Chapitre II Extensions fonctionnelles et opérationnelles : de Pivax-1 à Pivax-2 (22 p.)
Introduction (0,5 p.)
Pour améliorer la première version de Pivax, il fallait d'abord passer à l'échelle, et ajouter certaines fonctionnalités. Par exemple, au niveau de Jibiki, on n'avait pas de fonction générique de recherche avec lemmatisation préalable, et on ne pouvait pas choisir le(s) volume(s) cible(s). D'autre part, on avait essayé d'utiliser Pivax-1 dans le projet OMNIA, en lui faisant produire une "grammaire-Q" réalisant l'annotation des mots d'un paragraphe par des UW UNL. Mais Pivax-1 était trop faible pour des applications "programmatoires" de ce type. Il fallait aussi augmenter la vitesse de recherche en consultation humaine.
Pour améliorer Pivax-1, nous avons travaillé (1) sur le niveau sous-jacent, c'est-à-dire sur la plate-forme Jibiki, et (2) sur l'extension du type "Pivax" de BDLex.
Le premier travail (avec M. Mangeot) au niveau de la plate-forme Jibiki de construction de BDLex "métier" contributives, a été un travail préliminaire et plutôt technique, mais le présenter permet de comprendre les méthodes et techniques sur lesquelles Jibiki s'appuie (par exemple, le "tout XML"), les fonctionnalités introduites à ce niveau (par exemple, liste non bornée, appel des lemmatiseurs de façon générique, choix des volumes cibles), sans devoir écrire du code spécifique pour chaque type de BDLex construite avec Jibiki-2.
Au niveau de BDlex, on a réimplémenté Pivax-1 en utilisant Jibiki-2. Cette partie a permis de trouver comment mettre réellement à disposition "de la communauté" les ressources lexicales rassemblées dans Pivax-1 par le projet ANR Traouiero et dans le cadre d'une coopération CNRS-ANR avec l'IPPI.
Ce chapitre est divisé en quatre sections : (1)
présentation de Jibiki-1, (2) présentation de Pivax-1, (3) extensions fonctionnelles apportées par le
passage à Jibiki-2, et (4) Pivax-2 :
opérationnalisation et extension de Pivax-1.
I.1 Jibiki-1 (4,5 p.)
I.1.1 Présentation de Jibiki-1
On a mentionné la plate-forme Jibiki aux I.1.3.2.3 et I.1.4.3. Elle a été produite suite aux évolutions du projet Papillon (deux types différents de BDLex, celui de Papillon-CDM, et celui de Papillon-Nadia), dans le but de faciliter la création de BDLex de types variés. Le but initial de Jibiki était donc de séparer un système de gestion de BDLex en deux parties : une partie logicielle commune et une partie spécifique à chaque type différent de BDLex.
Cette plate-forme générique permet la construction de sites Web contributifs dédiés à la construction de bases lexicales multilingues. Elle offre deux interfaces : des formulaires Web pour les humains, et une API REST pour les programmes. Les manipulations des ressources par ces interfaces sont enregistrées directement dans la BDLex.
Le code est disponible en source ouvert et téléchargeable gratuitement par SVN sur https://ligforge.imag.fr/projects/jibiki/.
I.1.2 Architecture de Jibiki-1 (1,5 p.)
I.1.2.1 Spécification (0,75 p.)
La plate-forme Jibiki permet de traiter presque toutes les ressources lexicales de type Xml contenant différentes microstructures et macrostructures.
Jibiki offre de nombreuses fonctionnalités prêtes à l'emploi : import d'un dictionnaire ou d'un volume, création et édition d'entrées, gestion des contributions par l'administrateur, et recherche dans les bases lexicales.
Il y a trois types de recherche : (1) la recherche simple, par mot-vedette et langue source, (2) la recherche par parcours d'un volume, similaire à la consultation d'un dictionnaire papier, et (3) la recherche avancée, qui permet de consulter un mot en précisant une ou plusieurs conditions. Chaque condition est une combinaison de trois éléments : un attribut (ex. le mot-vedette, la variante, la date de création, la date de modification, le statut, l'identifiant etc.), un opérateur (ex. égale, commence par, plus grand que, plus petit que, etc.) et une variable. Par exemple,
|
mot-vedette commence par
"dicti" & dictionnaire est "FeM" & langue source est "français" & variante est "dico" & date de création est après le "11/10/2013" & date de création est avant le "11/10/2015" |
Pour importer un nouveau dictionnaire dans une BDLex de Jibiki, on n'a pas besoin de modifier les programmes, mais la ressource lexicale doit être en Xml, et on doit préparer un certain nombre de fichiers.
1. Le fichier de métadonnées du dictionnaire est le descripteur de sa macrostructure (description des volumes du dictionnaire et de leurs relations).
2. Il y a un fichier de métadonnées pour chaque volume, spécifiant les chemins des informations relatives dans Xml en utilisant XPath. Ces informations relatives sont reliées aux pointeurs CDM (voir la Définition 16). Ce fichier permet d'aligner la microstructure de chaque volume avec la microstructure CDM.
3. Un fichier XSD[1] définit la structure XML attendue en entrée ; ce fichier permet de créer automatiquement l'interface d'édition sur le Web.
4. Optionnellement, un formulaire XHTML permet de définir une interface d'édition spécifique. La plate-forme Jibiki peut créer une interface spécifique en utilisant le fichier XSD, mais créer une interface spécifique pour un certain type d'utilisateur permet d'améliorer l'interaction.
5. On peut associer une feuille de style en XSL[2] à un volume ou à un dictionnaire ; elle permet de personnaliser l'affichage de consultation.
6. Ces fichiers peuvent être préparés automatique avec iPoLex[3].
I.1.2.2 Implémentation (1 p.)
On a déjà mentionné l'architecture de Jibiki et son environnement de développement au I.1.4.3. Son architecture à trois couches facilite l'ajout et la modification des interfaces pour une nouvelle instance. Elle permet aussi de s'abstraire de la manière dont les données sont stockées.
Pour gérer les différentes microstructures, M. Mangeot a créé une microstructure virtuelle en CDM. Pour chaque pointeur CDM, on indique le chemin XPath vers l'élément correspondant dans la microstructure Xml. La Figure 10 donne un exemple d'une entrée en Xml et le contenu des éléments Xml correspondants.
|
<g:volume> <g:article
g:id="fra.instruction.1847645">
<g:vedette> <g:h-aspire>false</g:h-aspire> <g:mot>instruction</g:mot> <g:prononciation>\ɛ̃s.tʁyk.sjɔ̃\</g:prononciation> <g:grammaire> <g:cat-gram>s.</g:cat-gram> <g:genre-nbr>f</g:genre-nbr> </g:grammaire> </g:vedette> </g:article> </g:volume> |
|
<cdm-elements> <cdm-volume xpath="/g:volume"/> <cdm-entry xpath="/g:volume/g:article"/> <cdm-entry-id xpath="/g:volume/g:article/@g:id"/> <cdm-headword xpath="/g:volume/g:article/g:vedette/g:mot/text()" d:lang="fra"/> <cdm-pronunciation xpath="/g:volume/g:article/g:vedette/g:prononciation/text()" d:lang="fra"/> <cdm-pos xpath="/g:volume/g:article/g:vedette/g:cat-gram/text()" d:lang="fra"/> </cdm-elements> |
Figure 10 : Exemple d'utilisation de CDM
Les CDM permettent d'importer directement un nouveau dictionnaire sans le modifier, pourvu qu'il soit en XML. Voir la Table 2.
Table 2 : Valeurs de pointeurs CDM dans différents dictionnaires
|
Dictionnaire Pointeur |
FeM |
OHD[4] |
JMdict[5] [Breen, J., 2004] |
|
Volume |
/volume |
/volume |
/JMdict |
|
Entry |
/volume/entry |
/volume/se |
/JMdict/entry |
|
Entry ID |
/volume/entry/@id |
|
/JMdict/entry/ent_seq/text() |
|
Headword |
/volume/entry/headword/text() |
/volume/se/hw/text() |
/JMdict/entry/k_ele/keb/text() |
|
Pron |
/volume/entry/prnc/text() |
/volume/se/pr/ph/text() |
|
|
PoS |
//sense-list/sense/pos-list/text() |
/volume/se/hg/ps/text() |
/JMdict/entry/sense/pos/text() |
|
Domain |
|
//u/text() |
|
|
Example |
//sense1/expl-list/expl/fra |
//le/text() |
/JMdict/entry/sense/gloss/text() |
I.1.3 Types de BDLex déjà développés en Jibiki-1 en 2011 (2,5 p.)
Nous avons déjà mentionné ces projets au I.2.1.1.
Nous présentons ici plus en détail leur macrostructure et leur microstructure.
I.1.3.1 Papillon
On a déjà mentionné les structures de deux sous-projets (Papillon-Nadia et Papillon-CDM) au I.1.3.2.3.
Le projet NADIA [Sérasset, G., 1994a], lancé au GETA à la suite du projet Multilex ESPRIT, a pour but de construire une BDLex pour les dictionnaires de TALN et de TA. Sa macrostructure est Pivot.
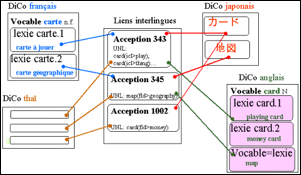
La microstructure d'un volume est définie par un schéma Xml spécifique avec variantes. Ces schémas Xml redéfinissent l'élément "article" du schéma DML (Dictionary Markup Language)[6]. Par exemple, on doit redéfinir la liste des catégories pour chaque volume : le thaï n'a pas d'adjectifs, le japonais en distingue plusieurs, etc. Voici un morceau du schéma spécifique au japonais pour la redéfinition des catégories et un exemple d'une lexie.
|
Figure 11 : Macrostructure du dictionnaire Papillon-Nadia |
|
Schémas Xml spécifique redéfini |
Entrée |
|
<redefine schemaLocation="papillon.xsd"> <simpleType name="posType"> <restriction base="dml:posType"> <!-- settôgo, prefix --> <enumeration value="接頭語"/> <!-- setsubigo, suffix --> <enumeration value="接尾語"/> <!-- zôgoseibun, productive element -->
<enumeration value="造语成分"/> <!-- meishi, noun --> <enumeration value="名词"/> <!-- keishikimeishi, formal noun -->
<enumeration value="形式名词"/> ... </restriction> </simpleType> </redefine> |
<lexie id="洗う$1" basic="true">
<headword hn="1">洗う</headword> <kun-yomi>あらう</kun-yomi> <pos>他動詞</pos> <language-levels> <politeness grade="neutral"/> <usage grade="NA"/> <reference grade="NA"/> </language-levels> ... </lexie> |
Figure 12 : Exemple de microstructure du projet Papillon-Nadia
Quant au projet Papillon-CDM [Boitet, C. et al., 2002], on a mentionné sa macrostructure au I.1.3.2.3 et I.1.4.2, et sa microstructure au I.1.4.2 et II.1.2.2. Pour les exemples, voir la Figure 10 et la Table 2.
I.1.3.2 LexAlp
LexAlp [Sérasset, G. et al., 2006 ; Sérasset, G., 2008] a été motivé par trois raisons principales :
1) un même mot représente différents concepts
juridiques,
2) on utilise des mots différents pour
représenter le même concept,
3) une traduction générale directe peut
représenter un concept juridique différent de celui associé au mot source.
Au niveau de l'implémentation, G. Sérasset a choisi une
macrostructure Pivot, bien adaptée au fait qu'un
concept peut être exprimé par plusieurs termes dans une même langue, et qu'un terme peut représenter plusieurs concepts
dans une même langue. Voir la Figure 13. Tous les volumes monolingues partagent une
même microstructure en Xml. Dans le volume des axies, chaque axie peut
être reliée à plusieurs entrées monolingues grâce à un élément (termref) et à d'autres acceptions interlingues grâce à un
autre élément (axieref). On trouvera
des exemples de microstructure dans l'Annexe 5.
|
|
|
|
Un même
concept est représenté par plusieurs termes dans une même langue |
Un
même terme dans une même langue représente plusieurs concepts[7] |
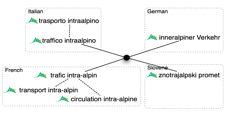
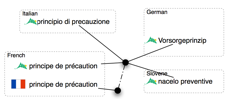
Figure 13 :
Structure de terminologie de LexAlp
I.1.3.3 GDEF
Contrairement aux deux premiers projets, GDEF utilise une macrostructure directe. Il s'agit d'un dictionnaire bilingue. Dans ce type de BDLex, on a souvent deux volumes bilingues : un volume langue A (LgA) → langue B (LgB) et un volume miroir LgB → LgA. Cette macrostructure ressemble à un dictionnaire bilingue imprimé.
Dans le cadre du projet GDEF, on a un seul sens (est→fra) mais deux volumes monolingues : un volume estonien et un volume français. Il n'y a pas de volume d'axies. On a des liens du volume estonien vers le volume français, mais pas l'inverse.
Les entrées du volume estonien contiennent :
· l'essentiel des informations estoniennes,
· certaines gloses françaises (voir ci-dessous),
· certains liens vers leurs équivalents français (voir ci-dessous),
· des exemples estoniens et français.
Les traductions des articles estoniens sont réalisées par des liens vers le volume français, qui est le "PC data" d'un nœud <g:mot-princ>. Les gloses précisant les sens du mot sont marquées par les balises <g:avant> (mot ou terme précédant le mot-vedette de la traduction française) et <g:après> (mot ou terme suivant le mot-vedette de la traduction française).
Le volume français ne contient que les mots-vedettes et les informations grammaticales du français (ex. genre des substantifs, pluriels irréguliers des substantifs et des adjectifs, féminins irréguliers des adjectifs, h aspiré, etc.).
Par exemple, le mot jõevesi en
estonien se traduit par eau en français. Plus précisément,
il s'agit de l'eau d'une rivière ou d'un fleuve.
|
Figure 14 : Un article du GDEF et sa structure Xml |
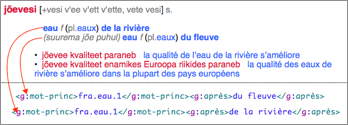
I.1.3.4 MotÀMot
Ce projet a été conçu au départ pour construire à terme une base lexicale de toutes les langues d'Asie du Sud–Est. La base actuelle contient pour l'instant des données dans seulement deux langues, le khmer et le français, avec une macrostructure Pivot (un volume d'axies). Tous les volumes sont stockés en Xml.
Pour la microstructure, chaque entrée est un vocable qui regroupe des lexies. Une entrée se compose d'un mot-vedette, d'une prononciation, de la catégorie grammaticale, et d'une liste de lexies.
Chaque lexie est décrite par une formule sémantique (voir l'exemple ci-dessous) ou par une glose libre. Il y a un lien vers une entrée (une axie) du volume pivot. Il y a aussi parfois un domaine, une liste d'exemples, des expressions idiomatiques, et un champ générique utilisé pour stocker des informations supplémentaires.
La Figure 15 reprend un exemple donné dans [Mangeot, M. & Nguyen, H. T., 2009]. Il y a un seul sens pour cet article abandonner, caractérisé par une formule sémantique (par exemple, action sur un objet : humain ou animal X ~ entité Y) et une glose libre (laisser tomber quelque chose).
La microstructure du volume pivot est très simple : une entrée axie contient un ensemble de liens vers des entrées des volumes monolingues. En cas de synonymie, il peut y avoir plusieurs liens d'une axie vers le même volume monolingue.
|
Figure 15 : Article abandonner dans MotÀMot |
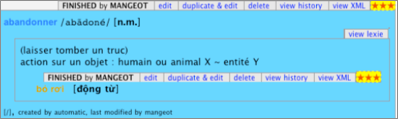
I.1.3.5 Pivax-1
Comme nous voulons présenter Pivax-1 de façon très détaillée, nous lui consacrons toute une section.
I.2
Pivax-1
Pivax-1 [Nguyen,
H.-T. et al., 2007] est une
nouvelle macrostructure à trois niveaux, définie et implémentée par H.-T.
Nguyen dans le cadre de sa thèse [Nguyen, H.-T., 2009]. Elle permet d'implémenter plusieurs volumes
monolingues pour chaque langue naturelle ou artificielle. Son implémentation a
été basée sur Jibiki-1.
I.2.1 Motivations (0,5 p.)
Nous citons ici [Nguyen, H.-T., 2009] : Ce projet a été motivé par les besoins de partage de données lexicales de systèmes de TA. Ce besoin vient du désir d'utilisateurs de systèmes commerciaux comme SYSTRAN, Reverso, METAL, etc. de partager leurs dictionnaires entre eux et entre systèmes[8]. Cependant, l'information lexicale à partager est limitée à cause de la protection de propriété pour des ressources importantes qui coûtent cher à développer, donc l'effort de ce côté-là n'a pas tout à fait réussi. La solution proposée repose sur l'idée d'avoir plusieurs volumes par espace lexical d'une langue. En plus, on souhaite développer une BDLex universelle pour tous les systèmes de TA, avec des architectures linguistiques arbitraires, mais c'est très difficile à réaliser, parce que les types d'information et leur organisation sont trop différents. Donc nous limitons le problème à la classe des systèmes de TA utilisant un même "espace lexical pivot". C'est pourquoi nous avons conçu et développé Pivax-1, un système contributif en ligne de BDLex qui permet de créer, maintenir et gérer les ressources lexicales de systèmes de TA basés sur un "pivot lexical".
I.2.2 Structure de Pivax-1 (1,5 p.)
On présente la macrostructure et la microstructure de Pivax-1 avec les exemples présentés dans [Nguyen, H.-T., 2009].
I.2.2.1 Macrostructure (0,5 p.)
La macrostructure de Pivax-1 contient trois types de volumes: lexie, axème et axie.
Pour chaque langue naturelle présente ou chaque interlingua, on a un ou plusieurs volumes de lexies et leurs informations associées, et un unique volume d'axèmes. Une lexie correspond à un sens de mot dans un dictionnaire. Le terme "axème" est construit à partir de "acception" et "monolingue", mais en fait un axème relie des lexies synonymes dans une même langue, tandis qu'une acception (monolingue) correspond à un sens "en usage" ou "dans la langue". Dans la BDLex, il y a un volume unique d'axies (acceptions interlingues). Une axie relie des axèmes correspondant à des sens équivalents.
|
|
|
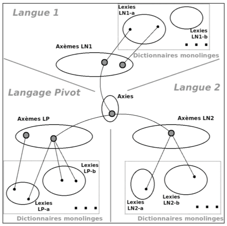
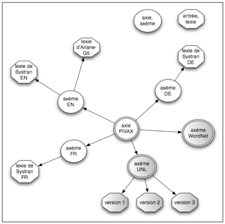
Figure 16 : Macrostructure de Pivax et exemples de volumes
I.2.2.2 Microstructure (1 p.)
Les axèmes et axies sont simplement des liens, qui sont représentés chacun par l'ensemble des identificateurs de lexies ou axèmes correspondants.
Pour simplifier la programmation, on impose en Pivax une même microstructure pour tous les volumes d'un même espace lexical.
Dans les volumes de LN, une entrée contient un lemme, sa classe (POS), son identificateur de sens de mot (le cas échéant), un commentaire (pour les autres développeurs) et le détail approprié de l'information propre à chaque volume et ses codes. Chaque entrée peut contenir des métadonnées (la date de modification, l'auteur, l'état de traitement, le niveau de protection, définissant les parties accessibles par le public : droit d'écriture, de lecture et d'exécution).
|
<d:data> <p:lexie p:id="lexie.systran.test.12004" p:process_status="UNPROCESSED" p:status="UNKNOWN" p:owner="Systran" p:score="0.00003"> <p:lemma p:access="Public">fier</p:lemma> <p:class p:access="Public">Adj</p:class> <p:comment>
"fier" can also be a V ("se fier à") </p:comment> <p:proper_information
p:access="Hidden"> /* Systran proprietary codes */ </p:proper_information> </p:lexie> </d:data> |
Pour les volumes interlingues (volumes d'UW, volumes implémentant une ontologie), les entrées sont toujours définies au niveau sémantique, et peuvent donc toujours être appelées "lexies". Plus précisément, la microstructure d'un volume d'UW (lexèmes interlingues d'UNL) se compose de : mot-vedette, contenu, définition, exemples, note et autre information[9].
|
<uw id="unl.upp.abandon.7" status="UN_KNOWN"> <headword>abandon</headword> <pos>VERB</pos> <content>abandon(icl>do,
agt>thing, obj>thing)</content> <definition>stop
maintaining or insisting on </definition> <examples>
<example>of ideas or claims</example>
<example>He abandoned the thought of asking for her hand in
marriage</example>
<example>Both sides have to abandon some claims in these
negotiations</example> </examples> <more-info>
<info> </info> </more-info> </uw> |
|
<cdm-elements> <cdm-volume
xpath="/unl_volume"/> <cdm-entry
xpath="/unl_volume/uw"/> <cdm-entry-id
xpath="/unl_volume/uw/@id"/> <cdm-headword
xpath="/unl_volume/uw/headword/text()" d:lang="unl" index="true"/> <cdm-pos
xpath="/unl_volume/uw/pos/text()" d:lang="unl"/> <cdm-definition
xpath="/unl_volume/uw/content/text()" d:lang="unl" index="true"/> <cdm-example
xpath="/unl_volume/uw/examples/example/text()" d:lang="unl"/> </cdm-elements> |
Figure 17 : Exemple d'un volume UNL de Pivax-1 et de ses pointeurs CDM
I.2.2.3 Algorithme de calcul des liens (0,5 p.)
H.-T. Nguyen a créé des liens d'axies vers axèmes et d'axèmes vers lexies, mais pas dans les directions inverses. Dans Pivax-1, il n'y a donc pas de liens à partir des volumes de lexies. Dans son implémentation de l'algorithme de calcul des liens de la Figure 18, il a créé quatre méthodes différentes pour trouver les traductions d'une entrée source (lexie source).
1. getAxemesPointingTo : trouver les axèmes par les lexies dans les tables des pointeurs d'axèmes.
2. getAxisPointingTo : trouver les axies par les axèmes dans les tables des pointeurs d'axies.
3. findAxemeByAxie : trouver les axèmes par les axies dans les tables des pointeurs d'axies.
4. findLexieByAxeme : trouver les lexies par les axèmes dans les tables des pointeurs d'axèmes.
|
Figure 18 : Algorithme de calcul des liens dans Pivax-1 |

I.2.2.4 Interface (0,5 p.)
Cette interface de
consultation en colonnes a été inspirée par Parax (voir
I.1.4.1).
Elle permet de modifier la largeur de chaque colonne (par – et +)
et de changer l'ordre des colonnes (par < et >).
Les entrées reliées à une même axie ou à un même axème sont présentées en leur
affectant une même couleur.
|
Figure 19 : Interface de consultation en colonnes de Pivax |
I.2.2.5 Début de programmabilité (2 p.)
L'objectif à long terme est de transformer Pivax-1 en un EDL (Environnement de Développement Linguiciel) avec certains LSPLex (Langage Spécialisé pour la Programmation Lexicale). Les utilisateurs (non-informaticiens) pourraient programmer des tâches spécifiques selon leurs besoins. H.-T. Nguyen a proposé un langage narratif [Bellynck, V., 2001] pour la manipulation des graphes lexicaux. Ce langage offre des opérations simples pour créer ou supprimer des objets (lexie, axème, axie et les liens). Il permet également de définir des macros pour grouper des suites d'opérations. Par exemple,
|
Simple : Créer_nœud (entrée, type, méta-données) ; Créer_lien (entrée_1, entrée_2, alias) ; entrée = entrée dans un volume de PIVAX ; type = lexie | axème | axie ; méta-données = suite_d_attributs_valeurs ; suite_d_attributs_valeurs ( ( attribut
= valeur ;) ? attribut = valeur ; ) Supprimer_nœud (entrée); Supprimer_lien (entrée_1, entrée_2); Macro : NOM_DE_MACRO (parametres) (variables locales) { Suite_d_opérations_simples;
} Suite_d_opérations_simples { (Simple
?;) Simple; } |
H.-T. Nguyen a spécifié une interface Web pour visualiser directement ces manipulations sur les graphes lexicaux (on a les graphes initiaux, ensuite on peut programmer et mettre à jour la programmation, puis on obtient les graphes finals), mais il n'a pas eu le temps de les implémenter.
H.-T. Nguyen a aussi proposé un algorithme global pour unifier les UW d'UNL. Comme écrit plus haut, les UW sont créés par différents groupes, et du coup on a souvent des UW différents pour la même "acception interlingue". Par exemple :
· access(icl>reach>do, agt>thing, obj>thing) dans le volume U++C
· access(icl>reach, agt>thing, obj>thing) dans le volume UNLKB.
Son algorithme est basé sur trois niveaux de comparaison : seulement le mot-vedette, le mot-vedette et les restrictions, les informations spécifiques (pas implémenté).
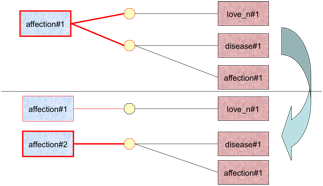
D'autre part, H.-T. Nguyen a prototypé trois "règles de transformation" que M. Mangeot avait spécifiées dans sa thèse [Mangeot, M., 2001] en 2001 et que Ch. Boitet avait détaillées au séminaire du projet Papillon en 2005 [Boitet, C., 2005]. Ces règles ont pour but de restaurer la cohérence dans une BDLex de type Papillon-Nadia. Par exemple, une lexie ne peut pas être reliées à deux axèmes ou axies différents. Pour ce cas, on a trois actions possibles :
· Division de lexie (L1—(A1,A2) → L1-A1; L2-A2)
|
|
· Fusion de deux axies (L1—(A1,A2) → L1 —(A1+A2))
|
|
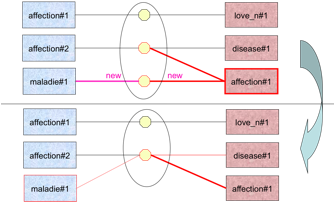
· Création d'une autre axie et d'une lexie de plus (L1—(A1,A2) → L1-A3 ; L2—A2 ; ako((A1,A2), A3))
|
|
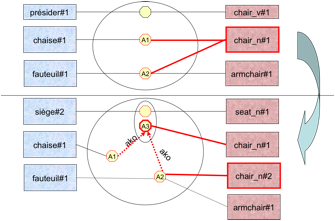
I.2.3 Utilisations de Pivax-1 (2 p.)
I.2.3.1 Dans OMNIA (1 p.)
Dans le cadre du projet ANR OMNIA [Rouquet, D. & Nguyen, H. T., 2009], Pivax-1 a été utilisé pour construire une "mini-grammaire" en systèmes-Q à partir d'une liste de lemmes.
|
Figure 20 : Processus de traitement du projet OMNIA |
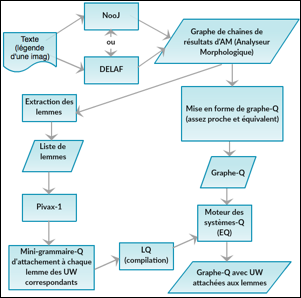
On lemmatise d'abord les textes source en utilisant NooJ ou Delaf, puis on annote les textes lemmatisés par des lexèmes interlingues, qui sont les UW d'U++C construits à partir de WordNet.
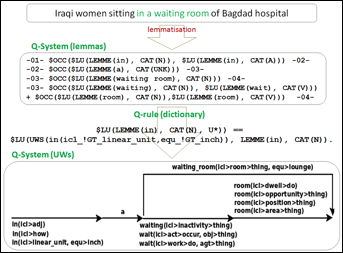
Il s'agit non seulement de mots simples, mais aussi de mots composés. Par exemple, la suite de mots waiting room peut être segmentée de 3 façonss : waiting, room, waiting room. Après la lemmatisation, on transforme le résultat en graphe-Q, qui est un format compact d'échange de résultats multiples de lemmatisation. Voir la Figure 21.
Les lemmes trouvés (simples et composés) sont envoyés à Pivax-1, qui produit un dictionnaire lemmes-UW pour ce graphe-Q sous forme de règles-Q. L'étape suivante consiste à appliquer ce dictionnaire au graphe des lemmes, ce qui produit un graphe-Q contenant le graphe des lemmes, et de nouveaux arcs (et arbres) contenant une représentation des UW trouvés.
Dans cette application, Pivax-1 fonctionne comme un serveur lexical qui produit un ensemble "d'articles" des UW sous la forme spécifique de règles-Q, pour chaque mot envoyé par le module d'annotation d'OMNIA.
I.2.3.2 Dans Traouiero et GBDLex-UW++ (1 p.)
|
Figure 21 : Exemple d'annotation de texte dans OMNIA |
Pendant sa thèse, H.-T. Nguyen a utilisé Pivax-1 pour en faire le support du projet U++C. Il a importé plusieurs ressources dans cette BDLex.
Table 3 : Ressources importées dans Pivax-1 par H.-T. Nguyen
|
Ressource |
Type/Langue
|
Nombre des
entrées |
|
UNL-Deco |
UNL-FRA |
39 389 |
|
PARAX |
UNL-FRA |
18 978 |
|
PARAX |
UNL-CHN (données par le Pr. Shi en 2001) |
9 315 |
|
PARAX |
UNL-RUS |
13 817 |
|
PARAX |
UNL-ESP |
3 833 |
|
UNLKB |
UNL |
21 618 |
|
UPM UW++ |
UW avec définition et exemples |
207 009 |
|
UNDL |
Projet EOLSS-UNL-FR/UW |
21 354 |
|
IATE |
Projet EOLSS/ENG, termes correspondant aux 21K UW récupérés par Robodico |
255 305 |
|
IATE |
Projet EOLSS/FRA, termes correspondant aux 21K UW récupérés par Robodico |
258
175 |
La sous-tâche 4.4 GBDLex-UW++ du projet Traouiero avait pour but la construction d'une grande base lexicale avec lexèmes interlingues. Pendant ce projet, on a principalement construit deux ressources d'UW.
La ressource CommonUNLDict a été créée par le lexicographe et linguiste russe Vyacheslav Dikonov. Le type de BDLex de cette ressource (la macrostructure) est Pivax-1. Il y a trois types d'entrées (vocables, axèmes et axies), et 720 K entrées au total. CommonUNLDict contient 8 langues (7 langues naturelles : français, anglais, hindi, malais, russe, espagnol, vietnamien et le langage UNL) et 17 volumes (8 volumes de données monolingues, 8 volumes d'axèmes monolingues et 1 volume d'axies "acceptions interlingues").
Tous les volumes d'un même type (vocable, axème et axie) ont la même microstructure. Ces structures ont été définies par V. Dikonov. Cette microstructure est différente de celle définie dans Pivax-1.
|
<p:vocable
p:id="fra.Anglais.n"> <p:lemma>Anglais</p:lemma> <p:pronunciation>ɑ̃.ɡlɛ</p:pronunciation> <p:pos>n</p:pos> <!-- Sens : Relatif à l'Angleterre ou à ses habitants.-->
<p:lexie p:id="CommonUNLDict.lexie.fra.Anglais.1"> <p:entryref
type="axeme" volume="CommonUNLDict_fra-axemes" p:idref="CommonUNLDict.axeme.fra.englishman(icl>english>person)" lang="FRA" p:relation-mono="OTHER"/> <p:processors> <p:processor
p:name="Ariane" p:access="Public"> <p:procref
type="entry" id="Anglais" var="CAT(CATN),GNR(MAS,FEM),N(NP)" lang="FRA"/> </p:processor> </p:processors> </p:lexie> <!-- Sens : Relatif à la langue
anglaise.--> <p:lexie p:id="CommonUNLDict.lexie.fra.Anglais.2"> …… </p:lexie> </p:vocable> |
La Figure 22 illustre la microstructure d'un volume monolingue. Chaque entrée de vocable permet de décrire toutes les informations détaillées, comme la partie du discours (POS), la prononciation, etc. Chaque vocable comprend une ou plusieurs lexies. Dans cette microstructure, l'attribut entryref permet de gérer les liens entre les lexies et les axèmes.
|
Figure 22 : Microstructure de volume monolingue de CommonUNLDict |
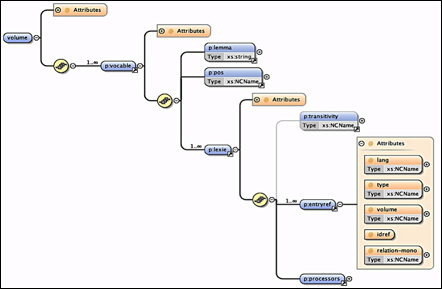
La microstructure des volumes d'axèmes permet de décrire les liens avec les entrées de type lexie et les liens avec les entrées de type axie.
La microstructure des axies permet de décrire les liens avec les entrées de type axème.
Une autre ressource est UWpedia, créée par David Rouquet à partir de DBpedia. Cette ressource contient trois langues naturelles (français, russe, espagnol) et le langage UNL, avec 9M entrées au total. Sa macrostructure est la même que celle de Pivax-1. Les microstructures sont simples.
Pour un volume
monolingue, elle consiste en une lexie, un lemme, un lien vers des axèmes.
Pour un volume axème et axie, elle
ne consiste qu'en des liens.
<p:vocable p:id="fra.Agriculture_de_précision"> <p:lemma>Agriculture
de précision</p:lemma> <p:entryref type="axeme"
volume="UNL-UWpedia-FRA-axeme"
lang="FRA"
p:idref="http://uwpedia.org/fraaxeme/Precision_agriculture/Agriculture
de précision" p:relation-mono="OTHER" /> </p:vocable> |
|
<p:axie p:id="http://uwpedia.org/axie/Carlo_Sforza"
lang="UNL" p:writtenForm="Carlo_Sforza(iof>prime_minister)" unl:masterDef="Carlo_Sforza(iof>prime_minister{(icl>politician)})"> <p:entryref type="axeme"
volume="UNL-UWpedia-Axemes" p:idref="http://uwpedia.org/unlaxeme/Carlo_Sforza"
lang="unl"/> <p:entryref type="axeme"
volume="UNL-UWpedia-FRA-axeme"
p:idref="http://uwpedia.org/fraaxeme/Carlo_Sforza/Carlo
Sforza" lang="fra"/> <p:entryref type="axeme"
volume="UNL-UWpedia-RUS-axeme"
p:idref="http://uwpedia.org/rusaxeme/Carlo_Sforza/Сфорца,
Карло" lang="rus"/> <p:entryref type="axeme"
volume="UNL-UWpedia-ESP-axeme"
p:idref="http://uwpedia.org/espaxeme/Carlo_Sforza/Carlo
Sforza" lang="esp"/> </p:axie> |
Figure 23 : Exemples d'articles de UWpedia
Pour le nombre d'entrées de ces deux ressources, voir II.4.2.1. On a prévu une BDLex de Pivax-1 qui contient ces données. Finalement, à cause de problèmes techniques (voir II.2.4), on n'a pas pu importer ces deux grosses ressources dans Pivax-1 (on les a par contre importées dans Pivax-2, voir II.4.3).
Grâce à l'organisation de la base Pivax comme un grand réseau lexical, avec plusieurs volumes monolingues et un volume d'axèmes par "espace lexical", et un volume central d'axies, on pourra produire de nouveaux dictionnaires à partir des anciens dictionnaires bilingues par constructions d'axèmes et d'axies.
I.2.4 Qualités et limitations (0,5 p.)
Au début de cette thèse, il n'existait pas de serveur Pivax-1 réellement utilisable. Après les expériences dans le projet OMNIA, le temps de réponse de Pivax-1 pour un grand nombre de requêtes n'était pas satisfaisant. D'autre part, H.-T. Nguyen avait discuté les idées de la programmabilité de Pivax par un linguiste-lexicographe-informaticien dans sa thèse, mais il manquait quand même des opérations pour des tâches spécifiques, par exemple, une sortie de mini-dictionnaire spécifique.
Par contre, PIVAX-1 est le premier
système contributif de base de données lexicales en ligne qui permet de créer,
maintenir et gérer les ressources lexicales de systèmes de TA basés sur un "pivot
lexical", et hétérogènes dans le sens où leurs composants spécifiques à une
langue peuvent être développés à différents endroits et avec différentes
approches linguistiques et différents outils informatiques. On a prouvé une puissance
surprenante : on a pu "mettre dans PIVAX"
des dictionnaires "normaux", des dictionnaires de TA, tous les dictionnaires
UNL, WordNet, et l'ontologie OMNIA (importée
depuis Protégé[10])
grâce à sa structure à 3 niveaux.
I.3
Extensions
fonctionnelles apportées par le passage à Jibiki-2
Comme mentionné plus haut, au début de ma thèse, M. Mangeot
avait prévu une grande mise à jour de Jibiki. J'ai
participé à cette évolution de Jibiki-1 à Jibiki-2 sous sa direction.
I.3.1
Liens
riches (2 p.)
I.3.1.1 Motivations (1 p.)
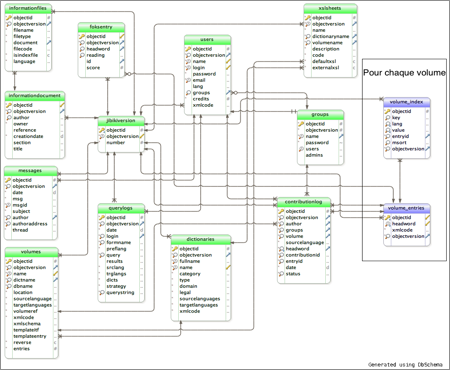
Dans la BD de Jibiki, il y a deux types de table : statique et dynamique. Les tables statiques sont créées pendant l'installation du système. Elles sont toujours les mêmes pour toutes les instances de Jibiki. Il s'agit de 12 tables (voir la Figure 24, les tables en vert). Ces tables permettent de gérer le système (sauf les données lexicales) : gestion des utilisateurs, des groupes, des contributions, des feuilles de style.
Les tables dynamiques servent à stocker les données lexicales. Ces tables sont créées pendant la création ou l'import d'un nouveau volume. En Jibiki-1, il y a deux tables pour chaque volume : une table des entrées et une table d'indexation (voir la Figure 24, les tables en bleu). Les noms de ces deux tables sont créés à partir du nom du volume. Par exemple, pour le volume CommonUNLDict_fra, nous avons la table commonunldictfra (table des entrées) et la table idxcommonunldictfra (table d'indexation).
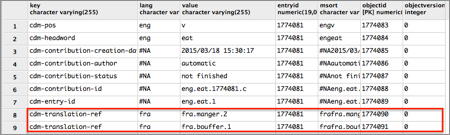
La table des entrées contient quatre colonnes : identification, mot-vedette, code Xml et version.
La table d'indexation (voir la Figure 25) contient toutes les informations indexées en utilisant le fichier de métadonnées (par des pointeurs CDM-classique ou des pointeurs particuliers). La colonne entryid associe un identificateur à une entrée dans la table des entrées. Dans cette version, il y a un seul pointeur qui sert au lien de traduction, appelé cdm-translation-ref.
On ne peut que créer un lien entre la source et l'identificateur d'une traduction, et on ne peut pas ajouter d'informations supplémentaires, notamment spécifier le volume cible du lien ! La possibilité de traiter des liens plus complexes manque vraiment.
|
Figure 24 : Schéma de la base de données de Jibiki-1 |
|
Figure 25 : Exemple de données dans la table d'indexation |
I.3.1.2 Implémentation (1 p.)
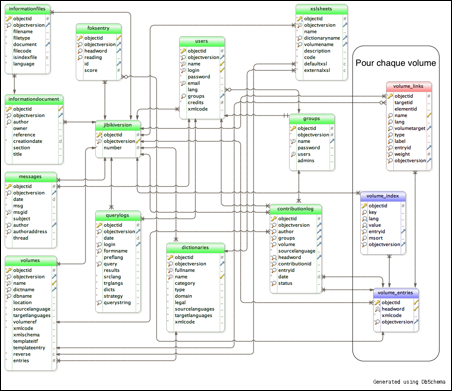
Pour traiter des liens plus compliqués, nous avons enrichi les CDM par une description plus riche des liens (voir la Figure 26), que nous avons appelés CDM-Links. Pour chaque lien, plusieurs informations peuvent être indexées :
· l'identifiant de l'entrée source.
· l'identifiant de l'entrée cible.
· l'identifiant de l'élément Xml de l'entrée source contenant le lien. Par exemple, le numéro de sens dans le cas d'une entrée polysémique avec un lien de traduction pour chaque sens. Cela permet de retrouver précisément l'origine du lien.
· le nom du lien. Celui-ci est utilisé pour distinguer des liens de types différents dans une même entrée, par exemple un lien de traduction et un lien de synonymie.
· la langue cible (code à trois lettres ISO-639-2/T).
· le volume cible.
· le type de lien. Certains sont prédéfinis car ils sont utilisés par les algorithmes de calcul des liens riches (traduction, axème, axie), mais il est possible d'en utiliser d'autres.
· une étiquette dont le texte est libre.
· un poids dont la valeur doit être un réel (entre -9,99 et 9,99).
|
Figure 26 : Exemple d'un CDM-Links |

Ces liens peuvent être établis entre deux entrées d'un même volume ou entre deux volumes différents. Un même volume peut regrouper des entrées reliées à plusieurs volumes. Pour réaliser l'implémentation des liens riches, nous avons séparé la table des liens de la table de CDM-classique. Voir la Figure 27 (nouvelle table en rouge pour stocker les liens riches).
|
Figure 27 : Schéma de la base de données de Jibiki-2 |
I.3.2
Listes
non bornées (1 p.)
Dans Jibiki-1, on n'a que deux types de recherche : recherche générique et recherche avancée. On en a ajouté un troisième dans cette nouvelle version, la recherche par volume. Cette fonction simule l'utilisation d'un dictionnaire papier. Si un mot est entré, les mots-vedette voisins dans l'ordre alphabétique sont affichés dans la partie gauche de la fenêtre. Cela permet de proposer les mots les plus proches pour une entrée incorrecte ou incomplète.
Cette partie est équipée d'un "ascenseur infini". Il est possible de naviguer dans tout le volume selon l'ordre alphabétique. Il est possible également de visualiser le contenu d'un article dont le mot-vedette est affiché dans la partie gauche en cliquant dessus. L'article s'affichera alors dans la partie droite.
Cette nouvelle fonction a été réalisée par M. Mangeot dans Jibiki-2. Comme Pivax-2 (voir II.4)
a été développé sur la base de Jibiki-2, il en a hérité
naturellement.
Le temps de réponse et la qualité de cette fonction sont satisfaisants. Voici quelques expériences.
· Sur
le serveur MotÀMot/jibiki-2, la recherche d'une entrée
et l'affichage d'un mot du volume français (13K entrées) prennent moins d'une
seconde.
· Sur
le serveur Papillon/jibiki-2, la recherche d'une entrée
et l'affichage d'un mot du volume FeM_fra (19K entrées)
prennent moins d'une seconde.
· Sur
le serveur Pivax-2/jibiki-2, la recherche d'une entrée
et l'affichage d'un mot du volume UNL_UWpedia-FRA-lexie (772K
entrées) prennent environ 4 secondes.
· Visualiser un article au début, au milieu ou à la fin de la liste est instantané.
· Pour aller d'un article à un autre à 10000 articles de distance, la manipulation de l'ascenseur est aussi fluide que celle du Finder du Mac dans un dossier à 50000 fichiers.
|
Figure 28 : Interface de liste non bornée |
I.3.3
Possibilité
générique de recherche avec lemmatisation (0,5 p.)
La recherche avec lemmatisation est implémentée dans l'interface de "recherche avancée" par l'ajout d'une condition "le lemmatiseur est XXX" pour un mot-vedette donné.
Cette fonction a été réalisée deux ans plus tard, au moment du travail sur Lextoh (l'intergiciel de lemmatisation, voir IV.2). Jibiki-2 envoie une requête à l'API de Lextoh pour récupérer les résultats de lemmatisation[11], puis recherche les lemmes dans sa BDLex. On peut utiliser tous les lemmatiseurs implémentés dans Lextoh. Les noms des lemmatiseurs sont proposés librement dans un formulaire. L'interface d'affichage est en deux colonnes, comme celui de la liste non bornée. La colonne de gauche affiche tous les résultats trouvés qui correspondent aux conditions. La colonne de droite affiche le contenu détaillé si on clique dessus.
|
Figure 29 : Interface de recherche avec
lemmatisation |
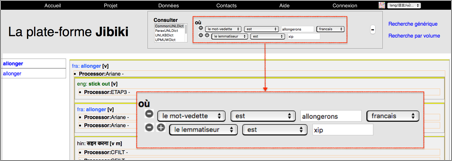
I.4
Pivax-2 : opérationnalisation et extension de Pivax-1 (4 p.)
On a réimplémenté Pivax-1 sur Jibiki-2. Pivax-2 hérite donc de toutes les fonctions et caractéristiques de Jibiki-2. Dans cette section, on montrera les améliorations obtenues dans Pivax-2 : (1) algorithme générique de calcul des liens, (2) passage à l'échelle et accélération, (3) support au projet GBDLex-UW++ et mise à disposition de ressources.
I.4.1
Algorithme
générique de calcul des liens[12]
L'algorithme de calcul des liens programmé par H.-T. Nguyen pour Pivax-1 est opérationnel (voir II.2.2.3), mais, à cause de l'impossibilité de spécifier un volume cible lorsqu'on décrit un lien, son algorithme est spécifique à la macrostructure Pivax-1 et ne peut pas être utilisé pour un autre type de macrostructure[13]. De plus, il a dû effectuer des développements spécifiques en modifiant le code java de la plate-forme Jibiki. Son code n'était donc pas réutilisable.
Avec Jibiki-2/Pivax-2, nous avons souhaité traiter de manière générique les liens entre tous les types de volume, de façon à éviter de modifier le code java de la plate-forme pour traiter une macrostructure particulière. C'est pourquoi nous avons ajouté des liens supplémentaires.
· Dans les volumes de lexies, nous avons des liens vers les axèmes, de type axeme.
· Dans les volumes d'axèmes, nous avons des liens vers les axies, de type axie et vers les lexies, de type final.
· Dans le volume d'axies, nous avons des liens vers les axèmes, de type axeme.
Cette extension concerne non seulement de la macrostructure Pivax, mais aussi d'autres macrostructures comme Pivot et Direct.
Notre algorithme est en trois parties.
1. Recherche dans la base des entrées satisfaisant une liste de critères.
2. Recherche récursive des entrées reliées aux entrées précédemment sélectionnées.
3. Affichage des entrées avec les entrées reliées.
Pour la recherche récursive et l'affichage des entrées reliées, il faut savoir où s'arrêter car on peut facilement imaginer une ressource remplie de liens entre entrées et si la recherche est récursive, elle ne s'arrête jamais. On le fait par la condition de détermination.
if (cond1||cond2||cond3){continuer
la recherche récursive} else {s'arrêter}
Voici par exemple, ce que nous avons fait pour deux types de recherche, de manière générique.
1. Cas de liens allant d'un point à un autre dans le graphe des liens.
Par exemple :
entrée A (Volume A) → entrée B (volumeB) → entrée C
(volume C)
Le lien A→B est marqué comme indirect ou null. Le dernier lien B→C est marqué comme étant un lien final, donc la recherche s'arrête[14].
2. Cas de liens de type axie qui déterminent un arbre dans une partie du graphe, l'axie étant la racine de l'arbre.
Par exemple :
entrée A (Volume A) → entrée B
(volume B) → entrée Axie (volume Axie) → entrée B' (volume B') → entrée A' (volume A')
Le lien B→Axie est marqué comme étant un lien axie, donc ensuite on redescend dans l'arbre des liens. Le lien B'→A' est marqué comme étant final, donc la recherche s'arrête.
Ces types de
recherche s'effectuent de manière générique. Il n'y a donc pas de code
spécifique à chaque macrostructure. Quand une nouvelle macrostructure se
présente, l'idée est de voir si l'on ne peut pas utiliser les algorithmes
génériques et sinon, de voir quels sont les développements minimaux à faire pour
permettre une recherche dans cette macrostrucutre. Par exemple, on peut ajouter
un nouveau type de volume dans la condition de détermination.
I.4.2 Passage à l'échelle et accélération (2 p.)
I.4.2.1 Données lexicales supportées par Pivax-2 (1 p.)
Dans Pivax-2, on a réimplémenté toutes les ressources disponibles de Pivax-1 grâce à l'aide de H.-T. Nguyen (voir II.2.3.2). On a aussi mis dans la base de nouvelles ressources : celles du projet iToldU (voir I.1.3.2.4) et deux très grosses ressources (voir II.2.3.2) : une produite par V. Dikonov (CommonUNLDict) et l'autre par D. Rouquet (UWpedia).
|
Table 4 : Nombre des entrées CommonUNLDict
|
Table 5 : Nombre des entrées UWpedia
|
I.4.2.2 Évaluations comparatives des temps de réponse (1,25 p.)
a. Environnement
Comme Pivax-1 n'était plus facilement accessible au début de ce travail, nous l'avons réinstallé sur la même machine que Pivax-2 et importé plusieurs ressources nécessaires.
Nous avons testé les deux sur les mêmes volumes de données (donc les mêmes tailles de BD). Les deux machines (client et serveur) sont implémentées dans un même intranet du LIG. Pour les environnements des tests, voir la table ci-dessous.
Table 6 : Environnement des tests de Pivax-1 et Pivax-2
|
Adr. serveur |
Adr. Client |
Date/Heure |
Config. serveur |
Config. client |
Description Script |
|
Pivax-2 129.88.46.100:8998 Pivax-1 129.88.46.100:8995 |
129.88.67.160 |
9/04/2015 10h-17h et 10/04/2015 10h-17h |
Debian 6.0.10 Processeur 3.3 GHz Intel Core i3 Mémoire 8 GB |
Mac OS X 10.9.5 Processeur 2.2 GHz Intel Core i7 Mémoire 4 GB 1333MHz DDR3 |
Script en Java. Le temps d'exécution comprend : lire le fichier des entrées,
envoyer les requêtes, récupérer les résultats, écrire le fichier log. |
b. Tests
Il y a trois fichiers pour les entrées (4 entrées, 400 entrées et 4000 entrées) qui sont créés de façon aléatoire par un script Java à partir des volumes importés. On a fait 10 expériences pour chaque fichier et pour chaque version de Pivax. Les entrées concernent 4 langues : chinois, espagnol, russe et UNL.
Les résultats sont montrés dans la Table 7. Nous avons choisi deux critères : le temps utilisé (instant de la dernière réponse reçue – instant d'envoi de la première requête) et le nombre de réponses correctes. Le temps de réponse de Pivax-2 est environ la moitié de celui de Pivax-1. D'autre part, point important, Pivax-1 renvoie beaucoup d'erreurs système (chargement impossible).
Table 7 : Résultat des évaluations comparatives des temps de réponse
|
Fichier de test |
Système |
Temps moyen en millisecondes |
Temps en min/sec |
Nombre d'erreurs |
Nombre de résultats corrects |
|
entries4Test.txt |
Pivax-1 |
980 |
0 min, 0 sec |
0 |
4 |
|
entries4Test.txt |
Pivax-2 |
508 |
0 min, 0 sec |
0 |
4 |
|
entries400Test.txt |
Pivax-1 |
61 832 |
1 min, 1 sec |
214 |
186 |
|
entries400Test.txt |
Pivax-2 |
32 724 |
0 min, 32 sec |
2 |
398 |
|
entries4000Test.txt |
Pivax-1 |
899 889 |
14 min, 59 sec |
2 577 |
1 423 |
|
entries4000Test.txt |
Pivax-2 |
479 763 |
7 min, 59 sec |
7 |
3 993 |
c. Petite analyse
On peut analyser ces résultats de deux points de vue principaux.
(1) M. Mangeot avait développé une API REST pour Jibiki-1 avant mon arrivée au labo. Cette API a été conservée et mise à jour dans Jibiki-2. Mais Pivax-1 n'utilisait pas cette API. C'est pourquoi, pour les tests sur Pivax-1, nous devions charger une page entière, y compris les images (dont les logos), puis récupérer le résultat dans un module de Html. L'API de Pivax-2 nous permet de récupérer directement les résultats en Xml sans charger des informations inutiles.
(2) Comme on l'a expliqué au II.3.1,
les informations portées par les liens de Pivax-1 sont
stockées dans la table d'indexation avec toutes les autres informations de CDM. Mais, dans Pivax-2, les
informations portées par les liens sont stockées séparément dans la table de "links".
Son nombre d'enregistrements est bien inférieur à celui de la table d'indexation
de Pivax-1. Par exemple, pour le volume CommonUNLDict_eng, le nombre d'enregistrements de la table d'indexation
est 272 826, et le nombre d'enregistrements de la table de links est 82 096.
Donc, pour une macrostructure complexe comme celle de Pivax,
la recherche par liens dans la BD est effectivement améliorée.
I.4.3
Support
au projet GBDLex-UW++ et mise à disposition de ressources
I.4.3.1 Support au projet GBDLex-UW++
On a déjà mentionné ce projet et ses ressources lexicales plus haut (voir I.1.3.2.2, II.2.3.2 et II.4.2). On a beaucoup travaillé sur le projet GBDLex-UW++ dans le cadre du projet Traouiero, et on a importé toutes ses ressources disponibles dans Pivax-2.
Grâce aux retours de V. Dikonov (linguiste et
lexicographe de l'IPPI), qui a le plus
travaillé sur ses données sous Pivax-2, nous avons détecté de nombreux problèmes. Par
exemple, on a cherché le mot-vedette anglais milk en UNL et en anglais, et on a trouvé tous les UW et
les traductions des LN, y compris les mots russes. Puis on a cherché les mots-vedette
traire et lait en français, ça
marchait aussi. Cependant, quand on a cherché les mots-vedette russes (доить = to milk et молоко = milk), on n'a trouvé aucune traduction associée.
La source de ce problème se situe au niveau des données
(et aussi au manque de progammabilité de Pivax-2). C'est parce que les liens de recherche sont orientés,
voir la Figure 30. En effet, il manque des liens des lexies russes vers les axèmes russes
(dans le volume des lexies russes) et/ou des liens des axèmes russes vers les axies
interlingues (dans le volume des axèmes russes).
V. Dikonov avait oublié la création de ces liens quand
il avait construit la ressource, et ensuite il n'a pas voulu (ou pas pu) la modifier. Il faut dire que c'est impossible à faire à la main pour une grosse taille
et que c'est toujours difficile à
programmer par un linguiste.
Cela nous montre l'importance de la programmabilité (par langage narratif ou par manipulation graphique
directe) de notre système.
|
Figure 30 : Problèmes de la ressource de V. Dikonov |
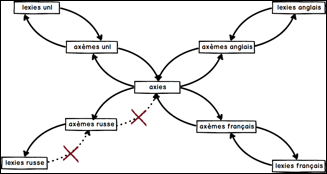
C'est
ce que H.-T. Nguyen a spécifié dans le dernier chapitre de sa thèse (voir II.2.2.5).
Il serait vraiment intéressant d'implémenter une telle fonctionnalité programmable, mais
cela nous aurait pris plusieurs mois (à temps partiel, en parallèle avec le
travail chez L&M).
I.4.3.2 Mise à disposition de l'outil et de données sur le Web (1 p.)
Le serveur Pivax-2 est implémenté sur un serveur intranet du GETALP (takara.imag.fr) ; on peut trouver sa configuration dans la Table 6. Le lien pour y accéder par l'intranet est http://takara.imag.fr:8998/pivax/Home.po. On peut aussi y accéder depuis Internet par http://getalp.imag.fr/pivax/Home.po grâce à une redirection.
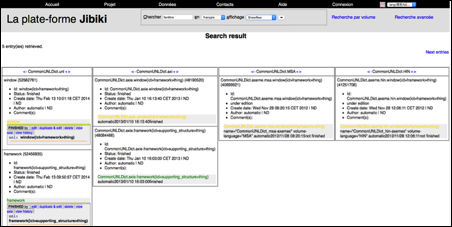
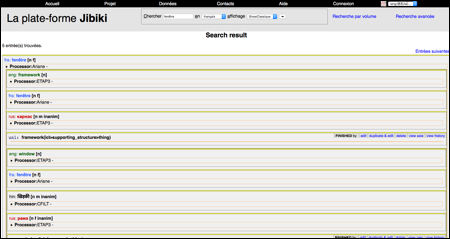
D'une part on a hérité de toutes les fonctions de Jibiki-2, et d'autre part on a récupéré toutes les fonctions de Pivax-1. Pour l'interface de recherche générique, on a implémenté deux types d'affichage : l'affichage en colonnes de Pivax-1 (column display)[15] et l'affichage par défaut réalisé par Jibiki-2 (row display).
|
Figure 31 : Interface d'affichage en colonnes des Pivax-2 |
|
Figure 32 : Interface d'affichage classique (en lignes) de Pivax-2 |