il faut disposer de la
situation, ou au moins de paramètres pertinents de la situation. Nous dirons que
CNAM et Rome sont situés.
Enfin, le sens des noms de sociétés, ou des noms de personnes, comme George W. Bush, dépend souvent d'une description encore plus précise du contexte. Même si on ajoute président des USA, il y en a eu deux de ce nom… et cette qualité leur reste attachée. En fait, le sens de beaucoup d'entités nommées dépend non seulement du domaine et du lieu, mais aussi du temps. On peut dire que les noms de personnes et ce qu'on appelle depuis quelques années les entités nommées sont très situés. Par exemple, la capitale de la RFA a été Bonn, puis Berlin à partir de 1991.
Un prolexème est par définition une classe d'équivalence d'expressions synonymes par rapport à une certaine situation. Ainsi, P1 = {président des USA, Georges W. Bush#2} est valide par rapport à 2005, et P2 = {président des USA, Barack Obama#1} est valide par rapport à 2015.
Définition 18. Nous appellerons "situement" la qualité d'être situé, et parlerons du "degré de situement" d'un lexème.
Ce terme "situement" semble naturel, car il est solution de plusieurs équations analogiques [Lepage, Y., 2000] comme : situer:situement::figer:figement::dénué:dénuement. On parle de même du "degré de figement" d'une collocation.
Définition 19. Chaque type de vocable correspond à un degré de situement : général, terminologique,
situé, ou très situé.
Pour bien expliquer les degrés de situement, nous donnons ici quelques exemples.
Table 1 : Exemples pour les différents degrés de situement
|
Mot-vedette |
Degré de situement |
Descripteur de situement |
Signification |
|
sémaphore |
général |
sémaphore#général |
signalisation maritime |
|
|
situé |
sémaphore#situé?lieu=Béar |
sémaphore du cap Béar (Chemin du Cap Béar, 66660
Port-Vendres) |
|
|
terminologique |
sémaphore#terminologique?domaine=informatique |
en informatique, dispositif de verrouillage de
ressources |
|
diabolo |
général |
diabolo#général |
instrument de jonglage |
|
|
terminologique |
diabolo#terminologique?domaine=médecine |
aérateur en ORL |
|
président |
général |
président#général |
chef d'État, président d'une compagnie, chef d'un tribunal, chef d'un acte etc. |
|
|
très situé |
président#situé?lieu=Etats-Unis&année=2015 |
Barack Obama |
|
|
très situé |
président#situé?lieu=Etats-Unis&année=2005 |
George W. Bush |
Définition 20. Une "BDLex métier" est une BDLex qui couvre tous les types de vocable dans une même base pour un certain domaine.
Une BDLex métier unifie donc les différents types d'unités lexicales, y compris les plus récemment traités comme les prolexèmes (on peut dire que "prolexème" en lexicographie correspond à "entité nommée" en sémantique). On présentera les prolexèmes en détail dans la section III.2.2.
I.3.1.1.2 Faire évoluer les BDLex vers l'approche "ontoterminologique"
Pour l'instant, on peut intégrer une ontologie ou une classification sémantique en tant que "volume" dans une base PIVAX. On préférerait introduire des liens étiquetés comme tels allant des axies vers des ontologies ou des classifications sémantiques (comme le Goi Taikei[63]). Le but de ce thème est de réaliser les identifications/raffinements des synonymes, des parasynonymes, et leurs dénotations et connotations terminologiques.
Dans les exemples de la Table 1, ces liens étiquetés permettent d'une part de préciser le degré de situement et d'identifier les paramètres pertinents du contexte (temps, lieu, domaine, etc.), et d'autre part de relier entre eux les synonymes et les parasynonymes, par exemple, "président (des Etats-Unis en 2015)" et "Barack Obama".
I.3.1.1.3 Établir un lien direct entre les BDLex "métier" et les réseaux lexicaux exprimables en RDF
Les données lexicales sont stockées en XML et traitées avec l'API DOM dans la BDLex de la plate-forme Jibiki. Est-il possible d'implémenter le niveau bas d'une plate-forme comme Jibiki en RDF, et par là d'obtenir un lien direct avec DBnary [Sérasset, G., 2012 ; Sérasset, G. & Tchechmedjiev, A., 2014] ? Cela permettrait aussi sans doute de pouvoir considérer une BDLex quelconque comme un "réseau de neurones de Hopfield", et de l'utiliser directement dans des services de désambiguïsation lexicale (voir I.3.1.2.3 ci-dessous).
I.3.1.2 Trois thèmes concernant la conception de services lexicaux (0,75 p.)
I.3.1.2.1 Offrir des services dictionnairiques en ligne non seulement pour les humains, mais pour des logiciels (aspect SaaS : Software as a Service)
Les services dictionnairiques en ligne pourraient être utilisés par des applications dans plusieurs domaines. Par exemple, une BDLex en PIVAX pourrait être utilisée comme serveur lexical pour des systèmes de TA, pour des systèmes de recherche translingue d'informations (CLIR) comme celui du projet OMNIA, et pour des système de PE (post-édition) contributive en ligne (ex. SECTra/iMAG) et de THAM en général, par production proactive de "mini-dictionnaires" [Huynh, C.-P., 2010].
I.3.1.2.2 Accéder à une ou plusieurs BDLex en utilisant un ou plusieurs services de lemmatisation
Il n'y a pas de service de lemmatisation couvrant tous les mots et termes d'une langue, et d'autre part il y a des lemmatiseurs particulièrement adaptés à certains types de termes (par exemple, les termes techniques en aviation, en agronomie, ou en médecine). On aimerait les mettre en synergie. Comme ils ne fournissent pas leurs résultats dans les mêmes formats, ni même ne sont fondés sur des notions identiques, il faudrait trouver comment "normaliser", puis fusionner ces résultats.
I.3.1.2.3 Offrir un service de support à la désambiguïsation lexicale (WSD)
On a déjà mentionné les travaux de MSR au I.1.3.1.4. MSR a montré comment faire cela vers 1993-96 en implémentant un dictionnaire (en fait, la fusion du Longman Dictionary of Contemporary English et de l'American Heritage Dictionary) comme un grand réseau "neuronal" à la Hopfield. Lors de MIDDIM-96, Bill Dolan a présenté une application de désambiguïsation lexicale basée sur cette ressource, avec la méthode dite de l'amorçage lexical (lexical priming) [Dolan, W. B. & Richardson, S. D., 1996].
Le système HowNet traite la WSD pour
le chinois en utilisant un grand réseau de connaissances générales (plus de 50K
entrées). La méthode est appelée "élagage
de sens basée sur la connaissance".
Cette méthode a été présentée par Chi Yung Wang en 2002 [Gan, K.-W. et al., 2002].
I.3.1.3 Deux thèmes plus liés au GL (0,5 p.)
Si une BDLex fonctionne en serveur lexical pour des programmes, un grand nombre de requêtes pourrait lui être soumis en même temps. Pour mettre en place l'aspect serveur générique, deux problèmes étaient encore ouverts : le passage à l'échelle sans perte d'efficacité, et l'organisation de la gestion des travaux (requêtes et tâches associées).
I.3.1.3.1 Efficacité et passage à l'échelle (les implémentations étaient bien trop lentes)
Concrètement, le problème était d'améliorer les performances de Pivax-1. Dans le cadre du projet OMNIA, H.-T. Nguyen avait importé plus de 848K d'entrées d'UNL dans sa base, et avait essayé de l'utiliser comme serveur lexical, pour produire à partir de la liste des lemmes d'un paragraphe (une légende de 50 mots en moyenne) une petite grammaire en Systèmes-Q réalisant l'ajout des UW à la sortie de NooJ sur ce paragraphe[64]. Mais les temps de réponse étaient beaucoup trop longs, et on avait dû remplacer Pivax par une base de données ad hoc pour réaliser un démonstrateur.
I.3.1.3.2 Gestion des travaux (files d'attente)
Le thème de la gestion des flux numériques en TALN est devenu un domaine reconnu[65]. On a ce besoin pour plusieurs services. Par exemple, SECTra_w [Huynh, C.-P., 2010] appelle Tradoh [Vo-Trung, H., 2004] pour appeler le ou les systèmes de TA fournissant les prétraductions. Si on fait un grand nombre de requêtes en même temps, il y a souvent un problème de décalage, et les prétraductions ne sont pas bien alignées avec les segments source.
On a aussi besoin d'une gestion des travaux en arrière-plan, par exemple, pour créer des mini-dictionnaires. Cong-Phap Huynh a proposé dans sa thèse de construire les mini-dictionnaires (un pour chaque segment contenu dans SECTra) par appel de Pivax, mais il n'a finalement pas pu le réaliser, à cause de plusieurs problèmes techniques, dont la gestion de travaux. Enfin, l'outil SegDoc [Kalitvianski, R., 2013] a été créé principalement par Ruslan Kalitvianski pour segmenter de grands documents, et lui aussi a besoin d'une fonction de gestion de files d'attente.
I.3.2 Thèmes retenus (1 p.)
Il n'était pas possible de traiter tous ces thèmes dans le cadre d'une thèse. D'autre part, il fallait considérer les besoins de L&M, les intérêts du laboratoire, ainsi que mes intérêts et compétences propres, sachant que je venais d'un master en génie informatique et pas en linguistique ou en sciences cognitives.
Finalement, 4 thèmes ont été retenus : (1) la conception de BDLex unifiant tous les types d'unités lexicales, (2) la réalisation d'un service générique de création de mini-dictionnaires à partir de BDLex, (3) la conception et l'implémentation d'un intergiciel de lemmatisation, et (4) la recherche et l'intégration d'un système de gestion de tâches "linguicielles" entre serveurs ou agents à gros grain.
I.3.2.1 Conception d'une BDLex unifiant tous les types d'unités lexicales (générales, terminologiques, situées et très situées)
Au début de ma thèse, L&M m'a demandé d'étudier l'intégration de la gestion des acronymes dans la base terminologique de Libellex. Donc j'ai travaillé sur ce thème à cause de ce besoin industriel. Avec la conception d'une BDLex "métier", on peut organiser et gérer les différents types d'unités lexicales, y compris les plus récemment traités comme les prolexèmes dans une même BDLex de Pivax.
La première version de Pivax ne pouvait pas implémenter ce type de BDLex, ce qui m'a amenée à produire avec M. Mangeot une nouvelle version de Pivax, Pivax-2, avec l'idée de représenter des annotations sémantiques ou d'autres annotations par des liens étiquetés libres. Le problème a été complètement résolu au niveau du laboratoire, et seulement incomplètement pour L&M, car il était impossible de modifier suffisamment le module Libellex-termino.
I.3.2.2 Réalisation d'un service générique de création de mini-dictionnaires pour SECTra à partir d'une BDLex en Jibiki
Nous ne nous sommes pas limitée à achever le travail
commencé par C. P. Huynh et H. T. Nguyen, qui concernait exclusivement SECTra et PIVAX. Nous avons voulu concevoir et construire un
outil générique de type SaaS destiné à la création de
mini-dictionnaires à partir d'une base lexicale quelconque en Jibiki-2.
Concrètement, CreatDico est un serveur paramétrable qui
est un intergiciel de service dictionnairiques.
I.3.2.3 Conception et implémentation d'un intergiciel de lemmatisation
Pour la consultation d'une forme d'un mot, et a fortiori pour la création d'un mini-dictionnaire à partir d'un fragment de texte, il est nécessaire, pour la plupart des langues, de commencer par lemmatiser la ou les formes en argument, ce qui peut exiger une étape préalable de segmentation (par exemple en chinois). Or, jusqu'ici, la lemmatisation était implémentée de façon ad hoc. Par exemple, Papillon-CDM offre la recherche avec lemmatisation en français, mais cette fonction n'est pas disponible dans les autres bases lexicales construites sur Jibiki-1.
C'est pourquoi nous avons conçu et réalisé un intergiciel de lemmatisation, Lextoh, qui intègre les services des lemmatiseurs, des segmenteurs et des racineurs disponibles, pour un nombre de langues inconnu a priori. D'autre part, Lextoh permet d'accéder à une ou plusieurs BDLex en utilisant un ou plusieurs services de lemmatisation.
Cet outil pourrait être utilisé pour développer des systèmes Moses (ex. Moses-LIG) pour créer les corpus d'apprentissage nécessaire à la mise en œuvre de l'approche vectorielle[66] pour la segmentation et l'annotation de corpus, pour la consultation dictionnairique avancée (ex. dans les instances de Jibiki), et pour la création de mini-dictionnaires (envoyant des appels à CreatDico).
I.3.2.4 Recherche et intégration d'un système de gestion de tâches entre serveurs ou agents à gros grain
Comme dit plus haut, c'est une partie du thème des "flux numériques en TALN", qui est devenu un domaine reconnu. Nous nous en sommes rendu compte à cause de notre étude sur MeTRICC, qui nous a fait étudier UIMA[67], qui permet de gérer les flux de ressources et les flots de données linguistiques.
On a besoin d'une fonction de gestion des travaux pour tous les outils de notre architecture d'accès multilingue et de traduction avec post-édition contributive. Par exemple, SECTra en a besoin pour les appels de Tradoh pour les prétraductions. Pivax en a besoin pour toutes les demandes de services dictionnairiques. Lextoh en a besoin pour les appels à des services de lemmatisation, etc.
Pendant le projet Traouiero (2011-2012),
notre équipe avait prévu de développer un tel outil, par extension et
adaptation de Blexisma, mais cela n'avait pas pu
être fait, l'unique personne compétente étant prise sur un autre projet.
Nous avons cherché à considérer ces quatre thèmes selon trois
axes : la demande industrielle, un nouvel apport pour la recherche, et le
développement d'offres de services.