Chapitre I Amélioration d’aspects fonctionnels et techniques de SECTra et du logiciel iMAG pour les passerelles d'accès multilingue
Ce chapitre présente la situation et l’état de l'art au début de la thèse, puis les améliorations de SECTra_w/iMAG étudiées et réalisées dans le cadre du projet Traouiero.
I.1 Situation
et état de l'art au début de la thèse
I.1.1 Modélisation et exploitation de corpus de traductions : SECTra_w
I.1.1.1 Présentation générale
I.1.1.1.1 Motivations et bref historique
En 2005-2007, notre équipe, alors le GETA du CLIPS, a participé au projet TRANSAT dans le cadre d’un contrat avec France Telecom R&D. Dans ce projet, nous avons utilisé la toute première version de SECTra, SECTra/Eval, pour organiser une campagne d’évaluation de l’utilité potentielle des systèmes de traduction automatique commerciaux dans le domaine de la traduction de la parole. Le domaine privilégié dans cette étude était l’assistance à un touriste en situation difficile. Une autre partie de l’étude portait sur le domaine de la restauration.
De février 2008 à octobre 2008, la deuxième version de SECTra, SECTra/Trad, a été dévloppée puis utilisée pour le projet EOLSS/UnescoL réalisé dans le cadre d’un contrat entre l’Association Champollion et la fondation UNDL[1]. Dans ce projet, SECTra a assuré le support et la gestion de la traduction de bonne qualité de 25 articles de l’encyclopédie EOLSS (Encyclopedia of Life Support Systems), soit environ 220K mots (880 pages standard), ou 13676 segments. En particulier, SECTra_w a fourni pour ce projet un environnent collaboratif en ligne pour la post-édition humaine appliquée aux résultats de systèmes de TA et de déconvertisseurs UNL.
Depuis 2009, la troisième version, SECTra_w, SECTra/Web, développée fin 2008, est utilisée comme "dorsal" pour l’accès multilingue de bonne qualité à des sites Web "élus". La conception et le développement de SECTra ont fait l'objet de la thèse de Cong Phap HUYNH (Huynh, 2010). À ce moment, mi-2010, nous avions alors construit des passerelles "iMAG" pour une trentaine de sites Web, dont celui du LIG. Chaque iMAG que nous avons construite apparaît comme un Wiki permettant l’accès multilingue à un site Web élu et la contribution à l'amélioration des traductions des segments (phrases et titres) de ses pages.
Essentiellement, une iMAG fournit une interface interactive permettant aux utilisateurs de voir et de post-éditer le site Web élu en plusieurs langues. En arrière-plan, tous les processus de gestion des segments "multilingualisés" du site Web sont réalisés par SECTra_w, par SegDoc (système de segmentation), et par Tradoh (intergiciel d'appel à des systèmes de TA).
I.1.1.1.2 Apports de la thèse de C.P. HUYNH
La thèse de C.P. HUYNH a apporté des réponses théoriques et pratiques à trois grands défis. Le premier défi consistait à offrir un support informatique unifié à l’évaluation des systèmes de TA. Le deuxième défi concernait le support contributif et collaboratif au travail humain sur des corpus variés en contexte multilingue. Le troisième défi était la construction d’un support informatique à l’exploitation de corpus de traductions dans des applications novatrices comme l’accès multilingue à des sites Web et la recherche d’information en contexte multilingue et multimédia (OMNIA). Plusieurs notions nouvelles ont été précisées (comme segment multilingualisé et contextualisé, pseudo-document, métadocument, etc.), et plusieurs principes généraux (proactivité, délégation, etc.) ont été introduits. C.P. HUYNH[2] a dégagé six problèmes associés à chacun de ces trois défis, à dominante conceptuelle (par exemple, définition étendue d’un « contexte » de segment), algorithmique (par exemple, programmabilité du traitement des corpus), et programmatoire (par exemple, traitement de masses de données).
I.1.1.1.3 Évolutions depuis début 2010
Jusqu’au milieu de l’année 2010, 30 iMAG
avaient été définies. Chaque
iMAG est associée à une mémoire de traductions (MT) gérée par SECTra_w. Une iMAG de
démonstration partage en général une MT avec d'autres iMAG. Les MT
partagées les plus utilisées sont demo, demo1, demo2. Voici
quelques données présentées dans la thèse de Phap (Tableau 1).
Tableau 1 : Sites Web élus des iMAG dédiées disponibles en 2010
|
LIG laboratory |
Digital Silk Road |
|
Danang city |
Da Nang University of Technology |
|
|
ISCC |
|
|
Systran |
|
|
Forum Lyon |
|
|
Campus France |
|
|
Floralis |
|
TechniLang |
Ordinaide |
|
|
aikicorenc |
|
|
Essilor |
|
|
Winsoft |
|
LeMonde.fr |
UNDL-foundation |
|
|
UNESCO_Babel |
|
|
ARDI Rhône |
Entre 2010 et 2012, avant le début de cette thèse, nous avons participé (lors d'un stage en alternance de M2P-GI puis d'un stage prédoctoral effectué dans le cadre du projet ANR Traouiéro) à l'amélioration SECTra_w, qui en est à la version 2. Grâce au configurateur d'iMAG réalisé par H. T. NGUYEN lors de son post-doctorat (projet iMAG/lametro en 2010 pour l'Expo de Shanghai en octobre 2010), le GETALP a créé 80 iMAG de démonstration, partageant 3 mémoires de traductions principales. Il y a 8 langues source, et chaque site Web peut être accédé en plus de 10 langues cible (en fait, dans toutes les langues traitées par GT, système qui en traite le plus) et 5 autres MT.
Début 2015, environ 45% des segments visités via une iMAG (plus de 370 000), et donc « pré-traduits » automatiquement, avaient été post-édités par des contributeurs. La post-édition a concerné majoritairement les paires anglais→chinois, anglais→français, et français→chinois, comme le montre le Tableau 2.
Tableau 2 : Données statistiques sur les segments post-édités dans SECTra_w depuis 2010
|
Paire de langues |
Bisegments |
Mots source L1 |
Mots cible L2 |
Taille de L1 |
Taille de L2 |
|
anglais
® français |
121 074 |
2 542 731 |
2 613 351 |
10,1Mo |
10,4 Mo |
|
anglais
® chinois |
208 106 |
4 370 530 |
6 063 942 |
19,1 Mo |
17,6 Mo |
|
français
® anglais |
29 079 |
627 661 |
610 098 |
4 Mo |
3,9 Mo |
|
français
® chinois |
10 890 |
228 703 |
317 322 |
1,5 Mo |
1,25 Mo |
|
chinois
® Anglais |
2 013 |
58 656 |
42 275 |
240 Mo |
263 Mo |
|
chinois
→ français |
10 062 |
291 192 |
211 185 |
874 Mo |
1 Mo |
I.1.1.2 Résumé des avancées et des limitations au niveau conceptuel
I.1.1.2.1 Avancées
Structure des
données. Les données sont
organisées autour des MT. L'administrateur peut créer une MT et la « dédier »
à un corpus (comme les 25 articles de EOLSS) ou à un pseudo-corpus (comme les pages Web
accessibles par un certain ensemble d'url), ou bien il la déclare comme « partageable »
par plusieurs iMAG. Dans la partie SECTra_w/iMAG, il n'y a pas de corpus bien identifié au
sens classique, sauf pour les MT dédiées. En effet, dans le cas d'une MT
partagée par plusieurs iMAG, ce sont toutes les pages Web (des "pseudo-documents" et pas des
documents, d'ailleurs) visitées depuis ces iMAG qui constituent "le corpus", qui
devient de fait l'ensemble des pages Web dont les segments ont été mis dans
cette MT. Il y a bien une avancée, puisqu'on peut traiter des pseudo-documents
et partager des MT, mais elle s'accompagne d'une confusion, sur laquelle nous
reviendrons plus loin.
Au moment de la
post-édition d'une page Web sous SECTra_w, on édite en fait la partie de la MT
constituée de l'ensemble (sans répétition) des segments apparaissant dans
l'instance de ce pseudo-document. Cet ensemble est présenté en une suite de
"pages logiques", chacune contenant un nombre maximum de segments,
paramétrable. La valeur par défaut est actuellement 20, car une page standard
contient en moyenne 20 phrases de 12 à 13 mots. Mais cela peut varier selon le
type de document. Si un segment apparaît plusieurs fois dans une page Web, la
suite des pages logiques ne correspond donc pas à la suite des segments dans la
page.
C'est un point
apparemment positif, puisqu'un segment répété ne sera post-édité qu'une
fois. Cependant, il serait préférable de
présenter la suite des segments dans l'ordre du document, sans éliminer les
segments répétés, mais en présentant toutes leurs post-éditions dans leurs
occurrences successives. En effet, deux occurrences d'un même segment dans une
page Web, et plus généralement dans un document, peuvent devoir être traduites
différemment. Par exemple, dans le site Web du LIG, le segment « Recherche » doit
être traduit par « Search »
s'il apparaît dans un onglet de navigation, et par « Research » si c'est un item du plan du site.
Un point très
important est que chaque segment source a un identifiant unique qui est utilisé
pour le lier avec les éléments qu'on considère comme ses annotations (des
traductions automatiques avec leur origine, des post-éditions avec leurs scores
et leur dernier contributeur, et on pourrait avoir une liste de versions, un
minidictionnaire, un graphe UNL, etc.).
Appel de systèmes de TA. SECTra_w permet de
paramétrer la liste des systèmes de TA appelés (comme GT, Systran, et Reverso) pour produire des traductions
candidates. Pour cela, il utilise
l'intergiciel Tradoh (originellement créé en 2002-2003 par Hung VO-TRUNG (Vo Trung, 2004) dans le cadre de sa thèse, puis revu par
nous en 2013.
Support de l’évaluation de systèmes de TA. SECTra_w supporte l’évaluation de systèmes de TA
depuis sa première version, mais cette partie est restée indépendante du reste.
En particulier, la partie concernant la PE contributive ne permet pas de faire
de l'évaluation subjective classique. On se contente d'un « score de
qualité » défini à partir du profil du dernier contributeur à la PE d'un
segment, et modifiable par les contributeurs inscrits et connectés.
La partie dédiée à
l'évaluation reste très intéressante. Décrivons-la brièvement. SECTra/Eval intégrait
dès octobre 2007 des outils d’évaluation subjective[3] et objective[4]. On peut effectuer les deux types les plus
courants d’évaluation subjective (adéquation, fluidité) en utilisant
plusieurs juges, pour un ou plusieurs systèmes de TA à la fois.
L'administrateur d'une campagne d'évaluation peut interdire ou permettre à
plusieurs juges d’effectuer l’évaluation subjective sur la même unité de
données (segment). Les libellés et le nombre de réponses possibles sont
paramétrables. Au total, on peut définir de nombreuses configurations de
campagnes d'évaluation. Il y a bien sûr aussi les outils d'import, d'export, et
de calcul de résultats.
SECTra_w/Trad fournit de plus des
interfaces graphiques pour faciliter la sélection de données (tout ou partie
d’un corpus), et le lancement des programmes de calcul des mesures d’évaluation
objective sur les données sélectionnées.
« Base corporale ». SECTra_w est une sorte de « base corporale[5] », Il fournit des services Web pour l’exploitation de corpus multilingues, l’amélioration des traductions, et l’extension « en largeur » à d'autres langues, par appel à des serveurs de TA. Depuis 2008, SECTra_w permet la post-édition collaborative de pages Web à l’aide d’un ou plusieurs systèmes de TA, et leur évaluation par la distance de post-édition, qui est assez bien corrélée au temps passé à la post-édition, ce qui donne une bonne mesure de « qualité d'usage », pour la post-édition tout au moins.
SECTra_w, et d'ailleurs aucun système d'évaluation de TA, ne donne de moyen d'évaluer la qualité d'usage quand l'utilisateur est une personne ne connaissant pas la langue source et cherchant à comprendre une page Web. Dans le cas où il s'agit d'un système de e-commerce, on devrait pouvoir le faire en mesurant le nombre d'achats par rapport au nombre et à la durée des visites, mais ce n'est qu'une hypothèse. Dans d'autres cas, par exemple l'accès à des manuels scientifiques, on pourrait évaluer la compréhension "via la traduction" par une technique de QCM[6].
Dans cette thèse, nous nous limitons à l'évaluation de la
qualité d'usage quand les utilisateurs font de la post-édition.
Notions. Lors de la conception de SECTra_w, C. P. HUYNH a clarifié et bien défini plusieurs notions, comme segment monolingue multilingualisé, pseudo-document, métasegment, super-segment, infra-segment, etc.
Nous les reprenons ici, et en introduisons quelques-unes dont la nécessité est apparue durant le projet Traouiero.
I.1.1.2.2 Définitions de diverses notions
Les définitions nouvelles sont signalées par une étoile.
a. Phrase et groupe
Définition 1. Une phrase (sentence en anglais) est l’unité élémentaire d'un énoncé, formée de plusieurs mots ou groupes de mots, et qui présente un sens complet. (TheFreeDictionary[7]).
Définition 2*. Un syntagme ou groupe (phrase en anglais) est un constituant possible d'une phrase. En général, un titre est un groupe nominal.
b. Segment, fragment, élément non textuel (hors-texte)
Définition 3. Un segment est l’unité de traduction de base des traducteurs humains.
Il s’agit d’une phrase, d’un titre, ou d’un terme dans une nomenclature.
Définition 4*. Un fragment (chunk en anglais) est une partie d'un segment, qui peut être un groupe syntaxique (phrase en anglais) ou un simple n-gramme.
Définition 5*. Un segment peut contenir des éléments non textuels, ou hors-texte, comme des images, des formules, ou des balises, qui ont un rôle linguistique et une valeur non linguistique.
Ainsi, une image ou une expression mathématique fonctionne usuellement comme un groupe nominal, une relation mathématique fonctionne comme un groupe nominal ou un groupe verbal, et une balise peut seulement contrôler la présentation (gras, souligné) ou avoir aussi un rôle de ponctuation (élément de liste à puces par exemple).
On appelle aussi « segment » (en TMX ou en XLIFF) un segment source accompagné d’une ou plusieurs traductions. Il faut donc raffiner la définition précédente.
Dans le format TMX[8] (Translation Memory eXchange), un segment multilingue est représenté par un élément <tu>.
Par exemple :
|
|
Si N = 2, 3…, on parle de segments bilingues, trilingues, etc. On appellera donc segment monolingue un segment multilingue réduit à un seul segment (source).
Définition 6. Un segment monolingue est un segment dont le contenu textuel est en une seule langue.
Définition 7*. Un segment multilingue est un segment dont le contenu textuel est dans plusieurs langues, chaque version étant considérée comme contenant exactement la même information, exprimée de façon correcte.
C'est par exemple le cas des segments contenus dans des documents de brevet (voir VII.2.1).
Définition 8. Un segment monolingue multilingualisé (annoté) est un objet contenant un segment « source » primaire, une ou plusieurs traductions (automatiques ou humaines ou automatiques post-éditées) pour une ou plusieurs langues, et des annotations, en général des objets, comme des arbres linguistiques, des graphes UNL, des résultats d’évaluation(s), et des références aux contributions ayant produit chaque objet non primaire.
Définition 9*. Un segment multilingue multilingualisé (annoté) est un objet contenant un segment multilingue, dans N langues « sources », et, dans M autres langues, une ou plusieurs traductions (automatiques ou humaines ou automatiques post-éditées), ainsi que des annotations, comme celles d'un segment monolingue multilingualisé et annoté.
Définition 10*. Le chemin traductionnel d'une annotation, en particulier d'une traduction ou d'une post-édition, est la suite des opérations l'ayant produite, ainsi que les intervenants humains impliqués, et les éventuels objets auxiliaires utilisés.
Par exemple, une traduction français-chinois peut avoir été produite par le chemin traductionnel :
TA (Systran, fr_en);
PE(Zhong, Sectra); TA(Neon, en_zh); PE(Wang, Sectra);
Dans une version antérieure, on avait écrit qu’il s'agit d'une relation entre deux segments, dans un certain contexte, et avec un
c. Métasegment, document, métadocument
Définition 11*. Un métasegment est un segment comportant une ou plusieurs variables, éventuellement typées (nombre, date, balise faible…).
Définition 12*. Un document est un ensemble formé par un support et une information, celle-ci enregistrée de manière persistante. Nous nous intéressons aux documents textuels, qui contiennent des "segments" textuels.
Définition 13*. Un métadocument est un document pouvant contenir des métasegments.
Définition 14*. Un pseudo-document est
défini par une référence (nom de fichier, url, uri) à un document qui peut
varier au cours du temps.
Par exemple, une page Web peut changer un peu, pas du tout ou totalement d'un appel au suivant.
· Un petit changement peut être dû au fait que le document est en fait un métadocument, et qu'au moins une valeur d'une variable d'un métasegment a changé (par exemple, la date, ou le nombre de visites).
· Un changement total peut être dû au fait que l'instance précédente a été remplacée par un document tout à fait différent. C'est par exemple le cas d'une page Web contenant chaque jour des nouvelles, ou un nouvel éditorial (comme le "World Web" de l'Unesco).
d. Contexte
Définition 15. Contexte :
Le contexte m-n d’segment source par
rapport à un document, ou plus généralement à une instance d’un
pseudo-document, est défini par :
-
la liste des m segments (de même
langue) qui le précèdent.
- la liste des n
segments (de même langue) qui le suivant.
- l’instanciation des variables,
s’il y en a, dans ces m+n+1 segments.
Le contexte m-n d’un segment (cible)
dans une version résultat de TA ou de PE, dans un segment monolingue, ou
multilingue multilingualisé, est défini par
- la liste des m segments (de même langue et de même
version) qui le précèdent.
- la liste des n segments (de même langue et de même
version) qui le suivant.
- l’instanciation des variables,
s’il y en a, dans ces m+n+1 segments
pour la même version.
Deux résultats de TA appartiennent à la même version s’il ont été produits par la même instance du même système de TA.
Deux post-éditions appartiennent à la même version si elles apparaissent dans la même version d’un document (ou pseudo-document) post-édité.
Par conséquent, le contexte d’une PE peut dépendre du choix des PE des segments précédents et suivants. Exemple : 2 réviseurs choisissent des PE différentes dans la MT et produisent 2 versions (tout à fait correctes) du même document.
I.1.1.2.3 Limitations
Absence d'une définition claire des "corpus" et des "corpus de traductions". Cela est dû au fait que SECTra_w d'abord été développé pour ce qu'on appelle des corpus parallèles en TA statistique, c'est-à-dire des listes de segments se correspondant dans une ou plusieurs langues, sur le modèle du BTEC (Basic Travel Expression Corpus) d'ATR (Boitet, Boguslavskij et al., 2007). Dans un second temps, on a traité un "vrai" corpus (monolingue), formé de 25 articles de l'encyclopédie EOLSS, présentés dans autant de fichiers .aspx et de fichiers compagnons .unl, auxquels on a attaché les traductions en français de chaque segment. Enfin, on a traité des corpus en quelque sorte virtuels, formés des pseudo-documents correspondant aux pages Web de tel ou tel site Web.
Définition 16*. Un corpus est un ensemble usuellement fermé de documents homogènes du point de vue de leur structure, de leur(s) langue(s), de leur genre et de leur domaine.
Par exemple, on peut parler du corpus (monolingue) des articles du Monde sur la culture de 2000 à 2002. Le caractère fermé est relatif, car on considère que certains corpus croissent par adjonction de nouveaux ensembles. Par exemple, le corpus bilingue Hansard des débats du Parlement canadien peut être considéré comme une suite de corpus annuels, le dernier étant en construction.
Définition 17*. Un corpus de traductions est un corpus au sens précédent, contenant les traductions de tout ou partie de ses segments, dans une ou plusieurs langues.
Absence de traitement des corpus à proprement parler. SECTra_w permet l’exploitation de corpus existants, l’évaluation des traductions et l'élargissement à plus de langues, mais n'est pas assez générique. Par exemple, il ne permet pas la création de nouveaux corpus (au sens classique), ni l’annotation selon des critères librement définissables par un linguiste. Ce progrès était prévu dans la thèse de Phap, mais n'a pas encore été réalisé.
Décalage de segments. SECTra_w appelle les systèmes de TA pour produire des pré-traductions, et le fait maintenant via l'intergiciel Tradoh, mais il lui manque un sous-système pour synchroniser et gérer les segments source et les résultats de traduction. Parfois, un système de TA renvoie plusieurs résultats de traduction pour un même segment, et alors SECTra_w les aligne avec d'autres, ce qui détruit la cohérence des bisegments, au moins jusqu'à ce que ces autres segments soient (re)traduits et que leurs résultats soient bien alignés.
Confusion de notions. En SECTra_w, il y a plusieurs confusions entre des notions très différentes, ce qui bloque certaines avancées souhaitables. Par exemple, il y a confusion entre "mémoire de traductions" et « projet ». Quand l’utilisateur crée un nouveau « projet », en effet, le système crée une nouvelle MT. Mais un projet devrait pouvoir concerner plusieurs MT à la fois, ou une seule MT, existante, si par exemple on veut y ajouter des annotations telles que des arbres linguistiques, ou des caractérisations d'erreur. Or, cela ne justifie pas la création de nouvelles MT.
Il y a aussi dans l'actuel SECTra_w une confusion entre « corpus » et « mémoire de traductions ». Cela est dû, historiquement, à l'évolution vers le traitement de pages Web. Auparavant, dans le projet EOLSS par exemple, on avait un vrai « corpus », c'est-à-dire une collection organisée de documents, avec leurs fichiers satellites (images, etc.) et leurs fichiers compagnons (pour EOLSS, des fichiers de graphes UNL). Après segmentation, on introduisait les segments dans la MT, et les documents n'étaient plus supposés changer. On pouvait donc facilement noter dans la base de données toutes les occurrences d'un segment[9].
Avec les pages Web, on a dû traiter des pseudo-documents, c'est à dire des documents qui ont le même nom (une url), mais qui peuvent changer d'un appel à l'autre. On a essayé d'adapter la méthode précédente, mais la solution retenue est source d'erreurs et augmente considérablement le temps de recherche d'un segment. Elle consiste en effet à associer une petite MT à chaque pseudo-document, liant ainsi corpus et MT. Quand on traite une page Web, on regarde dans sa MT s'il a déjà été vu, et si oui on prend la meilleure PE qu'on y trouve. Mais ce segment a pu être déjà post-édité dans un autre pseudo-document (une autre page Web), et du coup le système peut présenter une sortie de TA au lieu d'une PE déjà faite. De plus, si le système ne trouve pas le segment dans la MT du pseudo-document, il le cherche dans tous les autres documents du même "corpus", ce qui peut faire beaucoup, et cela d'autant plus que, si la MT est partagée, il y a des pseudo-documents liés à d'autres iMAG qui sont examinés, alors que, conceptuellement, ils sont dans un corpus différent.
La solution serait de reprendre toutes ces MT, de les fusionner avec la MT principale, et d'associer simplement à chaque pseudo-document la liste des segments déjà vus dans une des instances de ce pseudo-document, et, pour chaque instance, de construire un « document squelette » constitué du code html et de références aux segments présents dans cette instance.
I.1.1.3 Résumé des avancées et des limitations au niveau algorithmique (conception informatique)
I.1.1.3.1 Avancées
Post-édition "sans couture". SECTra_w communique avec la partie iMAG, qui peut être considérée comme un "frontal" permettant la post-édition directement sur la page Web, ce qu'on appelle la post-édition "sans couture". Cela veut dire qu'on ne change pas de contexte entre lecture et correction d'une page Web. De plus, quand l’utilisateur fait de la post-édition dans la page Web, il peut visualiser la page Web source en parallèle. Un autre aspect de cette communication est qu'on peut passer de la post-édition d'un segment sur la page Web à sa post-édition dans la page (logique) de post-édition "avancée" de SECTra contenant ce segment, puis revenir à la page Web, à l’endroit où on était, une fois qu'on a post-édité quelques segments en mode "avancé". En pratique, les post-éditeurs experts utilisent les deux modes. Le mode avancé leur permet de post-éditer très vite de nombreux segments, et le mode sans couture leur permet de voir l'ensemble de la page Web, et de corriger de petites erreurs qui sautent aux yeux alors qu'on les repère mal dans les petites zones de texte (textareas) de l’interface de PE de SECTra_w.
Possibilité de partager des MT. Le fait qu'une MT puisse être partagée par une ou plusieurs iMAG est un avantage si les sites Web "élus" sont comparables, et plus précisément si leurs sous-langages diffèrent peu. C'est par exemple le cas de sites de tourisme, ou de sites de villes, ou de sites de cours d'informatique en ligne. En effet, des segments identiques (parfois longs) apparaissent alors, et la post-édition d'un site peut bénéficier à un autre.
Gestion des utilisateurs. SECTra_w utilise le même type de gestion des utilisateurs que XWiki, avec deux niveaux : individu et groupe, un individu pouvant appartenir à plusieurs groupes. Il serait préférable de séparer SECTra_w du logiciel iMAG et de créer un service unique faisant le lien entre ces gestionnaires d'utilisateurs, par exemple fondé sur un annuaire du genre LDAP, de façon à éviter de demander à un contributeur de s’authentifier plusieurs fois alors qu'il a tous les droits nécessaires.
SECTra_w associe à chaque utilisateur un profil général incluant des informations sur ses compétences et ses droits en général (par exemple, un utilisateur peut accéder à la MT demo1, mais pas aux autres MT). Il faudrait aussi associer à chaque utilisateur un raffinement de son profil, pour chaque projet. Par exemple, quelqu'un pourrait être administrateur mais pas post-éditeur dans un projet, et l'inverse dans un autre.
I.1.1.3.2
Limitations
Structure de la base de données. Quand l’administrateur crée un
« projet » dans SECTra_w, il crée une nouvelle « mémoire de
traductions », qui donne lieu à la création d'une nouvelle base de données
(BD) en MySQL. Quand l’utilisateur crée une iMAG associée à cette MT, SECTra_w crée 3
tables dans cette BD. La première table contient tous les segments source. La
deuxième contient tous les segments cible traduits par un ou plusieurs système
de TA. La troisième contient les post-éditions des segments post-édités en au
moins une langue cible.
Par exemple, le
site Web du LIG est en français. Ce site contient une centaine de pages Web, et son iMAG, donc aussi SECTra_w, prévoit
plus de 30 langues cible. Donc, à une page Web du site LIG, SECTra_w associe une table source, une ou plusieurs
tables contenant les TA, et plus de 30 tables contenant les segments
post-édités. Cette structure de BD est difficile à manipuler, et augmente la
complexité de la recherche de l’information. Cette limitation provient d'un
mauvais choix au niveau du schéma conceptuel, et par suite du schéma logique
des MT.
Passage à l’échelle. SECTra_w, dans son état de 2011, était donc basé sur
un schéma conceptuel de la structure des données, qui a mené à un schéma
logique multipliant les tables, et ne permettant pas de traiter efficacement de
grosses quantités de données. Nous savions donc qu'il faudrait intervenir à ce
niveau pour pouvoir réellement passer à l’échelle.
I.1.1.4 Résumé des avancées et des limitations au niveau de l'implémentation
I.1.1.4.1 Avancées
Import de corpus pour l’évaluation. SECTra_w permet d’importer divers corpus multilingues disponibles et de faciliter la sélection des corpus source pour organiser des campagnes d’évaluation. SECTra_w accepte des fichiers d’entrée en format texte (.txt). Au niveau physique, chaque corpus[10] peut être constitué par un fichier source contenant des segments source, un ou plusieurs fichiers de traductions "candidates" (produites par différents systèmes de TA ou vers différentes langues) à évaluer, et un ou plusieurs fichiers de traductions de référence. Cependant, un corpus d’évaluation peut ne contenir que des segments source, car SECTra_w permet de produire des traductions candidates par appel de TA, et des traductions de référence par post-édition en ligne. Au niveau interne, les segments dans les fichiers (source, candidats, et références) sont alignés.
Convivialité et souplesse de l'interface. L’interface de SECTra_w permet de changer la taille des colonnes, et de cacher/montrer des colonnes en utilisant la souris ou un tableau de configuration. Les utilisateurs peuvent choisir le nombre de segments affichés à chaque fois sur l’interface. Leurs travaux sont enregistrés automatiquement et les données déjà manipulées sont distinguées des autres au niveau de la couleur du fond.
Mode de lecture et
mode avancé. SECTra_w/iMAG offre deux interfaces de
post-édition. Le premier est intégré au mode de lecture. L’utilisateur peut
faire la post-édition sur le document, et voir très facilement l’effet de la
post-édition dans le contexte de lecture. Le deuxième est un mode « avancé ».
L’utilisateur peut se concentrer sur le segment. Les segments sont bien
présentés dans les pseudo-documents.
API. XWiki permet de publier des services, et ainsi d’outiller leur utilisation par des logiciels tiers. Cela est fait dans SECTra_w pour les fonctions de recherche exacte d’un texte dans un corpus (TM exact search by API) et pour mettre à jour la traduction mémorisée pour un texte dans un corpus (Update TM by API).
I.1.1.4.2 Limitations
XWiki et serveur de déploiement. SECTra_w a été développé en utilisant la plate-forme XWiki (version 1.3.1), la technologie Ajax, et les langages de script Javascript, Groovy et Velocity. Depuis 2010, SECTra_w n'a pas suivi les mises à jour de XWiki. Passer à une version plus récente de XWiki comme la version 7 serait actuellement extrêmement lourd et risqué, car le langage Velocity (d'Apache Foundation) qui permet de traiter les BD MySQL a lui-même changé. C'est pour cela que SECTra_w est déployé sur Tomcat 5, correspondant à l'ancien Velocity, et qu'on ne peut pas passer à Tomcat 6 ou 7 pour l'instant. Enfin, une autre limitation est que XWiki n’est pas très compatible avec certains navigateurs tels que IE, car il utilise des fonctions évoluées (comme Ajax) qui ne sont pas encore standardisées sur les différents navigateurs.
Export. SECTra_w offre une fonction capable d'exporter le résultat de la campagne TRANSAT, mais n’a pas de fonction permettant de réaliser l’export sur les MT génériques, comme la grande MT lametro. Il n’y pas non plus de moyen de choisir les segments post-édités.

Absence de l'aide lexicale proactive annoncée. Dans sa thèse, C.P. HUYNH a présenté la conception d'une aide lexicale proactive intégrable à SECTra_w, sous la forme d'un "minidictionnaire" précalculé et associé à chaque segment. De son côté, H.T. NGUYEN avait réalisé une fonction permettant de produire un minidictionnaire à partir d'une liste de mots, par lemmatisation, recherche dans une BD lexicale PIVAX, et formatage en HTML. Mais la jonction des deux n'a pas pu être réalisée avant leur départ du laboratoire.
I.1.2 Accès
multilingue à des sites Web : le logiciel iMAG
I.1.2.1 Présentation générale
I.1.2.1.1 Bref historique et motivations
Le concept d'iMAG a été proposé par Ch. Boitet et V. Bellynck en 2005 (Boitet et al., 2005), étudié en 2006 et 2007 par les brais de projets d’étudiants, et a atteint l'état de prototype opérationnel grâce à C.P. HUYNH en novembre 2008 (Boitet et al., 2008), avec une première démonstration sur le site Web du laboratoire LIG. Il a été adapté au site Web DSR (Digital Silk Road) en avril 2009 par C.P. HUYNH, puis à plus de 80 autres sites Web grâce au configurateur réalisé par H.T. NGUYEN. Ces iMAG servent à des démonstrations et à des expérimentations. Citons ici (Boitet et al., 2010).
Une iMAG est une passerelle interactive
d'accès multilingue (interactive Multilingual Access Gateway), ressemblant
beaucoup à Google Translate, à première vue : on donne une URL (site Web
de départ) et une langue d'accès, et on navigue ensuite dans cette langue
d'accès. Lorsque le curseur passe sur un segment (le plus souvent une phrase ou
un titre), une palette montre le segment source et propose de contribuer en corrigeant
le segment cible, en fait en post-éditant un résultat de traduction automatique
(TA). Avec Google Translate, la page ne change pas après la contribution, et si
une autre page contient le même segment, sa traduction est toujours le résultat
de TA grossière, pas la version polie post-éditée. La boîte à outils de
traduction Google Translation Toolkit permet de traduire par TA et ensuite de
post-éditer en ligne des pages Web complètes tirées de sites tels que
Wikipédia, mais, de nouveau, les segments corrigés n'apparaissent pas quand on
regarde plus tard la page de Wikipédia dans la langue d'accès.
En revanche, une instance d’iMAG (dite
iMAG-S) est dédiée à un site Web élu (S), ou plutôt au sous-langage défini par
une ou plusieurs URL et leur contenu textuel. C’est un bon outil pour rendre S
accessible dans beaucoup de langues, immédiatement et sans responsabilité
éditoriale. Les visiteurs de S ainsi que des post-éditeurs et des modérateurs
payés ou non contribuent à l’amélioration continue et incrémentale des segments
textuels les plus importants, et éventuellement de tous.
Une instance iMAG-S contient une MT.
Les segments sont pré-traduits non pas par un système de TA unique, mais par un
ensemble (sélectionnable) de systèmes de TA gratuits. Systran et Google sont
principalement utilisés aujourd'hui, mais des systèmes spécialisés, développés
à partir de la MT post-éditée, vont bientôt être utilisés. Les visiteurs de S
ainsi que des post-éditeurs et des modérateurs payés ou non contribuent à
l’amélioration continue et incrémentale des segments textuels les plus
importants, et éventuellement de tous.
Les plates-formes contributives puissantes SECTra_w sont utilisées pour supporter les MT. Les pages traduites sont construites avec les meilleures traductions des segments disponibles au moment de l’accès. Pendant la lecture d'une page traduite, il est possible non seulement de contribuer au segment sous le curseur, mais aussi de passer de façon transparente sous l'environnement de post-édition en ligne de SECTra_w, muni de bonnes fonctions de filtrage et de recherche-remplacement, et ensuite de revenir dans le contexte de lecture.
I.1.2.1.2 Lancement de maquettages
Deux « maquettes » d’iMAG ont été étudiées avant novembre 2008, par Mohammad Daoud dans son M2R (Daoud, 2007), et par Carlos Ramisch dans son stage ENSIMAG (Ramisch, 2008).
Le premier n'a pas pu produire la maquette prévue, car il avait voulu écrire lui-même un segmenteur de pages Web (en "segments textuels", c'est à dire en phrases ou titres), alors qu'on l'avait prévenu qu'il s'agissait d'un problème difficile et qu'on lui avait demandé d'utiliser indirectement GT comme segmenteur.
Dans le cadre d'un projet du LIG appelé "iMAG/LIG", financé par 5 ou 6 mois de bourses CNRS du LIG, C. Ramisch a voulu lui aussi construire un prototype complet à partir de zéro. Il avait prévu d'utiliser Lingpipe[11] pour la segmentation, mais il aurait fallu l'adapter aux pages Web. Il n'a pas eu le temps d'implémenter ce qu'il avait spécifié, car c'était un trop gros travail pour le temps disponible. Malheureusement, une fois son projet soutenu, il n'a pas pu "passer la main", étant pris à la fois par les cours de M2R et un stage à XRCE.
I.1.2.1.3 Prototype opérationnel de C. P. HUYNH
Durant l'été 2008, dans le cadre du même projet iMAG/LIG, C. P. HUYNH et H. T. NGUYEN ont travaillé sur le site Web du LIG, pour segmenter ses pages et aligner les segments déjà traduits en anglais. Le meilleur segmenteur qu'ils avaient trouvé était justement celui de GT. L'idée était qu'ils fournissent au logiciel iMAG en construction une MT initiale pour le site du LIG, en appelant GT sur les segments non traduits. Comme ce logiciel attendu n'était pas disponible, Phap a proposé de le réaliser très vite, par extension de SECTra, qui était déjà assez mûr, ayant été utilisé par des dizaines de contributeurs dans le cadre du projet EOLSS-UNDL.
En à peine 3 semaines, juste avant de partir pour un stage prédoctoral international au Japon (NII), il a produit un premier prototype opérationnel, et une première iMAG, l'iMAG-LIG, qui a pu être démontrée à la direction du LIG (B. Plateau) vers le 20/11/2008.
Le fonctionnement est le suivant. La page consultée est accédée via la passerelle iMAG, qui réécrit les url de façon à ce que les pages accédées par la suite lors de la navigation passent aussi par elle. La page à traduire est envoyée à GT, on récupère le résultat, puis on détecte les segments marqués par GT. On les cherche alors dans la MT, et on les ajoute s'ils n'y sont pas. Dans les deux cas, on met aussi dans la MT associée à l'iMAG les (pré)traductions produites par GT. La page traduite est reconstruite à partir du code HTML de la page source, des meilleures traductions des segments (trouvées dans SECTra_w), et de code JavaScript spécifique.
Au tout début, l'iMAG-LIG produite
par le projet iMAG/LIG contenait la traduction
d’environ environ 2000 segments du site Web du LIG.
Elle en contient maintenant près de 15000.
I.1.2.1.4 Évolutions depuis début 2010
Début 2010, une iMAG dédiée a été créée pour la Métro de façon à permettre l'accès à son site Web en chinois et en anglais à l'occasion de l'exposition universelle de Shanghai qui eut lieu en octobre 2010. Ce fut la première expérience en grandeur réelle.
Ensuite, plusieurs sites iMAG à mémoire de traductions dédiée ont été créés. La table suivante donne les URL des sites principaux.
Tableau 3 : Liste des iMAG à MT dédiée construites depuis 2010
|
Nom abrégé |
Accès au site élu : remplacer dans http://service.aximag.fr/xwiki/ |
Page d'accueil de chaque site : |
|
Expo de Shanghai |
lametro |
|
|
Projet Traouiero |
traouiero |
|
|
Projet MACAU |
macau |
|
|
AMIES |
AMIES |
|
|
Grenoble INP |
GINP |
|
|
Powers |
Powers |
http://www-clips.imag.fr/geod/User/laurent.besacier/ |
|
Michelin |
Michelin |
|
|
Bio Clean |
Bio-Clean |
|
|
Projet Akenou |
akenou |
De nombreuses iMAG ont aussi été créées sur des MT partagées. En particulier, une a été créée dans le cadre d'un projet de l'ISCC (institut des sciences de la communication), un institut du CNRS dirigé par Dominique WOLTON.
I.1.2.2 Conception générale avec implémentation "intégrée"
Voici un peu plus de détails sur l'implémentation du logiciel iMAG, "intégré" à SECTra. Lors du projet ANR Traouiero, V. Bellynck a prévu de la rendre plus modulaire, grâce à l'introduction d'un "relais iMAG", de l'utilisation de Tradoh pour appeler les systèmes de TA, et de l'utilisation de SegDoc pour effectuer la segmentation-normalisation, mais cette transformation n'est pas encore terminée.
Voici le schéma de l'architecture logicielle actuelle.
|
|
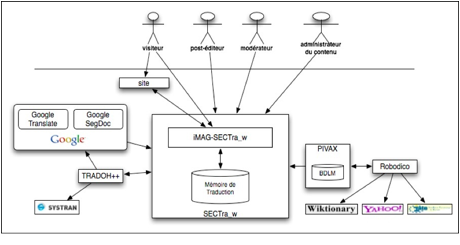
Figure 1 : Architecture générale d’une iMAG pour un site élu
Lorsque le visiteur demande à accéder au site élu S dans une autre langue que la langue source, la page d’accueil de S est envoyée à GT de façon à récupérer le découpage en segments de texte, et les traductions de chacun des segments par cet outil, s’il supporte les langues désirées en source et cible. Ultérieurement, lors de la navigation interne au site S, chaque page de S est traitée par le même procédé.
D’autres outils de traduction automatique comme Reverso, Systran ou Bing peuvent être utilisés pour prétraduire chaque segment. Les segments traduits sont mémorisés comme les correspondants (dans la langue de visite) des segments d’origine.
Dans la page Web reconstruite par l'iMAG, le texte de chaque segment en langue source est remplacé par le texte correspondant en langue cible, et le code nécessaire à l’insertion d’une bulle contextuelle (surgissant au survol par le curseur de chaque segment) est ajouté avec le texte dans la langue source, le couple (segment en langue source, segment en langue cible) constituant une correspondance de segments pour le système SECTra_w.
|
|
![Description : Mavericks:Users:lingxiaowang:Documents:Papiers:[MTS-WPTP 2013] iMAG:[MTS-WPTP 2013]iMAG_V1+2:Capture d’écran 2013-05-30 à 09.54.39.png](Am%C3%A9lioration%20d%E2%80%99aspects%20fonctionnels%20et%20techniques%20de%20SECTra%20et%20du%20logiciel%20iMAG%20pour%20les%20passerelles%20d_fichiers/image030.png)
Figure 2 : Capture d'écran de l’iMAG LIG-LAB en
chinois
La bulle contextuelle est appelée « bulle-iMAG ». Elle montre le texte du segment en langue source, et présente un bouton dont l’action associée transforme la bulle en une bulle de contribution : elle contient alors un formulaire dont une zone de saisie de texte (« textarea ») permet de modifier à la volée la traduction proposée. Le visiteur peut alors contribuer à l’amélioration de la traduction de ce segment de la page Web courante selon son droit d’édition et le mode de publication du site. Une fois que la contribution est envoyée, elle est stockée dans une table associée à la page en question, identifiée par son URL comme un pseudo-document, et il y a une duplication dans une table globale des segments source-cible pour chaque site. Donc, dans une page, s’il y a un même segment (par exemple un item de menu, ou une phase type) qui est déjà traduit dans une autre page, la traduction est proposée avec la mention « Mémoire de traductions ».[12]
Dans l’architecture complète prévue, on a intégré l'aide lexicale proactive, ce qui explique pourquoi PIVAX apparaît dans le schéma suivant, tiré de la thèse de H.T. NGUYEN. On construit des instances spécifiques de composants SECTra_w (pour la MT), de PIVAX (pour la base lexicale) et d’une iMAG dédiée. Il y a une connexion entre ces instances locales et une instance centrale de données afin d’initialiser les données pour un nouveau site.
Dans cette architecture, SECTra_w, PIVAX, et les iMAG communiquent les uns avec les autres pour effectuer des tâches. SECTra_w communique avec PIVAX pour demander des minidictionnaires, et inversement PIVAX communique avec SECTra_w pour extraire des unités lexicales à partir des corpus.
Les iMAG communiquent avec SECTra_w pour demander des traductions, soit à partir de MT, soit à partir de systèmes de TA, et inversement SECTra_w communique avec les iMAG pour demander des segments source, des fichiers squelette, et des dictionnaires de hors-texte.
|
|
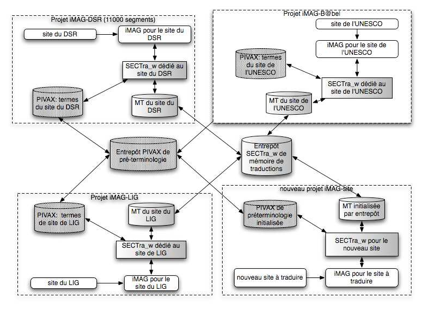
Figure 3 : Architecture par agents SECTra_w, iMAG, PIVAX (Nguyen, 2010)
I.1.2.3 Résumé des avancées et des limitations du logiciel iMAG
I.1.2.3.1 Avancées
Introduction d'une possibilité de modération. Il faut dans certains cas pouvoir éviter que des contributeurs anonymes n'améliorent pas les traductions, mais au contraire les remplacent par des textes injurieux, diffamatoires ou autres. C'est un risque non négligeable si le site élu est, par exemple, lié à des activités politiques. C'est pourquoi, à l'occasion du travail sur l'iMAG de la Métro (le "grand Grenoble"), H. T. NGUYEN a introduit une possibilité de modération, inspirée de celle de Wikipédia. En mode "modéré", un contributeur peut modifier une traduction comme il veut, et il la verra à l'écran, mais elle ne sera acceptée définitivement dans la MT qu'après avoir été validée par un modérateur ayant les droits suffisants.
Visualisation de la fiabilité supposée des segments en langue d'accès. La case à cocher « fiabilité » permet de voir, pour chaque segment, s'il est le résultat brut d'une TA, s'il a été produit par un contributeur anonyme (ou enregistré mais pas connecté), ou bien par un contributeur connecté. Cette visualisation ne modifie pas la couleur du fond, ou la couleur des fontes. On se borne à encadrer chaque segment par deux parenthèses spéciales, respectivement rouges, orange et vertes dans les trois cas ci-dessus.
Association d'un niveau de fiabilité supposée et d'un score de qualité à chaque segment traduit. Le terme "niveau de fiabilité" n'est pas très bon, mais nous n'en avons pas trouvé de meilleur. C'est en fait l'origine d'une traduction stockée dans la MT. Il est exprimé par 1 à 5 étoiles : ☆ pour une traduction mot-à-mot (pidgin), ☆☆ pour une traduction automatique, ☆☆☆ pour un humain connaissant les deux langues, ☆☆☆☆ pour un traducteur professionnel, et ☆☆☆☆☆ pour un traducteur certifié par le site Web associé à l’iMAG. Ce niveau est de même nature que les 3 couleurs des parenthèses spéciales, et simplement un peu plus précis. Pour les couleurs, on a voulu se limiter à 3, pour des raisons ergonomiques.
Le score de qualité est une note entre 0 et 20. Chaque contributeur inscrit dans SECTra_w a un score par défaut pour chaque couple de langues sur lequel il peut intervenir, par exemple 12/20 pour "moyen", ou 14/20 pour "bon". Il peut lui-même modifier ce score pour noter ce qu'il pense de la qualité d'un segment qu'il a post-édité (ou qu'un autre a post-édité, mais on le fait plus rarement). Par exemple, on mettra 9/20 si on a conscience de ne pas avoir trouvé un équivalent convenable, et 16/20 si on est sûr d'avoir produit une très bonne traduction.
Possibilité de
post-éditer directement sur la page Web. L’utilisateur peut faire de la
post-édition sur une page Web en langue cible, directement dans le
"contexte de lecture". Ses post-éditions sont présentées
immédiatement sur la page Web[13],
et le résultat est sauvegardé dans la MT associée. Beaucoup de post-éditeurs
utilisent en pratique les deux modes de post-édition. Dans le mode avancé, on
va très vite, mais on ne voit pas le contexte global de la page, ni la
présentation. Quand on revient sur la page, on voit des coquilles, des pronoms
incorrects, etc., et on les corrige directement sur la page.
Visualisation
parallèle d'une page en cible et source. Quand on utilise une iMAG, on peut post-éditer sur la page Web cible, en
visualisant en parallèle la page Web source.
I.1.2.3.2 Limitations
Le logiciel iMAG actuel présente trois groupes de défauts du point de vue fonctionnel et architectural.
· Les dialogues de l’interface de tous les composants devraient être multilingues. Pour l'instant, ils sont seulement en anglais.
· Des fonctionnalités critiques ne sont pas implémentées, ou pas comme il faudrait pour obtenir les résultats attendus.
o Gestion de la mémoire de traductions. Il faudrait éliminer la « sous-MT » associée à chaque pseudo-document.
o Contextes linguistiques. Il faudrait les prendre en compte.
o Consultations et contributions lexicales. Il faudrait intégrer une aide lexicale non seulement au niveau de l'interface de PE de SECTra, mais aussi dans la "palette iMAG".
o Visualisation de l'apport de la PE. Il faudrait pouvoir voir non seulement la page source, mais aussi la page cible en mode « trace » (TA brute initiale et vue intuitive des modifications dues à la PE).
o Mesure des temps de PE. La communication des temps de PE et des scores de qualité entre l'interface iMAG et SECTra_w n'était pas satisfaisante.
o Liaison entre les deux interfaces de PE. Il faudrait introduire une liaison directe entre un segment sur la page Web et le segment correspondant dans l'interface de SECTra_w, et dans les deux sens. Pour l'instant, on est limité à l'accès à une « page logique » de SECTra à partir d'un segment.
· Le logiciel iMAG actuel n’est toujours pas protégé contre des attaques où des robots font des requêtes qui sont autorisées pour tous les visiteurs. Cela conduit à une surcharge du système et donc à des dénis de service.
L’architecture actuelle repose essentiellement sur l’exploitation d’un seul logiciel dans lequel tout est géré, ce qui n’est pas compatible avec les besoins en modularité.
I.1.3 Travaux comparables et idées directrices pour le futur
I.1.3.1 Travaux
comparables sur la création et l'exploitation des corpus multilingues
Pour améliorer notre système, nous avons essayé de étudier systématiquement les travaux comparables pour trouver les points intéressants sur la manipulation des corpus multilingues. Nous avons trouvé 2 types de systèmes, (1) les systèmes de stockage et d’accès, et (2) les systèmes de collecte directe et d’exploitation de corpus multilingues.
I.1.3.1.1 Systèmes de stockage et d'accès (0,5 p.)
Systèmes de stockage
basé sur un service Web. Outre le stockage, ces systèmes permettent la
navigation, le téléchargement, et la visualisation des données.
Certains fournissent aussi quelques fonctions utiles, comme la recherche dans un sous-ensemble de textes ou de phrases d'une certaine catégorie, ou la production de concordances. Par exemple, le site Web OPUS[14] (Tiedemann, 2012) contient une grande quantité de corpus multilingues. L’utilisateur peut télécharger les corpus à partir des liens du site Web. Dans le Tableau 4, nous présentons les sites Web principaux permettant de partager des corpus parallèles.
Tableau 4 : Exemples de sites Web de partage de corpus parallèles
|
Nom du corpus |
Lien |
|
Europarl |
|
|
JRC-Acquis |
https://ec.europa.eu/jrc/en/language-technologies/jrc-acquis |
|
Parallel corpora at PELCRA |
|
|
UM-Corpus (Tian et al., 2014) |
|
|
The Bible (Resnik et al., 1999) |
Systèmes de plus haut niveau pour les brevets. Un système de gestion de documents de brevets est un autre type de système de gestion de corpus. Généralement, un tel système contient une série de fonctionnalités permettant de manipuler les brevets, comme la recherche, la comparaison, l'extraction, etc.
Par exemple, le système Patentscope (Pouliquen and Mazenc, 2011) permet d’accéder aux demandes internationales selon le Traité de coopération en matière de brevets (PCT[15] pour Patent Cooperation Treaty) en texte intégral, le jour même de leur publication, ainsi qu’aux documents de brevet des offices de brevets nationaux ou régionaux participants.
Systèmes plus génériques. Ce type de système est beaucoup utilisé pour gérer et partager plusieurs types de données. Par exemple, Meta-Share (Federmann et al., 2012) est utilisé pour partager des corpus. Ce type de système a but pour gérer les publications, l’ensemble des données, des fichiers multimédia, etc. Il permet en particulier d'accéder à des corpus et de les télécharger.
I.1.3.1.2 Systèmes de collecte directe et d’exploitation (0,5 p.)
Quelques systèmes contiennent des outils ou des langages de scripts utilisables pour collecter et manipuler quelques types de corpus, et en particulier des corpus multilingues (comparables ou parallèles).
Voici trois exemples, ERIM-Collecte, de notre labo, Bitextor, et PaCo2.
ERIM-Collecte : ERIM-Collecte (Fafiotte, 2004) a été construit dans le cadre du projet ERIM (Environnement Réseau pour l’Interprétariat Multimodal), visant à créer un environnement en réseau pour l’aide à la communication orale multilingue, dans lequel on peut collecter des corpus de dialogues parlés spontanés bilingues et multilingues. ERIM-Collecte permet l’enregistrement systématique des actes et données de l'interaction, pour tous les participants (deux locuteurs ou plus, un interprète ou plus). L'enregistrement est fait localement lors de la conversation. En fin de dialogue, les descripteurs et fichiers produits localement sont transmis à un serveur de collecte, où ils sont regroupés et structurés.
Bitextor : Bitextor
(Esplá-Gomis, 2009) est un outil d'extraction de bi-textes à partir de pages Web. Tout d’abord,
il télécharge les pages Web visées. Ensuite, il normalise les fichiers
téléchargés. Enfin, il compare les fichiers en utilisant divers critères pour
extraire les phrases parallèles, que nous appellerons plus précisément "bisegments".
Dans la terminologie actuelle, un "corpus parallèle" est une
collection de bisegments, et bien plus rarement une collection de vrais
documents multilingues alignés au niveau des segments (phrases et titres).
PaCo2 : PaCo2 (Parallel Corpora Collector) (San Vicente and Manterola, 2012) est un outil de collecte de corpus
parallèles à partir du Web. Il met en œuvre les techniques les plus modernes (à
l'état de l'art) permettant de trouver des bi-textes dans un domaine Web qui en
contient. De plus, il peut trouver de tels domaines Web automatiquement.
I.1.3.1.3 Systèmes d'extraction indirecte (0,25 p.)
Les corpus
comparables sont considérés comme des ressources importantes pour collecter des
corpus parallèles, surtout quand on n'en trouve pas directement. Ici, le terme
"corpus comparable" dénote une collection de "vrais"
documents, par exemple des pages Web, ou des documents en Word ou en pdf, qui sont de
typologies comparables (par exemple, des articles de Wikipedia sur le même sujet, ou des recettes de cuisine,
ou de la documentation technique de produits similaires).
Plusieurs méthodes ont été proposées pour extraire (ou construire) un corpus parallèle à partir de corpus comparables : elles utilisent les notions de documents comparables (Resnik and Smith, 2003) (Smith et al., 2010), de phrases comparables (Zhao and Vogel, 2002), (Munteanu and Marcu, 2005), et des ressources comme des bisegments ou des dictionnaires bilingues (Munteanu and Marcu, 2006), (Cettolo et al., 2010). Dans le cadre de sa thèse, Thi Ngoc Diep DO (Do, 2011) a aussi proposé 3 approches d’extraction de textes parallèles à partir de documents comparables.
I.1.3.2 Travaux comparables sur la post-édition de TA
I.1.3.2.1 Introduction
« Postediting/post-editing (PE) is
by far most commonly referred to as a task related to Machine Translation (MT)
and has been previously defined as the "term used for the correction of
machine translation output by human linguists/editors." Another good
summary statement indicates that "post-editing entails correction of a
pre-translated text rather than translation ‘from scratch’." In basic
terms, the task of the post-editor is to edit, modify and/or correct
pre-translated text that has been produced by a machine translation system from
a source language into (a) target language(s). »
--- ALLEN,
Jeffrey. 2003 (Allen, 2003)
Les premières études sur la post-édition sont apparues dans les années 80, liées aux outils associés aux systèmes de TA, puis aux outils associés aux MT (Senez, 1998). Les premières parurent au Japon, et seulement en japonais.
Dès les années 1985, il y avait une trentaine de systèmes de TA commerciaux au Japon, utilisables sur miniordinateur (AS-Transac de Toshiba) ou poste de travail, ou PC (comme Duet-2 de Sharp), et cette activité était enseignée et pratiquée par des professionnels de la traduction. Ailleurs, les systèmes et leur usage étaient en retard d'un quinzaine d'années à cause de l'arrêt des financements provoqué par le rapport ALPAC (12/1966—1/1967). Le centre de recherche en TA de CMU ne fut ainsi créé qu'en 1985. C'est seulement en 1999 que, pour élaborer des directives appropriées et de la formation, les membres de l'Association for Machine Translation in the Americas (AMTA) et de l'European Association for Machine Translation (EAMT) créèrent un groupe d'intérêt pour la post-édition, le Post-editing Interest Group, ou Post-editing SIG (Allen, 1999).
Depuis les années 1990, avec le développement des systèmes de TA, la post-édition de traductions automatiques s'est développée dans le monde occidental, mais nettement plus lentement qu'au Japon. En fait, les gros bureaux de traducteurs professionnels ont longtemps préféré utiliser des systèmes à mémoires de traductions comme Translation Manager (TM2™) d'IBM, Trados, Transit (de Star), ou Déjà Vu, même s'ils étaient couplés à des systèmes de TA, comme LMT pour TM2™. Selon (Boitet, 1996), la raison en est que les dictionnaires "main gauche" intégrés à ces systèmes et constamment mis à jour par les traducteurs suivaient l'évolution terminologique, alors que ceux des systèmes de TA évoluaient beaucoup plus lentement, de sorte que post-éditer des sorties de TA devenait plus long qu'utiliser les suggestions d'un système à mémoire de traductions (MT). Depuis que Systran a été mis sur minitel (en 1984), puis en service gratuit sur Internet (en 1994), ce sont les traducteurs indépendants qui se sont d'abord mis à utiliser des résultats de TA, en post-édition s'ils étaient assez bons, et comme "dictionnaire en contexte" sinon. Il y a quelques exceptions, dans des situations où les utilisateurs et les développeurs des systèmes de TA étaient en synergie. Ce fut le cas à la PAHO (Pan American Health Organization, Washington, et OMS, Genève, avec les systèmes SpanAm, EngSpan, puis PAHOMTS (Vasconcellos and León, 1985)), et aussi à Taipeh (Hsu and Su, 1995).
L'autre cas où la post-édition de résultats de TA a depuis très longtemps été très appréciée, et utilisée par des traducteurs professionnels, est celui où le système de TA est spécialisé à un sous-langage précis. C'est le cas du système METEO au Canada (1981-2001)[16], dédié aux bulletins[17] météorologiques, du système ALTFLASH de traduction des "brèves" du Nikkei (en mars 1998) (Uchino et al., 2001), et surtout des "accélérateurs de traduction" (Pouliquen et al., 2013) construits par B. POULIQUEN à partir de mémoires de traductions contenant les bisegments produits par des traducteurs professionnels pendant plusieurs années (11 ans pour les systèmes construits avec Moses pour l'ONU à Genève).
Un nouvel usage de la post-édition est apparu depuis quelques années. Il s'agit non pas d'améliorer les traductions automatiques avant qu'elles ne soient "consommées", mais d'en post-éditer une partie pour augmenter et améliorer la MT à partir de laquelle un système de TA est construit. Ce sont donc des aides au développement et à l'amélioration de systèmes.
Nous présentons maintenant les systèmes destinés uniquement à aider les traducteurs, puis les systèmes destinés à améliorer des systèmes de TA.
I.1.3.2.2 Systèmes destinés uniquement à aider les traducteurs
Libellex. Libellex[18] est l’un des deux produits-phare de la société Lingua et Machina (L&M). Il s’agit d’une plate-forme de traitement multilingue d'aide à la traduction qui repose sur un système de gestion de mémoires de traductions. Il vise à constituer une mémoire collective d’entreprise pour tout ce qui concerne la communication multilingue. Libellex intègre un module de traitement de la terminologie (import/export à partir de ressources du client, extraction de terminologie, gestion de terminologie, etc.), et un module pour créer et utiliser des systèmes de TA de type Moses (alignement de corpus, entraînement, appel de systèmes de TA). Il peut être utilisé en mode SaaS[19] ou installé en mode licence sur des postes de travail informatiques.
SDL Trados Studio. La société Trados commercialise un outil de THAM appelé SDL Trados Studio, qui a environ 200 K utilisateurs (plus de 200 K licences du produit[20]). Elle fournit des solutions innovantes en matière de logiciels de traduction à toute la chaîne logistique de traduction, y compris aux traducteurs indépendants, aux prestataires de services linguistiques, aux services internes de traduction et aux établissements universitaires. Cet outil se compose d’un gestionnaire de terminologie (SDL MultiTerm 2015), et d'un module d’alignement qui permet d'initialiser la MT utilisée à partir de documents déjà traduits.
I.1.3.2.3 Systèmes destinés à améliorer des systèmes de TA
MateCat. MateCat (Schwenk et al., 2015) est un système visant à
améliorer l'intégration d'un système de TA et de la traduction humaine (TH). L'objectif est d'améliorer la productivité des
traducteurs professionnels et leur expérience du travail avec la TA. MateCat propose une prétraduction par TA pour chaque phrase.
Un système de TA basé sur Moses est intégré dans MateCat. Pour obtenir une bonne qualité de traduction et un
gain de productivité, le système de TA est adapté au domaine (par exemple, la
finance). MateCat permet d’améliorer le système de TA
en utilisant les résultats de post-édition, et il a intégré « Online model
adaptation (Bertoldi et al., 2014) » de Moses pour
améliorer dynamiquement le système de TA.
CASMACAT. CASMACAT (Alabau et al., 2013) (Cognitive Analysis and Statistical Methods for Advanced Computer Aided Translation) est un système pour la traduction assistée par ordinateur et l'étude scientifique de la traduction humaine. Pour l’amélioration des systèmes de TA (Moses), CASMACAT propose trois méthodes efficaces en ligne pour mettre à jour les systèmes de TA : (1) Il infère de nouvelles règles à partir des segments post-édités, et les ajoute au modèle de traduction ; (2) il utilise les segments post-édité pour mettre à jour le modèle de langue ; et (3) il met à jour les paramètres discriminants de TA dans une étape MIRA (Chiang, 2012) et (Hasler et al., 2011).
I.1.3.3 Idées directrices pour faire évoluer SECTra_w/iMAG
I.1.3.3.1 Rendre
SECTra configurable au niveau des corpus
Un SECTra[21] configurable au niveau des corpus devrait permettre non seulement de définir le descripteur du corpus (le nom du corpus, les langues source/cible, le domaine, la taille, l’auteur, etc.), mais aussi de présenter la relation entre le corpus et les fichiers compagnons, de choisir le dictionnaire, de manipuler les corpus (fusion, séparation, comparaison, filtrage, etc.), le format d’import/export, le codage, etc.
I.1.3.3.2 Trouver une modélisation convenable
Nous souhaitons trouver une modélisation convenable pour les corpus multilingues, éventuellement complexes. Nous nous sommes inspiré de l’idée de structure de dictionnaire (les définitions sont présentées dans la thèse de M. MANGEOT (Mangeot, 2010)). Nous souhaitons construire une nouvelle version de SECTra sur des corpus de traductions aussi variés et aussi gros que possible, comme JR-acquis, EuroParl, Hansard, EOLSS augmenté par l'UNU-UNDL, ERIM, et surtout le corpus de brevets CLEF-IP (60 Go). Faire cela est nécessaire pour arriver à développer une méthode innovante et pertinente de modélisation des corpus multilingues alignés, et la partie du futur langage de programmation du système SECTra qui permettra de décrire le type de chaque nouveau corpus (macrostructure, microstructure, comme pour les bases lexicales, et peut-être aussi "mésostructure" pour définir l'organisation des sous-documents, des fichiers satellites, et des documents ou fichiers compagnons).
I.1.3.3.3 Rendre SECTra programmable
Parmi les fonctions de SECTra_w qu’on souhaite rendre programmables, il y a la synchronisation des données (en ligne ou hors ligne), l’import, l’export, la recherche, la sélection des données, et l'apprentissage incrémental de systèmes de TA à la Moses.
Il faudrait que SECTra fournisse un support à la programmation, permettant de gérer et de traiter les corpus, et aussi des opérations motivées par l'utilisation dans des campagnes d'évaluation (par exemple, programmer certaines "mesures d'évaluation", comme BLEU, NIST ou TER), ou des opérations motivées par l'utilisation dans des projets de post-édition (par exemple, appel à un ou plusieurs systèmes de TA).
I.2 Améliorations de SECTra_w dans le cadre du projet Traouiero
I.2.1 Extension de fonctions existantes
Dans le cadre du projet Traouiéro, nous avons travaillé sur l’amélioration de SECTra_w. Tout d’abord, nous avons amélioré la fonction d’appel de systèmes de TA. Elle permet de faire exécuter ou réexécuter la traduction automatique, par tel ou tel système, sur tout un corpus ou sur une sélection de documents.
Ensuite, nous avons refait
la conception de la communication entre Tradoh et SECTra_w, et réalisé la procédure d’appel des systèmes de TA
via Tradoh. Enfin, nous avons participé à l'introduction
de la possibilité pou un utilisateur d’ajouter à Tradoh
des plugins permettant d'augmenter la collection des systèmes de TA appelables,
et nous avons réalisé et intégré plusieurs plugins, dont un permettant
d'appeler n'importe quel système Moses.
I.2.1.1 Appel de systèmes de TA sur un corpus ou sur une sélection de documents
Pour ajouter de nouvelles traductions automatiques dans SECTra_w, nous lui avons ajouté une nouvelle fonctionnalité. Dans la Figure 4, nous montrons comment choisir la langue cible et le système de TA dans l’interface de Translate Corpus. Une traduction via une langue pivot est aussi possible (cocher l’option Pivot langage).
|
|
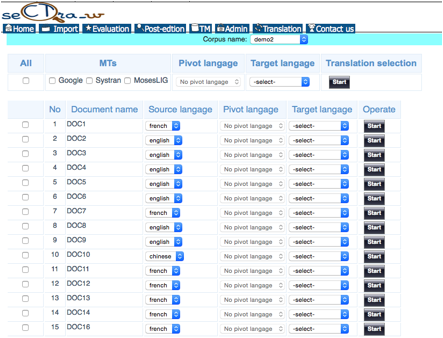
Figure 4 : Interface de « Translate Corpus »
I.2.1.2 Extension : utilisation de Tradoh et passage éventuel par une langue intermédiaire
Dans la conception de SECTra_w, Tradoh est un important composant pour la gestion des appels à des systèmes de TA. Mais, en fait, il n’y avait pas en 2011 de vraie communication entre SECTra_w et Tradoh. Dans le cadre du projet Traouiero, nous avons reconstruit la fonctionnalité d’appel de systèmes de TA. Nous avons voulu pouvoir traiter les mêmes paires de langues avec GT et Systran, par défauts utilisés avec la même priorité pour produire les prétraductions.
Pour beaucoup de paires, GT passe en fait par un « pivot textuel » anglais. Mais d'autres systèmes, comme Systran, ne le font pas, car cela dégrade considérablement la qualité (linguistique et d'usage). Nous avons ajouté la possibilité pour un utilisateur de demander (via Tradoh) une traduction "double" passant par un texte dans une langue « pivot » qui peut être l'anglais ou toute autre langue (par exemple, le français pour faire de l'italien-espagnol). Cette possibilité est illustrée dans la Figure 4.
Dans la Figure 5, on voit une interface de Tradoh permettant de définir la langue pivot. Par exemple, le serveur Systran (V7) gracieusement prêté par Systran ne supporte pas la traduction du français vers le chinois. On prend l’anglais comme langue pivot pour obtenir la traduction en chinois (français→anglais, anglais→chinois).
|
|
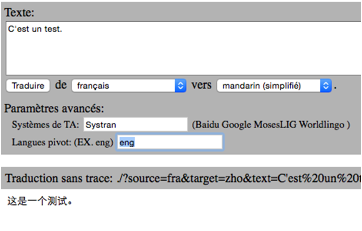
Figure 5 : Interface de Tradoh
I.2.1.3 Ajout par l'utilisateur de systèmes de TA utilisables pour les corpus associés à une MT donnée
Depuis 2004, de plus en plus d'environnements de création de systèmes de TA statistique en source ouvert (comme Apertium (Forcada et al., 2011), Moses (Koehn et al., 2007), Joshua (Ganitkevitch et al., 2012), etc.) ont été développés par des laboratoires ou des associations. Les utilisateurs utilisent ces boîtes à outils pour entraîner leurs systèmes de TA sur leurs corpus parallèles.
Pour mettre en œuvre un système de TA qu'il a créé, un utilisateur peut utiliser le plugin de Tradoh que nous avons créé pour appeler des systèmes de TA de type Moses. Nous avons aussi créé un plugin permettant d'appeler les systèmes de TA de type Ariane-G5 (Guilbaud, 1999) disponibles sur la plate-forme Héloïse (Berment and Boitet, 2012).
Pour l’instant, nous avons utilisé notre plugin Tradoh-Moses pour activer dans SECTra_w le système de TA anglais→hindi Moses-CFILT-en_hi de l'IITB (Bombay) et nos systèmes MosesLIG français↔chinois.
Dans la Figure 4, nous montrons comment nous avons ajouté MosesLIG pour appeler nos systèmes de TA français↔chinois. Quand l’utilisateur veut traduire un document ou un corpus du français vers le chinois (ou l’inverse), il coche la case MosesLIG, et le système de TA français↔chinois sera appelé.
I.2.2 Aspects de génie logiciel
I.2.2.1 Sélections paramétrables
Dans le cadre du projet Traouiero, nous avons travaillé sur la "programmabilité" de SECTra_w. Nous ainsi introduit et implémenté les sélections paramétrables. Le but est, par exemple, de sélectionner une « bonne » partie d’une MT et de l’exporter pour construire un système Moses ou pour faire de l’amélioration incrémentale (voir 0).
Nous avons ajouté la fonction « export » dans SECTra_w pour exporter les segments post-édités. Nous avons implémenté un type de prédicat de sélection assez fréquent, paramétrable dans l'interface présentée dans la Figure 6.
|
|
Figure 6 : Options de la fonction "export"
Par exemple, on peut utiliser l'expression de sélection suivante :
($niveau=3 et $score>=14) ou ($niveau=4 et $score>=12) ou
($niveau=5 et $score>=11)
|
|
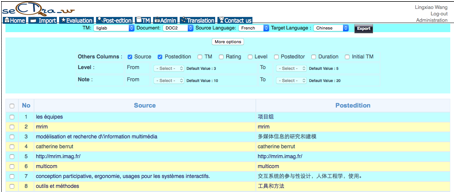
Figure 7 : Interface de sélection paramétrable dans SECTra_w
Pour aller plus loin, il faut définir ici un « petit morceau de langage » permettant de programmer n’importe quelle expression de sélection. Pour cela, nous avons enrichi l'API de SECTra_w pour pouvoir maintenir et publier des « variables SECTra » comme $niveau, $score, $source, $MT, $posteditor, $length, $detected_language, $date(s), etc. (Figure 7).
I.2.2.2 Clarification du traitement des "occurrences" des segments
Une page Web, qui évolue dans le temps, est représentée dans SECTra_w par un « pseudo-document » qui contient des références à tous les « segments » déjà vus dans cette page, ainsi que le « squelette » de l’instance courante de la page.
Le problème vient surtout du fait qu’un segment peut avoir été trouvé auparavant dans une autre page Web, correspondant à un autre pseudo-document, et que, si on ne le trouve pas dans la MT du pseudo-document courant, il faut (on croit qu’il faut) aller le chercher dans les MT des autres pseudo-documents. Cela conduit à N recherches s’il y a N pseudo-documents et si le segment est nouveau… Or on devrait trouver la réponse par une seule recherche dans la MT globale.
À cause du problème algorithmique lié à ce mauvais choix de structure de données, il y a en fait une petite MT par pseudo-document (cette MT contient les segment source, les traductions obtenues par TA, et les post-éditions du document), et pas seulement un ensemble ou une liste des segments déjà vus.
Nous avons proposé une nouvelle structure de MT partagée pour résoudre ce problème, sans détruire la structure existant de SECTra_w. Cette MT contient les segments validés par les modérateurs. Quand un nouveau segment arrive, SECTra_w cherche d’abord la traduction dans la MT du pseudo-document en cours. S’il n’en trouve pas, il le cherche dans la MT partagée. S’il le trouve, la traduction sera affichée sur la page Web traduite, sinon, il appellera le système de TA.
I.2.2.3 Analyse
de fonctions dans XWiki, améliorant la modularité
SECTra_w a été construit sur XWiki. Sa programmation utilise donc les langages associés (Groovy[22], Velocity[23], Javascript, html). La version de XWiki utilisée par SECTra_w est la version 1.3, alors que la version actuelle est la 7.2. Elle nécessite l’installation de Tomcat 5 dont on ne trouve plus d’installeur. Il a fallu procéder à l’installation complète « à la main » de Tomcat 5. Des notes résument les manipulations effectuées, avec quelques explications, pour pouvoir les comprendre et les reproduire ou les adapter aux situations à venir.
L’installation de la version de XWiki sur laquelle fonctionne le service a donné aussi lieu à la rédaction d’une note détaillée, en particulier pour bien mémoriser ce qui doit être fait pour définir correctement les connecteurs entre le serveur Tomcat et les services déployés par XWiki. Comme l'utilisation de XWiki nous paraît en fait peu adaptée à l'implémentation de logiciels comme SECTra_w et iMAG, même si on passait à la version 7.2, et comme un tel passage serait très lourd, nous avons préféré (et spécifié lors du projet Traouiero) nous orienter vers une réimplémentation plus modulaire, et indépendante de XWiki.
Pour faire évoluer SECTra_w, nous avons donc commencé à travailler sur l'augmentation de sa modularité. Tout d’abord, nous avons fait une liste pour le code Groovy qui est dans les pages XWiki (car ce code est sauvé dans des pages Web), puis nous avons analysé les fonctions contenues dans ce code. Enfin, nous avons classé les fonctions.
I.2.3 Travail de spécification(1,5 p.)
Dans le cadre du projet Traouiero, nous avons fait une spécification pour améliorer la structure de la base de données de SECTra_w. La nouvelle base de données de SECTra_w est centrée sur le métier « gérer des corpus multilingues de textes multilingues alignés ». Les 5 entités principales identifiées et implémentées dans le modèle conceptuel sont listées ci-dessous et on leur a rajouté 2 entités (pseudodocument et segment multilingualisé multilingue), qui manquaient dans la version courante de SECTra_w, ainsi que des précisions sur la dernière entité (Traduction).
Si l’on veut
avoir une représentation en « réseau corporal », comme on le fait
pour des « réseaux lexicaux », il faudra donc spécialiser la notion
de « segment tout court », inutilisable telle quelle, en
« segment source » et « segment cible » ou « traduction
segmentale ».
On pourra alors
considérer qu’un segment source est un nœud d’un graphe, relié par une
relation (directe ou indirecte) de traduction à des segments cibles, et que le sous-graphe connexe obtenu forme
exactement un segment multilingualisé contextualisé. Du point de vue des traducteurs
et des représentations « à la TMX », il faut
cependant considérer un segment multilingualisé contextualisé comme un objet identifié comme tel, à structure complexe, et
muni d’un historique propre.
La structure logique de la nouvelle
base de données de SECTra_w illustrée dans la Figure 8
ne prend en considération l’utilisateur que dans la table provenant de l’association
plusieurs à plusieurs entre les segments et leurs contextes. La stratégie de
programmation choisie pour développer SECTra_w prévoit des modifications, en
particulier en ce qui concerne les colonnes de ses tables[24].
|
|
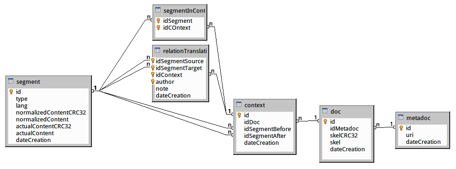
Figure 8 : Structure logique d'une base de données
de corpus multilingues
I.3 Améliorations des iMAG dans le cadre du projet Traouiero
I.3.1 Paramétrisation
I.3.1.1 Réalisation d'un configurateur d'iMAG par C. P. Huynh
Dans le cadre de la thèse de C.P. Huynh, on a construit SECTra_w pour permettre de mettre en œuvre des paramétrages « externes » au niveau du paramétrage et de la configuration par les non-informaticiens :
· Optimisation de l’interface d’évaluation subjective selon les critères d’évaluation d’une campagne, et le réglage de l’interface (nombre de segments, de colonnes, de langues, etc.).
· Filtrage de données post-éditées selon la date, l’auteur, la qualité (niveau traductionnel, note de qualité), etc.
· Recherche et remplacement interactif dans une sélection arbitraire (ensemble de segments, ensemble de documents).
· Récupération de données à partir de MT en fonction de divers paramètres.
· Lancement automatique des appels de systèmes extérieurs (TRADOH++, PIVAX, etc.).
Au niveau du paramétrage et la programmation par des
contributeurs informaticiens, SECTra_w permet d’écrire
facilement des scripts pour le traitement de données, tels que des scripts pour
l’import et l’export de corpus. Par exemple, A. Falaise a écrit un script permettant l’appel depuis
l’extérieur de la fonction d’import de SECTra_w pour
importer un corpus du projet Survitra et un autre du
projet OMNIA.
Cependant, nous n’avons pas encore
développé les langages (langage de conditions booléennes, langage de flots de
travail, langage narratif) dans la version actuelle de SECTra_w.
Nous prévoyons de les intégrer dans la prochaine version.
I.3.1.2 Améliorations prévues mais pas encore réalisées
Il faudrait améliorer le logiciel iMAG pour que, en fonction des informations sur le site S et des paramètres de l'accès multilingue à S, il appelle l'iMAG-S avec les paramètres adéquats. Ces paramètres concernent surtout les langues (lesquelles sont post-éditables, modérables, post-éditées, modérées, ou exclues...) et les systèmes de TA (lesquels sont souhaités, avec quels paramètres, avec quelles préférences entre systèmes pour chaque couple de langues, avec quels chemins traductionnels pour chaque couple, etc.).
Sur l’interface, le paramétrage d’une iMAG doit pouvoir permettre à l’administrateur d’un site Web « élu » de personnaliser la présentation (message de bienvenue, feuille de style), et de choisir les interacteurs qu’il veut proposer à ses visiteurs, selon leur rôle. Par exemple, la feuille de style pourrait permettre de générer une présentation « à la Neon », avec le texte source écrit au-dessus du texte cible, ligne par ligne, et la palette pourrait contenir les noms des contributeurs à chaque segment, et/ou son origine (niveau de ☆ à ☆☆☆☆☆), et/ou sa note (de 0 à 20), etc.
I.3.2 Travail de spécification
I.3.2.1 iMAG-Relais
Pour mieux gérer les rôles des utilisateurs entre composants différents, Valérie Bellynck a proposé un nouveau composant dit « Relais », qui aura pour rôle d’assurer l’identification vis-à-vis des différents services, en octroyant aux utilisateurs, de façon transparente, les droits suffisants pour assumer les tâches associées à leur rôle dans chacun d’eux, en fonction des paramétrages choisis par l’administrateur référent d’une passerelle iMAG, ou par ses administrateurs délégués. Nous reprenons ici une partie de son texte.
Lorsque le problème du transfert des
droits a été identifié, le rôle du relais devait être de relayer les droits
entre les différents services utilisés dans une architecture multiservices dans
lesquels les utilisateurs peuvent avoir des rôles et des droits différents
selon le service exploité. Il s’agit de transmettre ces droits sans introduire
de faille de sécurité dans les services exploités.
Non seulement les types des rôles
peuvent être différents (quelqu’un peut être client dans un site commercial de
souscription d’offres de services, et modérateur dans un site contributif
visant à construire collaborativement de la connaissance), mais les termes
utilisés pour identifier les rôles peuvent être identiques tout en ne
correspondant pas à des accès identiques aux mêmes fonctions.
I.3.2.2 Tableau blanc
Dans l'implémentation actuelle des iMAG, la plupart des composants sont des services Web, utilisés comme des serveurs. On constate deux inconvénients : (1) ces services ne sont pas autonomes (il faut les relancer à la main ou indirectement par des scripts), et (2) on n'a pas de vision sur ce qui se passe dans le système global, et qui peut être compliqué. En effet,
· il y a des appels mutuels. Par exemple, SECTra_w appelle PIVAX en lui envoyant des segments, pour en recevoir des minidictionnaires en HTML, et PIVAX peut appeler SECTra_w pour en obtenir la prétraduction et la post-édition des exemples d'usage contenus dans des articles de dictionnaires.
· il y a des exécutions de tâches en boucle infinie, qui sont pour l'instant limitées à des files d'attente de tâches considérées comme élémentaires[25]. Par exemple, un corpus peut être en train d'être traduit de français en allemand, un document EOLSS peut être en train d'être déconverti depuis UNL[26] vers le français ou le russe (par appel à des serveurs de TA, via TRADOH++), et plusieurs documents et mémoires de traductions peuvent être en cours de post-édition ou d'évaluation humaine.
Donc le but de cette tâche est de :
· construire, comme cela a déjà été envisagé dans le projet (ANR) OMNIA, un dispositif de contrôle du système complet par tableau blanc et chef d'orchestre[27] ;
· organiser les modules principaux comme des agents à gros grain, capables d'initiative, et en particulier capables de se relancer seuls, et de déterminer eux-mêmes ce qu'ils ont à faire en faisant appel au tableau blanc.
I.3.2.3 Architecture en agents à gros grains
Lorsque le système à modéliser est trop complexe, une analyse globale révèle rapidement ses limites. Il est souvent plus simple et rapide de chercher des solutions à des problèmes plus locaux, selon le principe classique en informatique du « diviser pour régner ». Par exemple, pour réguler le trafic aérien, de trop nombreux paramètres et contraintes influent sur le résultat de l’ensemble pour qu’une approche globale permette une résolution fiable.
En revanche, des solutions locales aident à résoudre élégamment et efficacement de telles difficultés. Les résultats obtenus sont souvent acceptables, bien qu’il soit au mieux difficile et au pire impossible de prouver cela théoriquement. L’approche multi-agents permet d’obtenir plus simplement des résultats sur des problèmes complexes, en contournant les difficultés qu’auraient des algorithmes globaux pour les gérer.
I.3.2.4 Files d’attente
Dans les cas où plusieurs clients (SECTra_w/iMAG, Tradoh, PIVAX, etc.) veulent demander un traitement particulier, la communication par messages est souvent intéressante. En effet, elle permet de découpler les demandes des clients (comme l’appel à des systèmes de TA), et les traitements par les serveurs. Dans certains cas, les traitements à effectuer sont plus importants que le simple calcul d’une page. Il est alors beaucoup plus intéressant de passer par une liste de tâches partagées par les clients et les serveurs.
L’idée d’utiliser un système général de gestion de files
d’attente sur le Web n’a finalement pas pu être réalisée lois du projet Traouiro, faite de temps. Nous l’avons reprise, dans le cadre
de cette thèse et de celle de Y. ZHANG. Nous en parlons plus en détaille vers
la fin de ce mémoire (Voir IX.2). Disons seulement ici que nous utilisons ActiveMQ[28]
de la fondation Apache.