Chapitre III Une nouvelle architecture intégrant les données lexicales générales, terminologiques et "situées" : Pivax-3 (33,5 p.)
(0,5 p.)
Ce chapitre présente une contribution originale à la lexicographie computationnelle, qui a donné lieu à une publication [Zhang, Y. & Mangeot, M., 2013] à LTT en 2013. Le point de départ a été un besoin précis de L&M, à savoir la gestion d'un certain type d'abréviations, les acronymes, pour certains clients.
Les acronymes en question sont des unités lexicales souvent terminologiques, mais pas toujours. Un même "prolexème" (collection d'unités lexicales synonymes dans une certaine situation, spatio-temporelle et/ou technique et/ou entrepreneuriale) n'a pas nécessairement de réalisation de type acronyme (ou abréviation, ou apocope, ou mot-valise) dans différentes langues. Du point de vue informatique, il faut pouvoir traiter ces unités dans la même base de données que les termes techniques et que les termes généraux.
Nous avons proposé un modèle pour réaliser cette intégration de ces 3 types d'unités lexicales dans une même BDLex. Pour des raisons informatiques, L&M ne pouvait pas intégrer cette solution à sa BDLex ; la solution réalisée pour L&M n'a donc été que partielle. Par contre, au laboratoire, nous avons pu l'implémenter complétement en Pivax-3/Jibiki-2, et produire un démonstrateur.
Dans la première section, nous analysons le problème posé par L&M et sa demande précise. Dans la deuxième section, nous étudions les éléments de la solution. Ensuite, dans la troisième section, nous présentons les solutions (la solution pour L&M et la solution générale), et les démonstrations. Enfin, nous discutons les autres extensions envisageables.
I.1 Analyse d'un problème posé par L&M (4 p.)
I.1.1 Présentation du problème rencontré par L&M (1,5 p.)
I.1.1.1 Contexte (0,5 p.)
On a déjà mentionné les besoins réels de L&M au I.2.2.2.2. Vers février 2012, L&M a été confrontée au problème suivant : deux clients (EDF et Wesco) avaient à traduire des textes comportant beaucoup d'acronymes. Ces acronymes figuraient dans leurs fichiers terminologiques, qui avaient été importés dans Libellex, mais les traducteurs n'obtenaient pas le développement de ces acronymes, quand la traduction "acronymique" était absente. Ensuite, en 2013, deux autres clients (ExaleadSuggest et Louis Vuitton) ont demandé de traiter leurs terminologies monolingues avec des relations plus complexes.
L'outil de gestion de terminologie de Libellex permet l'import, l'export, la suppression, la consultation et la validation. Il y a deux interfaces pour la terminologie monolingue et pour la terminologie bilingue, qui diffèrent l'une de l'autre surtout pour la consultation et la validation. Pour l'import et l'export, on peut utiliser les formats d'échange de Metricc (TBXMetricc et TEIMetricc, voir I.2.2.1 et I.2.2.2). Mais ces formats sont dédiés au traitement automatique et sont difficiles à comprendre et à utiliser par les clients (par les humains en général).
Libellex propose un nouveau format d'échange, TSV (Tabulation-Separated Values)[1], et nous avons principalement utilisé ce format TSV pour les tâches liées à Libellex (voir les exemples dans la section suivante).
Juste au début de ma thèse, vers mi-avril 2012, Libellex a réalisé une interface graphique pour la terminologie monolingue et pour afficher les réseaux sémantiques. Cette fonction a été initialement réalisée par Mikaël Morardo. Au début, les liens sont créés entre deux termes seulement s'ils partagent des contextes similaires. Une matrice nœuds/contextes est construite dynamiquement en utilisant l'analyseur syntaxique FRMG [Villemonte de la Clergerie, É. et al., 2009]. M. Morardo a présenté sa méthode et son algorithme dans [Morardo, M. & Villemonte de La Clergerie, É., 2013].
|
Figure
33 : Interface de consultation graphique pour la
terminologie monolingue dans Libellex |
I.1.1.2 Extraits de la "ressource" des clients (0,75 p.)
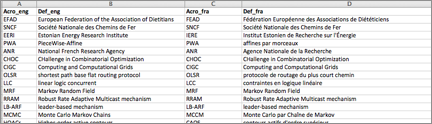
Début 2012, les ressources importées en format TSV contenaient quatre types de fichier : (1) monolingue sans phrases d'exemples en une seule colonne : langue en ISO 639-1 (ex. fr), (2) monolingue avec phrases d'exemple en deux colonnes (ex. fr[Tab]fr_sent), (3) bilingue sans phrases d'exemples en deux colonnes (ex. fr[Tab]en) et (4) bilingue avec phrases d'exemples en quatre colonnes (ex. fr[Tab]en[Tab]fr_sent[Tab]en_sent).
|
Figure 34 : Ressource bilingue importée (avec phrases) dans la BDLex de Libellex |

Voici quelques exemples de ressources transmises par les clients après mon arrivée.
|
Figure 35 : Exemple de ressource prétraitée dédiée à des acronymes[2] |
|
|
Figure 36 : Exemple d'une ressource de Louis Vuitton prétraitée |
|
|
Figure 37 : Exemple d'une ressource d'ExaleadSuggest prétraitée |
|

I.1.1.3 Demande précise de L&M
L&M m'a demandé d'étudier ce problème, de trouver une solution implémentable à l'intérieur de Libellex, et de l'implémenter. J'ai d'abord étudié et évalué la structure de la BDLex existante pour voir si elle permettait de traiter ce type de problème ou bien si on avait besoin d'installer une autre BDLex séparée (dans cette perspective, nous avons proposé un nouveau type de BDLex basé sur Jibiki).
Ensuite, j'ai travaillé sur l'import et l'export de
terminologies complexes en TSV, contenant des acronymes
et diverses relations. Enfin, avec M. Morardo, j'ai réalisé l'affichage et l'intégration
dans les interfaces existantes, principalement dans l'interface graphique.
I.1.2
Analyse des problèmes posés (1 p.)
I.1.2.1 Défauts de la ressource lexicale du client (0,25 p.)
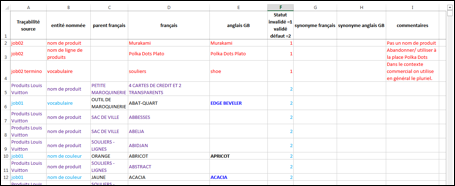
L&M a souvent reçu des ressources très riches mais très
incomplètes. Par exemple, les ressources lexicales de Louis Vuitton contiennent principalement des entités nommées associées à
des lignes de produits et à des produits. Ces ressources initiales étaient
hiérarchisées en xlsx, et il fallait les mettre en format "à plat" (en TSV) tout en gardant les liens
de parenté, les correspondances bilingues, les synonymes etc.
On aurait dû avoir une
traduction en anglais pour chaque terme français, mais souvent il n'y en avait pas. Par exemple, un échantillon sur lequel
j'ai travaillé contenait 10 857 termes français,
mais seulement 2604 traductions anglaises.
On voit aussi des erreurs dans la Figure 35 : (1) l'acronyme SNCF et sa définition française ont été recopiés dans les colonnes anglaises, et (2) on indique un –s pour le pluriel d'un acronyme, toujours invariable en français (les CNAM, pas "les CNAMs").
De plus, les traductions françaises sont souvent fausses ou très mauvaises.
I.1.2.2 Problèmes conceptuels (0,25 p.)
Il y a des confusions entre les acronymes et les autres types d'abréviation. Plus généralement, on voit qu'il aurait fallu qu'au moins un(e) spécialiste de terminologie participe à la construction de ces ressources. D'où la nécessité d'étudier nous-même les aspects linguistiques, et plus précisément lexicologiques, liés aux différents "objets linguistiques" à traiter.
I.1.2.3 Problèmes venant de la structure de la BDLex de Libellex (0,5 p.)
On a mentionné cette structure au I.2.2.1 et au I.2.2.2. L'absence de la notion d'acception interlingue (représentée en LexAlp ou en PIVAX par une "axie") associée à un concept dans le schéma conceptuel de la base lexicale de Libellex est un problème profond. Elle rend très difficile la création des relations sémantiques.
I.1.3 Étude lexicologique et lexicographique
I.1.3.1 Nécessité d'un niveau conceptuel (lexies et axies)
Les liens entre les termes sont compliqués. Plusieurs termes différents peuvent être liés à un seul référent : Jean-Paul II et Karol Jozef Wojtyla en français, ou en anglais John Paul II et Karol Jozef Wojtyla.
Des pays parlant la même langue (ex : France et Suisse romande) peuvent également utiliser des mots différents pour le même concept. Par exemple, chien renifleur et chien drogue. Inversement, le même terme peut désigner des concepts différents : dans la province de langue allemande de Bolzano en Italie, le Landeshauptmann est le président du conseil provincial, avec des compétences beaucoup plus limitées que le Landeshauptmann autrichien, qui est à la tête de l'un des États (Länder) de la fédération autrichienne. Même chose pour principe de précaution en français (voir la Figure 13).
C'est pourquoi on a besoin de lexies (voir la Définition 10) et d'axies (voir la Définition 11).
I.1.3.2 Nécessité de la notion de "prolexème" pour les entités nommées (0,25 p.)
Les notions d'axie et de lexie ne suffisent pas à représenter toutes les situations liées aux noms propres, parce qu'on a des dérivés, des alias, des types différents d'abréviation d'un même nom propre, etc. Par exemple, pour la ville de Saint-Martin-d'Hères, on peut trouver : Saint Martin d'Hères, St Martin d'Hères, Saint-Martin-d'Hères, SMDH, ou SMH.
L'association d'un prolexème (voir la Définition 17) aux noms propres de même référent a été proposée pour traiter ce type de problème dans la thèse de M. Tran [Tran, M., 2006]. Un prolexème permet de relier les différentes formes d'un nom propre qui apparaissent dans les différents textes d'une langue donnée.
Il s'agit non seulement de noms propres, mais aussi d'expressions métaphoriques, ou de groupes nominaux, par exemple, Paris et ville lumière, Obama et président des USA.
I.1.3.3 Différence entre le niveau terminologique et le niveau des prolexèmes (0,25 p.)
Une terminologie contient des termes situés de façon relativement permanente. Un terme (nominal ou même verbal), ou un phrasème (ex: un gène "code pour" une protéine), a un sens spécifique par rapport aux énoncés relatifs à chaque domaine ou ontologie où il apparaît.
Par contraste, une entité nommée est un "désignateur", et son référent peut changer (et change fréquemment) en fonction du temps, du lieu, du contexte socio-économique et historique, etc. Un exemple très connu est Président des USA : George Bush. Oui, mais quand ? Il y a eu le père et le fils, à des périodes différentes.
I.1.3.4 Nécessité de distinguer les lexèmes spécifiques d'un "sous-langage" (0,25 p.)
On peut considérer une forme comme L8R comme un mot spécialisé pour le sens later, rencontré seulement dans le contexte des textos. Il s'agit ici non pas d'une entité nommée, mais d'un vocable du sous-langage des textos en anglais.
De même, dans le sous-langage des mels ou dans celui des textos, on trouve A+ pour À plus ou À plus tard. Dans le contexte de textos, la meilleure traduction en anglais de A+ sera donc L8R et pas later.
I.1.3.5
Possibilité de se référer à la théorie de la
cognition située
Les idées présentées plus haut (au I.3.1.1.1)
sont basées sur la théorie de la cognition située. Cette théorie provient
initialement des travaux de Coseriu [Coseriu, E., 1998 ; Coseriu, E., 2001]. Citons
ici la définition trouvée dans Wikipedia :
Situated
cognition is a theory that posits that knowing is inseparable from doing [Brown,
J. S. et al., 1989] by arguing that all knowledge
is situated in activity bound to social, cultural and physical contexts [Greeno,
J. G. & Moore, J. L., 1993].
I.2
Éléments d'une solution (6,5 p.)
I.2.1
Systèmes dont on pouvait
s'inspirer (1 p.)
I.2.1.1
CJK.org
CJK.org a été brièvement mentionné au I.2.3.3. L'institut CJK, sous la direction de J. Halpern, s'est concentré sur le problème de l'extraction intelligente d'informations pour traiter les variantes d'écriture de plusieurs langues, à partir de 1996 [Halpern, J., 2002]. Par exemple, en chinois et en japonais, il y a plusieurs formes d'écriture, et beaucoup de variantes pour certains caractères ou mots.
Pour l'écriture du chinois, on distingue le "chinois simplifié" et le "chinois traditionnel". Entre 1956 et 1986[3], les nouvelles autorités de la Chine (RPC) ont mis en œuvre une réforme de l'écriture préparée depuis bien avant la révolution. Elle a consisté à remplacer 2 274 caractères par des formes simplifiées, provenant de formes calligraphiques. Ni Taiwan ni le Japon ni la Corée n'ont adopté ces formes. Depuis une dizaine d'années, les formes traditionnelles sont de nouveau utilisées et enseignées. La raison principale semble être qu'il est plus difficile de se souvenir du sens des formes simplifiées que des formes traditionnelles, qui sont plus structurées et se prêtent mieux à des méthodes mnémoniques.
Les gens non informés pensent qu'il s'agit juste de la conversion d'un codage des caractères vers un autre codage des caractères. En fait, c'est beaucoup plus compliqué.
Il y a quatre difficultés principales. Les deux premières concernent les conversions des caractères et des mots, la troisième la conversion du sens, et la quatrième les variantes.
(1) Il y a beaucoup de sinogrammes simplifiés qui correspondent à plusieurs sinogrammes traditionnels (et vice versa, mais moins fréquemment). Voici trois exemples.
|
Chinois Simplifié (CS) |
Chinois Traditionnel (CT) |
Remarque |
|
头 (tóu) |
頭 (tóu)[4] |
Correspondance injective (1-1) |
|
发 (fā ou fǎ, polyphone)
|
髪(fǎ) et發 (fā) |
Correspondance 1-n |
|
头发 (tóu fǎ) |
頭髮 (cheveux, tóu fǎ) |
頭發 est faux. |
(2) Un mot écrit en chinois simplifié peut correspondre à plusieurs mots écrits en chinois traditionnel. Pour le choix, il faut voir le contexte.
|
CS |
CT |
Remarque |
|
阴 (yīn) |
陰(yīn) et隂 (yīn) |
Correspondance 1-n |
|
干 (gān ou gàn) |
乾
(gān
ou qián) et 干(gān ou gàn) |
Correspondance 1-n |
|
阴干(yīn gān) |
陰乾 (sécher
à l'ombre, yīn gān) 陰干 (terme de médecine chinoise, yīn gān) |
Voir le contexte |
(3) Pour certains sens, CS et CT utilisent des mots complètement différents. Voici un exemple.
|
CS |
CT Taiwan |
CT Hong Kong |
Remarque |
|
出租车 (chū
zū chē) |
計程車 (jì
chéng chē) |
的士 (dī shì) |
La conversion de "caractère à caractère" : (CS) 出租车 → (CT) 出租車, produite par Google Translate, est fausse. |
|
CS |
CST |
CT |
|
线 |
綫 |
線 |
|
绷 |
綳 |
繃 |
(4) Il
y a beaucoup de variantes en CT. Par exemple, 群et羣,
秋et秌,
匯et滙,
啟et啓,
etc. D'autre part, la Chine continentale utilise
un troisième système, le "chinois simplifié traditionnel" (CST) pour
publier des journaux, des livres etc. pour les gens qui utilisent CT, par exemple "人民日報海外版" (Rén
mín rì bào hǎi wài bǎn,
People's
daily overseas edition). Les caractères de CST sont définis dans la
norme GB/T 12345-90. Ce ne sont pas tout à fait les mêmes que ceux de CT. Voir
la table ci-contre.
Le
japonais est encore plus compliqué que le chinois. Il y a quatre jeux de
caractères : kanji, hiragana, katakana et romaji. Ils sont le plus souvent
mélangés. Par exemple, la phrase "金の卵を産む鶏" (Kin no tamago wo umu niwatori,
poulet qui pond des œufs d'or)
peut avoir 24 variantes d'écriture.
En plus, il existe beaucoup de variantes, par exemple, (variante de Kanji) 發 et 発, ou (homophones) 柔かぃ (Yawaraka ~i) et 軟かぃ
(Yawaraka ~i). Pour plus de détails, voir [Halpern, J., 2002 ;
Halpern, J., 2006].
CJK.org utilise des tables de correspondance pour convertir entre les
différents niveaux.
Conversion entre chinois simplifié et chinois traditionnel
· Tables "Code-level mapping" pour la conversion caractère à caractère.
· Tables "orthographic et lexemic mapping" pour la conversion mot à mot.
· Tables "orthographic mapping tables for proper nouns" pour les noms propres.
· Tables "orthographic/lexemic mapping tables for technical terminology" (surtout pour l'informatique).
Normalisation
orthographique du chinois traditionnel vers le chinois simplifié
· Tables de normalisation de CT en CS.
· Tables de normalisation de CST en CS.
Base de données des
variantes orthographiques en japonais
· Base de données complète des variantes orthographiques en japonais.
· Base de données des groupes homophones sémantiquement classés.
· Groupes de synonymes sémantiquement classés, pour l'expansion de ces synonymes (thésaurus japonais).
· Lexique anglais-japonais pour le CLIR (cross-language information retrieval, ou RI translingue).
· Règles d'identification des variantes non listées.
I.2.1.2 IATE (0,5 p.)
IATE (Inter-Active Terminology for Europe) [Ball, S., 2003] est la base de données terminologique que partagent les institutions de l'Union européenne. Elle concerne les 25 langues officielles de l'UE. L'interface actuelle permet de choisir parmi 21 grands domaines, eux-mêmes divisés en plus de 100 petits domaines. Il y a aujourd'hui environ 8,6 millions de termes dans la base d'IATE, répartis dans approximativement 1,4 million de fiches.
La base de données est organisée à trois niveaux : concept, langue et terme. Pour ajouter une nouvelle entrée, il faut l'associer à chaque niveau en utilisant une interface avancée de manipulation des données. Cette fonction est réservée aux terminologues et aux administrateurs. Le système permet également aux terminologues d'évaluer les termes par degré de fiabilité.
Il y a parfois des doublons pour un seul et même concept. C'est parce que plusieurs ressources terminologiques (Eurodicautom, TIS, Euterpe, Euroterms, CDCTERM) ont été fusionnées dans la base de données IATE en 2004. Chaque institution avait auparavant sa propre base de données terminologiques.
Le système fournit aux terminologues des outils de "dédoublonnage", qui permettent la sélection, la suppression ou la concaténation des données à chacun de ces trois niveaux. Ce travail est toujours en cours.
I.2.1.3 EDR (1 §.)
EDR Electronic Dictionary[5] est un dictionnaire japonais-anglais, développé entre 1987 et 1993 par le projet EDR, organisé par le MITI (Ministry of International Trade and Industry) du Japon, auquel ont participé 8 grosses entreprises[6]. La base lexicale d'EDR est composée de dictionnaires de quatre types[7] et de deux corpus [Takebayashi, Y., 1993].
|
Figure 38 : Structure de EDR Electronic Dictionary |
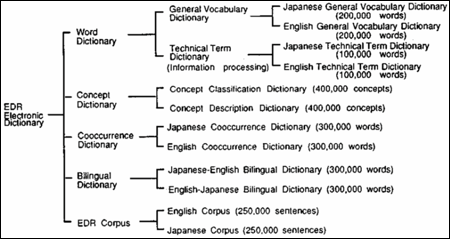
Les dictionnaires monolingues (Word Dictionaries) contiennent des informations grammaticales, des informations supplémentaires (l'usage, la fréquence, etc.) et des liens vers des concepts (dans le dictionnaire des concepts).
Les entrées du dictionnaire des concepts contiennent leurs définitions, des explications, ainsi que les relations entre deux concepts (dans le dictionnaire "Concept Classification"), par exemple kind-of(concept1, concept2).
Les dictionnaires bilingues sont similaires aux dictionnaires papier. Ils définissent des correspondances de traduction.
Les dictionnaires de cooccurrences donnent des informations sur les usages, surtout les relations syntaxiques entre termes, par exemple, eaten @d-object lunch.
I.2.2 Prolexbase et les prolexèmes (5 p.)
I.2.2.1
Le projet Prolex (1 p.)
a.
Contexte
Le projet Prolex[8] a été lancé par le Laboratoire d'Informatique
(LI) de l'université François-Rabelais de Tours en 1994. Son objectif était le
traitement automatique des noms propres et la création d'un
dictionnaire relationnel de noms propres.
Prolex a produit Prolexbase, un système développé par Mickaël Tran dans le cadre de sa thèse [Tran, M., 2006]. Prolexbase est un dictionnaire électronique relationnel multilingue pour les noms propres.
On retranscrit ci-dessous
les points importants et les notions de base introduites dans [Tran, M.,
2006].
b.
Définition
d'un nom propre
M. Tran a listé plusieurs définitions différentes pour les noms propres, et il a finalement adopté la définition de [Jonasson, K., 1994].
Définition 21. Nom propre [Jonasson, K., 1994] : Toute expression associée dans la mémoire à long terme à une entité particulière en vertu d'un lien dénominatif conventionnel stable.
c.
Critères
des noms propres
Dans son analyse de
la complexité du problème de l'identification
des noms propres, il a défini 5 critères.
Critère de la majuscule à l'initiale.
Cela dépend des langues et
des cas. Pour le français, le critère de la majuscule s'applique seulement à l'écrit, mais ne concerne pas l'oral. L'emploi de la majuscule n'est
pas limité aux noms propres, mais aussi à certains noms communs quand ils sont
utilisés de façon "personnifiante" (ex : la
Mort, la Nature). Dans
le cas des mots composés, la majuscule n'apparaît pas toujours pour chaque élément (ex : la tour Eiffel,
mais Le Mans).
Critères morphologiques. En français, les noms propres sont souvent
invariables en genre et en nombre, mais il y a des exceptions et des
incertitudes (ex : les îles Spratleys et les îles
Spratley).
Critères syntaxiques. Les noms propres peuvent être ou non accompagnés
d'un déterminant (ex : Taiwan, la Thaïlande, Bornéo, les
Philippines).
Critères sémantiques. Il existe plusieurs théories quant à la
signification des noms propres. Certains linguistes (S. Mill, K. Kripke, J.
Molino, M. Noailly, K. Jonasson, etc.) les considèrent uniquement comme des
étiquettes. Pour d'autres
linguistes (E. Buyssens, F. Kiefer, M. Gross, etc.), ils ont un sens descriptif
(faible ou fort). Enfin, d'autres
linguistes les considèrent comme des prédicats de dénomination.
Critères pragmatiques. La signification d'un nom propre peut dépendre de son contexte
d'utilisation (Paris → une ville de France, une ville des États-Unis, une ville du Canada,
etc.).
d.
Typologies
des noms propres
M. Tran a présenté
plusieurs typologies des noms propres. La plus importante est celle de Grass [Grass, T.,
2000]. Cette typologie n'est pas exactement celle utilisée pour la
réalisation de Prolexbase, mais elle lui a servi de base.
Anthroponymes : patronymes, prénoms, pseudonymes, ethnonymes,
groupes musicaux modernes, gentilés[9], hypocoristiques, ensembles artistiques et
orchestres classiques, partis et organisations, clubs sportifs, noms donnés aux
animaux familiers (zoonymes).
Toponymes : pays, villes, microtoponymes, hydronymes, oronymes,
installations militaires, monuments.
Ergonymes : marques, entreprises, établissements d'enseignement et de recherche, titres de
livres, de films, de publications et d'œuvres d'art, objets
mythiques.
Praxonymes : faits historiques, maladies, événements culturels.
Phénonymes : ouragans, zones de haute et de basse pression, astres et comètes,
phénomènes climatiques (ex : el Niño).
I.2.2.2 Concepts essentiels venant de Coseriu (0,5 p.)
I.2.2.2.1 Types de relations de synonymie
La théorie linguistique d'Eugenio Coseriu [Coseriu, E., 1992] distingue trois sous-types de relation dans la relation de synonymie :
· la relation entre un signe linguistique et un objet.
· la relation entre un signe linguistique et d'autres signes linguistiques.
· la relation entre un signe linguistique et le contexte linguistique et situationnel.
I.2.2.2.2 Variations de la relation de synonymie en fonction de caractéristiques de la "situation"
[Coseriu, E., 1998] propose un "diasystème" décrivant les variations de la relation de synonymie en fonction de différentes dimensions :
· selon le temps (dimension diachronique).
· selon l'espace (dimension diatopique).
· selon les caractéristiques sociales des locuteurs (dimension diastratique). Par exemple, 神马(shén mǎ) et 什么(shén me)[10].
· selon les activités qu'ils pratiquent (dimension diaphasique).
Françoise Gadet [Gadet, F., 2003] a proposé une dimension en fonction du canal employé, oral ou écrit (dimension diamésique).
I.2.2.3 Aspects logiciels : Prolexbase (2 p.)
I.2.2.3.1 Concepts (1,5 p.)
Il y a deux notions principales à la base du projet Prolex : le nom propre conceptuel et le prolexème.
a. Le nom propre conceptuel
Citons ici une partie de la présentation de [Tran, M., 2006].
Pour une
langue donnée, des noms propres totalement différents sur le plan graphique
peuvent renvoyer à un même et unique référent, et ce phénomène se retrouve
généralement d'une
langue à l'autre.
Nous
définissons le nom propre conceptuel non pas comme le référent, mais plutôt
comme un certain point de vue sur celui-ci. Ainsi les noms propres Allemagne en
français, Alemania en espagnol, Deutschland en allemand, etc., seront associés
à un même nom propre conceptuel, tandis que les noms propres République
fédérale d'Allemagne
en français, República Federal de Alemania en espagnol, Bundesrepublik
Deutschland en allemand, etc. seront associés à un autre nom propre conceptuel.
Ces deux noms propres conceptuels seront en relation de synonymie.
Pour définir ces différents points de vue, nous nous sommes basés sur un marquage diasystématique, qui provient des travaux sur la métalexicographie de [Coseriu, E., 1998].
b.
Le
prolexème
On a déjà mentionné la notion de prolexème au I.3.1.1.1 et au III.1.3.2. On peut considérer que le prolexème est une classe d'équivalence de synonymes de noms propres. M. Tran a défini des concepts secondaires pour le prolexème :
· les alias (les variantes, les abréviations, les sigles, les transcriptions etc.), par exemple, Pékin – Bejing, Canal plus – Canal +, François Mitterrand – F. Mitterrand.
· les dérivés (les noms relationnels et les adjectifs relationnels), par exemple, Parisien et parisien.
I.2.2.3.2 Relations (0,75 p.)
Après avoir identifié les différents concepts de noms propres, M. Tran précise les relations qui peuvent les relier.
· Synonymie : partage d'un même sens. Il en existe différents types :
o diachronique (ex. Zaïre et République démocratique du Congo).
o diastratique (les variations entre jeunes/personnes âgées, ruraux/urbains, professions différentes, niveaux d'études différents).
o diaphasique (ex. Paris et Ville lumière).
· Méronymie : hiérarchisation sur plusieurs niveaux entre les éléments contenants (holonymes) et les éléments contenus (méronymes), par exemple, arbre/forêt, matinée/journée.
· Accessibilité : notion d'importance, d'entité significative. Par exemple, Bangkok est la capitale de la Thaïlande.
· Expansion classifiante : notion de caractérisation d'un terme (ex. Dirigeant politique et Président).
· Éponymie : la relation entre un nom propre et une forme lexicalisée. Elle sert à empêcher la reconnaissance abusive des noms propres. Par exemple, un bic = un stylo-bille, Parkinson ≠ nom propre dans maladie de Parkinson.
I.2.2.3.3 Ontologie des noms propres
M. Tran a pris en compte la méthodologie de construction de l'ontologie de Noy et McGuinness [Noy, N. F. & McGuinness, D. L., 2003]. Chaque nom propre conceptuel (pivot) est en relation d'hyperonymie avec un type et une existence.
Pour définir l'ontologie, M. Tran s'est inspiré de la typologie de Grass [Grass, T., 2000] (voir III.2.2.1). Les quatre premiers supertypes identifiés sont :
· les anthroponymes : trait humain ;
· les ergonymes : trait inanimé ;
· les pragmonymes : trait événement ;
· les toponymes : trait locatif.
Il y a aussi 29 sous-types que nous ne listons pas ici. Par exemple, le supertype ergonyme a des sous-types objet, œuvre, produit, vaisseau.
De plus, deux notions ont été ajoutées :
· la notion d'existence, pour préciser le domaine d'appartenance d'un nom propre (ex. historique, fiction, etc.).
· la relation d'hyperonymie (primaire et secondaire), qui décrit le phénomène d'inclusion. La relation d'hyperonymie primaire est la relation la plus usuelle. La relation d'hyperonymie secondaire est la relation complémentaire. Par exemple, le type "Entreprise" relie l'anthroponyme (par exemple Bouygues) en relation d'hyperonymie primaire avec l'organisme nommé d'après lui (par exemple, le groupe Bouygues) et relie l'ergonyme et le toponyme en relation d'hyperonymie secondaire. C'est parce que le terme "Entreprise" est d'abord vu comme un nom (ou l'entreprise elle-même), avant d'être considéré comme une fabrication humaine ou un lieu. Voici les exemples.
(1) L'entreprise Bouygues a décidé que …
(2) Il a réussi dans son entreprise avec …
(3) Il est aujourd'hui au travail à l'entreprise…
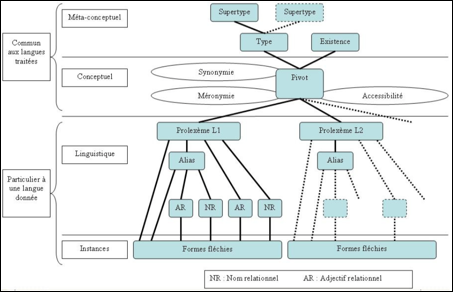
I.2.2.3.4 Représentation à quatre niveaux (0,5 p.)
Il y a quatre niveaux.
Les deux premiers niveaux sont indépendants de la langue. Ce sont :
· le niveau méta-conceptuel : la typologie et l'existence.
· le niveau conceptuel : le nom propre conceptuel (qui constitue un "pivot" entre les langues) et les relations indépendantes des langues.
Les deux derniers niveaux sont dépendants d'une langue :
· le niveau linguistique : le prolexème, les alias, les dérivés et les relations qui dépendent de la langue (dont des fonctions lexico-syntaxiques de I. Mel'čuk).
· le niveau des instances : l'ensemble des formes fléchies d'un lexème d'une langue.
La Figure 39 regroupe les différents concepts utilisés.
|
Figure 39 : Modèle à quatre niveaux de Prolexbase |
I.2.3 Esquisse d'une solution (0,5 p.)
Notre travail s'est beaucoup inspiré de Prolexbase. Par contre, nous ne nous sommes pas limitée aux noms propres, mais nous avons étendu notre modélisation à tous les termes de différents degrés de situement (voir la Définition 18), y compris les verbes et les prédicats composés.
Au niveau linguistique, Prolexbase est déjà bien complexe, et nous ne voulons pas l'enrichir de ce point de vue. Nous avons préféré simplifier et ne reprendre qu'une partie des notions de Prolexbase (surtout l'idée de prolexème) dans notre prototype : Pivax-3.
D'autre part, notre travail ne limite pas le nombre de langues. Donc la construction de dictionnaires non-symétriques comme CJK.org ne nous convient pas. Pour la symétrie, nous avons repris les notions de lexie, d'axème et d'axie de Pivax-2.
Pour l'implémentation, utiliser la plate-forme Jibiki-2 était la meilleure solution. Nous avons profité des fonctions existantes (ex. gestion des contributions, interfaces etc.) et intégré la notion de prolexème dans la macrostructure de Pivax-2 (ce qui a donné Pivax-3).
I.3 Conception et implémentation d'une solution basée sur les "liens riches" (19,5 p.)
I.3.1 1° prototypage chez L&M (4,5 p.)
On ne pouvait pas intégrer
les prolexèmes dans la BDLex de Libellex à cause de contraintes techniques. On ne pouvait pas
non plus combiner Pivax-3
avec Libellex
à cause de contraintes industrielles. Finalement, j'ai proposé et implémenté une solution ad hoc.
Dans cette
section, on analyse les contraintes techniques et les contraintes
industrielles, puis on présente la solution retenue, et une démonstration.
I.3.1.1 Contraintes
techniques (2,5
p.)
I.3.1.1.1
Format
d'échange de ressources
lexicales (1 p.)
Comme l'a vu plus haut (au I.2.2) la BDLex de Libellex a la même structure de BDLex que Metricc, et elle a été conçue à partir des mêmes formats d'échange. Nous présentons d'abord les formats d'échange, puis la BDLex correspondante.
a.
TBXMetricc (1 p.)
On a déjà mentionné les formats d'échange au I.2.2.1 et au I.2.2.2. Voici la structure Xml des entrées terminologiques spécifiée dans la norme ISO 30042 (TBX standard).
Une entrée terminologique (<termEntry>) représente un concept, exprimé dans une ou plusieurs langues (<langSet>) au moyen d'un ou plusieurs termes (soit <tig>, soit <ntig>[11]).
|
Figure 40 : Structure TBX standard |
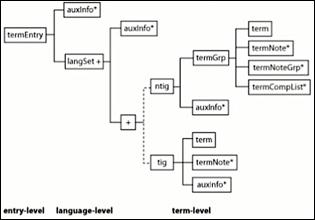
Dans le format TBX standard, deux termes en relation de traduction sont considérés comme appartenant à un même concept ; par exemple, il sont encodés dans deux <langSet> différents, à l'intérieur d'une même balise <termEntry>.
Dans le format TBXMetricc, deux termes en relation de traduction apparaissent dans des concepts (<termEntry>) différents. La relation de traduction est matérialisée au moyen d'une balise <descrip>, les reliant au niveau <langSet> et non au niveau <termEntry>.
Dans certains articles, E. Delpech a présenté <langSet> en disant que c'est le niveau des sens, et que <tig> ou <ntig> est le niveau des termes (mot-vedette et variante).
Cependant, cette présentation est contraire à l'explication qu'elle donne dans la spécification interne du format TBXMeTRICC (voir I.2.2.2.1).
Il nous semble qu'en fait <langSet> est le regroupement (complet ou partiel) des différents termes (<tig> ou <ntig>) de même sens.
D'une part, pour chaque balise <langSet>, les sous-balises <tig> ou <ntig> introduisent des termes de même sens. D'autre part, on peut avoir plusieurs <langSet> différents dans des <termEntry> différents pour une même langue, qui décrivent les mêmes sens. Il n'y a pas de relation monolingue entre deux entrées différentes.
Ainsi, TBXMetricc ne fournit aucun moyen pour vraiment décrire un sens comme un objet unique. C'est une organisation un peu trouble.
Nous sommes donc plutôt d'accord avec l'explication de E. Delpech au I.2.2.2.1. La relation de traduction au niveau <langSet> est l'équivalence sémantique entre termes simples ou composés, et c'est tout.
b.
TEIMetricc (0,5
p.)
TEIMetricc permet d'encoder uniquement le découpage en phrases des textes dont sont extraits les glossaires Metricc. La structure d'entrée de TEIMetricc est définie ci-dessous.
|
<TEI xml:id="IDENTIFIANT
UNIQUE"> <teiHeader> <fileDesc> <titleStmt> <title>TITRE
DU TEXTE</title> </titleStmt> <!--
Liste des types-mime ici : http://fr.wikipedia.org/wiki/Type_mime --> <sourceDesc
target="URI
RELATIVE DU DOCUMENT" mimeType="TYPE
MIME DU DOCUMENT"> <p>description
éventuelle du document original (elle peut être vide)</p> </sourceDesc> </fileDesc> </teiHeader> <text> <body> <s xml:id="IDENTIFIANT
UNIQUE"><![CDATA[UNE PHRASE]]></s> <s xml:id="IDENTIFIANT
UNIQUE"><![CDATA[UNE PHRASE]]></s> <s xml:id="IDENTIFIANT
UNIQUE"><![CDATA[UNE PHRASE]]></s> </body> </text> </TEI> |
Figure 41 : Définition d'une entrée TEI
c.
TSV (0,5 p.)
On a introduit TSV au III.1.1.2. L'import et l'export en format TSV ont été développés spécialement pour Libellex après l'intégration de la BDLex de Metricc dans Libellex. On peut noter que ce format n'est pas utilisé par Metricc.
I.3.1.1.2
Analyse
de la structure de la base lexicale (0,5 p.)
On a brièvement présenté la structure de la BDLex de Libellex au I.2.2.1 et au I.2.2.2. Nous devons ici aller plus dans le détail.
Il y a deux types de table : statique et dynamique. Les tables statiques sont créées une fois pour chaque BDLex lors de l'installation d'une instance de Libellex. Voir l'Annexe 7, qui donne le schéma de la base de données. Les tables en bleu sont les tables statiques.
Les tables dynamiques (les tables en jaune dans l'Annexe 7) sont créées lors de l'import d'un nouveau glossaire. Il y a deux sous-types de table dynamique, les tables de description et les tables de liaison. Les tables de description permettent de stocker les contenus des entrées, et les tables de liaison permettent de stocker les informations de relation. En voici quelques-unes.
· M_??_SETS[12] : table stockant les informations correspondant à la balise <langSet>.
· M_??_TIGS : table stockant les termes (vedettes et variantes) des balises <tig> et <ntig>.
· M_??_TIGS_SETS : correspondances entre entrées de SETS et de TIGS.
· M_??_CROSSLINGREL : relation de traduction entre deux SETS.
I.3.1.2 Contraintes industrielles (0,5 p.)
Outre la mauvaise qualité des ressources terminologiques fournies à L&M par ses clients (voir III.1.2.1), nous avons rencontré des problèmes de coût de maintenance et des limites fortes aux évolutions possibles chez les clients.
I.3.1.2.1 Coût de maintenance
Au début, nous avons proposé d'utiliser Jibiki comme plate-forme sous-jacente à Libellex. L&M a refusé cette solution, parce qu'il n'y avait aucun permanent de L&M qui connaissait la plate-forme Jibiki. Même si Jibiki est en source ouvert, après ma thèse, il aurait fallu avoir au moins une personne pour la maintenance.
I.3.1.2.2 Limites aux évolutions chez les clients
D'autre part, les systèmes Libellex sont installés indépendamment chez les clients comme des instances. Comme Libellex fonctionnait déjà chez des clients, on ne pouvait pas faire de gros changements des bases lexicales dans les instances de Libellex installées chez les clients. On n'aurait pu le faire que par des plugins, mais ça aurait toujours dû être compatible avec les ressources anciennes.
I.3.1.3 Spécification et
implémentation d'une solution ad hoc (1 p.)
I.3.1.3.1
Solution
ad hoc proposée (0,5 p.)
Nous[13] avons proposé une solution à deux niveaux, celui du modèle de BDLex et celui des instances spécialisées.
Nous avons enrichi la BDLex avec un champ type de valeur libre dans plusieurs tables.
· Le type dans la table de stockage des termes (TIGS), peut être mot-vedette, acronyme, abréviation, variante non typée, etc.
· Le type dans la table de stockage des relations sémantiques (LEXSEMREL), peut être parent ou enfant (c'est le cas dans la base de Louis Vuitton).
· Ces valeurs de type sont faciles à changer/ajouter selon les besoins des clients.
· On a également enrichi les statuts de validation pour représenter la qualité.
On a déjà dit que le format TSV est utilisé principalement pour les imports des données des clients chez Libellex. Nous avons développé une fonction d'import complexe à partir d'un fichier TSV pour améliorer les échanges de sources (les relations bilingues, les synonymes et les relations hiérarchiques parent/enfant etc). La Figure 42 montre l'interface d'import actuel de Libellex.
D'autre part, selon les besoins des clients, on a développé plusieurs formats spécialisés (par exemple pour le client Exalead). La Figure 43 montre l'interface d'export actuel de Libellex.
|
Figure 42 : L'interface d'import de Libellex |
Figure 43 : L'interface d'export de Libellex |

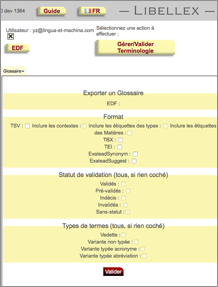
I.3.1.3.2 Résultats et validation (0,5 p.)
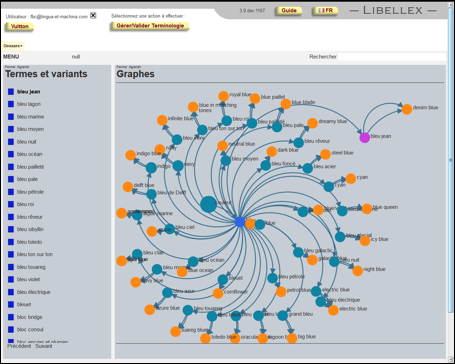
Dans certains cas, comme celui de Louis Vuitton, on s'est limité à une seule entrée dans la BDLex pour chaque terme. Par exemple, SAC DE VILLE ou ORANGE apparaissent dans plusieurs lignes dans la ressource (voir la Figure 36).
Si le terme est déjà créé dans la BDLex, on ne crée que la relation (relation parent/enfant et relation de traduction). Dans ce cas, on considère que le terme est au niveau du sens. Ce n'est certainement pas une solution totalement satisfaisante, et on ne peut pas faire la même chose pour tous les autres clients. Mais on a pu faire comme ça pour quelques autres clients.
I.3.1.4 Démonstration (1 p.)
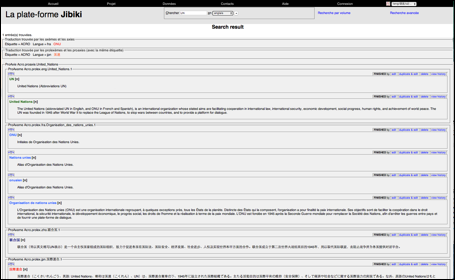
La figure ci-dessous montre un exemple de Louis Vuitton : l'affichage pour la consultation du mot blue jean avec les relations monolingues et la relation de traduction.
|
Figure 44 : Consultation de blue jean sur l'interface de Libellex |
I.3.2
Une solution plus générale basée sur Jibiki-2 : Pivax-3 (8 p.)
Au niveau du
laboratoire, il a été possible d'aller plus loin en utilisant la plate-forme Jibiki-2, qui permet d'implémenter de façon
naturelle les différents types d'objets lexicaux et leurs liens. Cela nous a
permis de produire un nouveau type de BDLex, Pivax-3.
I.3.2.1 Extension de l'architecture de Pivax-2 (5 p.)
Notre but était
d'unifier les 3 types de
données lexicales : mots (simples ou composés) généraux, termes (liés à un
domaine), et prolexèmes. Pour simplifier la conception, on a considéré qu'un terme est un type de prolexème.
I.3.2.1.1 Macrostructure (2 p.)
a. Types de volumes repris de Pivax-2 (0,5 p.)
On a repris les
trois types de volumes de Pivax-2 : lexie, axème et axie (voir II.2.2.1).
b. Nouveaux types de volumes (0,5 p.)
On a repris
et enrichi la notion de prolexème et on a introduit une nouvelle notion, celle
de proaxie.
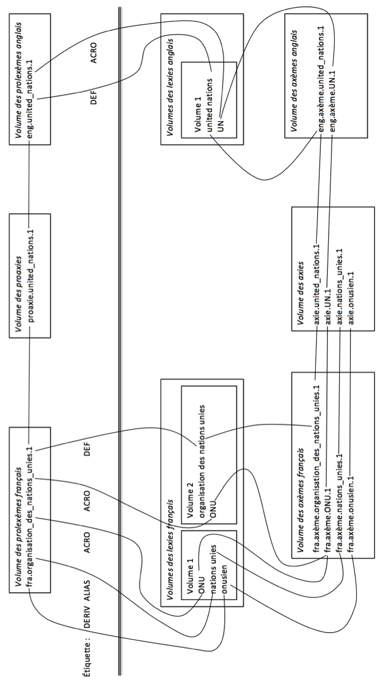
Définition 22. Prolexème. Dans une BDLex Pivax-3, il y a un seul volume de prolexèmes pour chaque langue. Dans ce volume, les prolexèmes regroupent les lexies qui représentent le même sens mais dont la réalisation syntaxique est différente (forme de surface, classe grammaticale, etc.).
Au contraire
de M. Tran, notre notion de prolexème n'est pas limitée aux noms propres. Les liens
bidirectionnels entre les lexies et leurs prolexèmes sont marqués avec une
étiquette libre (par exemple, alias, acronyme, dérivation, définition, etc.).
Par exemple,
l'entrée de type prolexème fra.organisation_des_nations_unies.1
est reliée aux entrées de
type lexie :
· ONU, par
un lien étiqueté acronyme.
· nations unies, par un lien étiqueté alias.
· onusien, par
un lien étiqueté dérivation.
· organisation des nations unies, par un lien étiqueté définition. Ce lien n'est pas la définition
lexicographique du prolexème, mais caractérise seulement le terme préféré pour
le décrire.
Définition 23. Proaxie. Il y a un seul volume de proaxies dans une instance de Pivax-3. Les proaxies regroupent les prolexèmes de langues différentes partageant un même sens.
Les liens
entre une entrée de proaxie et les entrées de prolexèmes sont bidirectionnels. Par
exemple, dans un dictionnaire trilingue français-anglais-chinois, l'entrée de
proaxie proaxie.united_nations.1 relie les entrées :
· fra.organisation_des_nations_unies.1 du volume des prolexèmes français,
· eng.united_nations.1 du volume des prolexèmes anglais,
· zho.联合国.1 du
volume des prolexèmes chinois.
c.
Macrostructure complète (1 p.)
|
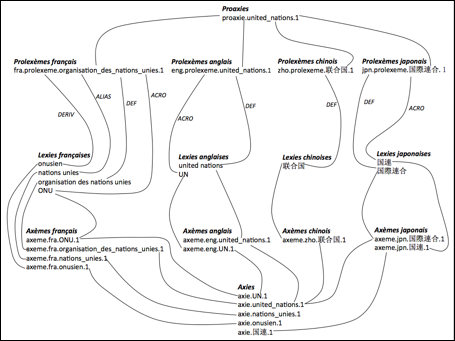
Figure 45 : Macrostructure de Pivax-3 |
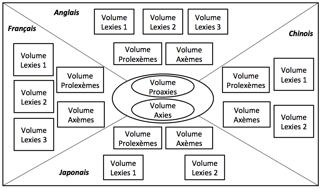
Dans cette macrostructure, nous avons deux couches : une couche basique et une couche "Pro". Dans la couche basique, nous gérons trois types de volume : les volumes de lexies, les volumes d'axèmes et le volume d'axies. Dans la couche "Pro", nous gérons deux types de volume : les volumes de prolexèmes et le volume des proaxies.
Grâce à la couche basique, nous pouvons relier les lexies qui se correspondent exactement, comme l'acronyme français ONU, relié à l'acronyme anglais UN.
Grâce à la couche "Pro", nous pouvons proposer en
traduction des lexies des langues cible de même sens. Par exemple, en chinois,
il y a un seul mot联合国 (lián hé guó) pour ce sens, et il
n'existe pas d'acronyme. Donc on peut toujours proposer le même terme 联合国 pour la traduction de ONU et la
traduction de organisation des nations unies. Voir la Figure 46.