Chapitre II Travail sur des aspects plus conceptuels et définition de nouvelles fonctionnalités
Résumé
Nous présentons dans ce chapitre quelques réflexions sur la modélisation des corpus de traductions, dont la structure est bien plus complexe que celle des "corpus parallèles" simples (comme le BTEC) utilisés en TA statique pour l'apprentissage, et qui sont en fait des MT. Le but poursuivi est, à terme, de séparer les concepts de MT et de corpus. À partir de cette analyse et des travaux plus pratiques décrits plus haut, nous avons aussi travaillé sur la conception de nouvelles fonctionnalités.
II.1 Modélisation de corpus de traductions variés
II.1.1 Variété des corpus de traductions et esquisse d'une méthode de formalisation
Les notions de corpus et de corpus de traductions ont été définies plus haut (Voir II.1.1.2.2). Dans un corpus de traduction, si l'on peut faire correspondre chaque unité du texte en langue source (l1) avec chaque unité de texte en langue cible (l2) au niveau des paragraphes, phrases ou mots, ce corpus de traduction est considéré comme un corpus parallèle.
On a aussi introduit plus haut la notion de corpus comparable (Déjean and Gaussier, 2002). Deux corpus comparables, dans deux langues l1 et l2, "parlent de la même chose", mais ne sont pas des corpus de traductions. Au mieux, on peut y trouver des phrases en relation de traduction, et déterminer le sens de traduction. Comme l'a montré E. DELPECH dans sa thèse (Delpech, 2013), l'espoir selon lequel on pourrait les utiliser pour trouver efficacement de la terminologie bilingue a été largement déçu. C'est pourquoi nous ne nous intéressons qu'aux corpus de traductions.
II.1.1.1 Variété des corpus de traductions
La première chose à prendre en compte si l'on veut traiter les corpus de traductions est leur grande variété, tant au niveau des contenus que des formats, des structures et des usages.
II.1.1.1.1 Variété des contenus
Texte. Un corpus écrit est un corpus de textes, s’il contient essentiellement des textes. Il peut être constitué de documents différents (tableau, extraits de textes, etc.). Il peut être présenté comme un livre, une page Web, ou un document (en Word, Ods, LaTex, InterLeaf, etc.).
Pour chaque document source, les textes et les traductions des segments peuvent être sauvegardés dans des fichiers parallèles séparés, un par langue, ou bien à l'intérieur d'un même fichier, la représentation de chaque segment contenant alors le texte source et sa ou ses traductions. Les corpus BTEC, EuroParl, JR-acquis, MultiUN sont formés de fichiers parallèles, alors que le corpus de brevets CLEF-IP est formé de fichiers multilingues au niveau de chaque segment.
Parole. Un corpus de parole est un corpus constitué d'enregistrements de données orales, et éventuellement de leurs transcriptions, qui peuvent être considérées comme des annotations. À la différence de l'écrit qui n'utilise qu'un seul support, l’oral associe le plus souvent la parole enregistrée à une représentation écrite et codée (transcriptions, traductions, annotations).
Un corpus de dialogues bilingues interprétés comme le corpus ERIM contient non seulement les tours de parole des participants et leurs traductions (orales) produites par un interprète, mais aussi des tours de parole monolingues, qui forment des sous-dialogues de clarification entre l'interprète et un participant. Un système comme SECTra doit permettre de "rejouer" ce genre de corpus, et de créer les transcriptions écrites des segments. Dans SECTra_w, cette possibilité existe, à un niveau très « rustique », et il est possible de "déléguer" cette activité à des environnements plus adaptés (par exemple, contenant des reconnaisseurs de parole et des aligneurs texte-signal).
Visuel. Un corpus visuel
est un corpus contenant des vidéos ou images, et ce type de corpus peut contenir les textes pour compléter, décrire,
ou présenter les objets. Un film en
vidéo contient d’ailleurs la plupart du temps, sur une ou plusieurs pistes, des
sous-titres en plusieurs langues.
II.1.1.1.2 Variété des formats
À cause de la variété des usages, il existe plusieurs formats de corpus. Le format le plus utilisé est le texte brut (.txt). Pour un corpus monolingue, les textes sont sauvegardés dans un ou plusieurs fichiers .txt monolingues.
Pour un corpus bilingue/multilingue, ce format manque de balises indiquant les relations entre les phrases, et leurs langues. Donc, d'habitude, les phrases sont sauvegardées dans des fichiers séparés parallèles, un par langue. Les corpus de traductions au format .txt sont très utilisés pour l’entraînement de systèmes de TA comme Moses. Le texte source et le texte cible sont alignés (un paragraphe par segment), et sauvegardés dans N+1 fichiers s’il y a N langages cibles.
L'autre type de format le plus utilisé est « le format XML », ou plus exactement des instances de XML, comme TMX[1], TEI[2], DocBook[3], NITF[4], etc., correspondant à des DTD ou à des schémas XML définis par les professionnels du traitement des documents, de la traduction, et de la localisation.
Dans le cas d'un corpus de dialogues oraux, les enregistrements sonores sont sauvegardés dans des fichiers de format audio comme .wav, .mp3, .flac, etc., et chaque tour de parole est représenté par un fichier XML contenant les métadonnées associées, parmi lesquelles l'url du fichier audio.
De même, un corpus "visuel", dont les documents sont des vidéos ou des textes contenant des vidéos, contient les vidéos dans des fichiers .avi, .mkv, .mp4, etc, et des images dans des fichiers .svg, .jpeg, .png, etc. Dans un film en vidéo, un sous-titre constituant un segments et ses traductions peut être considéré comme d’un segment multilingualisé.
II.1.1.1.3 Variété des structures
Structure simple. La structure la plus simple est celle où un document est une suite de segments, en format texte, avec uniquement un identificateur par segments par segment. Les traductions dans N langues sont alors contenues dans N fichiers de même structure.
Corpus avec annotations
dans des fichiers compagnons. Dans ce type de structure, chaque fichier
(source ou traduction) peut avoir un ou plusieurs fichiers
« compagnons » contenant des annotations des « externes ».
Cette structure peut conserver le corpus original, et ajouter l’information
pour la description du corpus. Par exemple, le corpus ERIM
contient dialogues bilingues oraux interprétés. Les dialogues sont sauvegardés dans
les fichiers .wav, et chaque fichier .wav est accompagné par un fichier .xml qui décrit le contenu du
fichier .wav.
Corpus avec des annotations internes. Les mots et/ou les segments sont étiquetés par des balises XML, ou par des chaines spéciales (ex : Nous_Pr1pl, avions_VbIndImp1pl, etc.). Les étiquettes peuvent fournir des informations de divers ordres, comme catégories syntaxiques, lemmes (forme canonique du mot fléchi), âge et sexe du locuteur, niveau d'études, etc.
Corpus arboré. Il s'agit de corpus parsés, contenant des informations sur la structure des phrases (corpus EOLSS, par exemple, voir II.1.3.3).
II.1.1.1.4
Différents usages
Les corpus de traductions différents aussi selon ce qui on veut en faire.
Corpus de traductions
pour la TA
· Les corpus d’entraînement sont utilisés pour entraîner un système de TA Moses (EuroParl, MultiUN, etc).
· Les corpus de développement sont utilisés pour modifier des poids dans l’étape de réglage (Tuning) en TA statique
· Les corpus de test sont utilisés pour évaluer les systèmes de TA et calculer des scores comme BLEU, NIST.
· D’autres corpus sont utilisés pour l’alignement, l’extraction de terminologie bilingue, etc.
Corpus de traductions pour apprenants. Un tel corpus contient des productions écrites et/ou orales faites par des apprenants d'une langue seconde servent à décrire l'interlangue et donc les difficultés des apprenants servent aussi à élaborer une typologie des erreurs pour l'utilisation dans un système de vérification grammaticale, ou production d'éditions bilingues annotées d'ouvrages littéraires.
II.1.1.2 Exemples
II.1.1.2.1 Corpus d'évaluation du projet TRANSAT
En 2005-2007, le GETA a participé au projet TRANSAT dans le cadre d’un contrat avec France Telecom R&D. À cette occasion, C. P. HUYNH a créé la première version de SECTra_w, et nous l'avons utilisée comme support d’une campagne d’évaluation ayant pour but d’évaluer l’utilité des systèmes de traduction automatique commerciaux dans le domaine de la traduction de la parole.
Dans cette campagne, nous avons utilisé des données issues du corpus BTEC pour construire deux corpus sur deux types de tâches relatives au tourisme, ainsi que des dialogues collectés par l’équipe Multicom du CLIPS (Blanchon et al., 1999). Ce premier corpus source (anglais) a été extrait du corpus BTEC, et contenait un ensemble de 2224 tours de parole tous différents, en accordant une priorité aux tours de parole relatifs aux problèmes de santé. Le second corpus source (anglais), qui a aussi été extrait du corpus BTEC, était constitué de 2000 tours de parole dans le domaine de la restauration.
Les traductions candidates étaient les traductions de Reverso Translator 10 et de Systran (version 4). Les traductions de référence ont été produites par la post-édition de ces traductions candidates. La composition du corpus est détaillée dans l’Annexe 1.
Dans cette campagne d’évaluation, le GETA avait proposé un protocole d’évaluation pour le projet TRANSAT, donc ce corpus contient le résultat de mesures, comme la distance d’édition (Damerau, 1964, Levenshtein, 1966, Wagner and Fischer, 1974) en mots/caractères/pondérée, BLEU, NIST, et aussi des mesures subjectives (de fluidité et d'adéquation). (Voir la définition des mesures dans l’Annexe 2).
II.1.1.2.2 Corpus B@bel Unesco
Le corpus Unesco/B@bel (Boitet, Boguslavskij et al., 2007) a été créé dans le cadre d’un contrat de recherche avec l’Unesco. Nous avons traduit le site Web B@bel de l’anglais vers 4 langues cible (français, russe, espagnol, et chinois). Les prétraductions ont été produites par Systran v5 Premium (anglais→chinois/français/espagnol) et ETAP3[5] (anglais→russe). De plus des graphes UNL ont été construits semi-automatiquement.
Ce corpus contient environ 43200 mots (173 pages standard), et se présente comme un ensemble de multisegments, qui sont sauvegardés dans les fichiers texte, un par langue. Chaque segment source est aligné avec les 4 autres segments cible. Le corpus B@bel contient 906 graphes UNL, et un échantillon contient 50 exemples (environs 50 pages standard). Un exemple tiré du corpus B@bel est donné dans l’Annexe 3.
II.1.1.2.3 Corpus EOLSS
Le projet EOLSS/UnescoL a été réalisé
de février 2008 à octobre 2008 dans le cadre d’un contrat entre l’Association Champollion et la fondation UNDL[6],
visant à la traduction de l'anglais vers les 5 autres langues officielles de l’UNESCO (français,
espagnol, russe, chinois, arabe) de 25 articles de l'EOLSS (Encyclopedia of Life Support Systems).
Le corpus EOLSS contient 25 documents sur l’eau et l’écologie de l’encyclopédie EOLSS, représentant environ 220K mots (13676 segments) ou 880 pages standard. Chaque document est constitué d’un fichier HTML (.aspx), d’un fichier compagnon .unl, et de fichiers satellites (images, icônes, et autres hors-texte) (Figure 9). Le fichier .unl contient des graphes UNL représentant des segments découpés à partir du fichier .aspx correspondant. Le lien de téléchargement du corpus EOLSS est dans l’Annexe 4.
|
|

Figure 9 : Fichier HTML et fichier compagnon .unl
Pour adapter les documents à SECTra_w, nous avons changé .aspx en .html. Nous avons utilisé le système de TA Systran pour produire les prétraductions, puis nous avons post-édité les sorties de TA. Dans la Figure 10, on présente un document (GROUND AND SOIL WATER CHARACTERISTICS) parallèle anglais-français. Après la post-édition du document, nous avons créé la page Web traduite en langue cible, et un fichier .unl en langue cible.
|
|
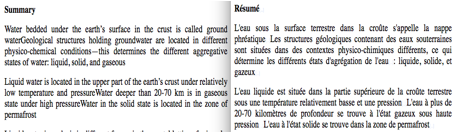
Figure 10 : Document 2 traduit de l’anglais vers le français
(GROUND AND SOIL WATER CHARACTERISTICS)
II.1.1.2.4 Corpus ERIM
Le corpus ERIM est un corpus de dialogues bilingues (français↔chinois, vietnamien, hindi, tamil) oraux interprétés. Un segment est constitué d'un tour de parole, et éventuellement d’un texte descriptif et d’un texte transcrit.
Voici un type de descripteur d’un dialogue français↔vietnamien du corpus ERIM.
|
|
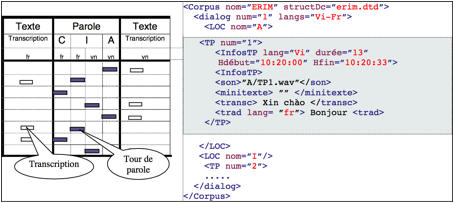
Figure 11 : Exemple de structure et de description d'un dialogue du corpus ERIM
La partie français↔vietnamien du corpus ERIM contient 4 séances de dialogue. Chaque séance contient 3 répertoires, 3 fichiers .wpl (par exemple, french.wpl, vietamese.wpl, et dialogue.wpl) et un fichier de transcription (comme le fichier xml dans la Figure 11). Chaque répertoire est nommé par le nom du locuteur (par exemple, Cantona, Tung, et Interp) ; il contient les tours de parole et les descripteurs. Les fichiers .wpl enregistrent les chemins des fichiers son. Par exemple, le fichier french.wpl (ou vietamese.wpl) enregistre les chemins des tours de parole en français (ou en vietnamien) émis/reçus par le locuteur français (ou vietnamien) et l’interprète (Figure 12). Le fichier dialog.wpl enregistre tous les tours de parole par ordre chronologique.
|
|
|

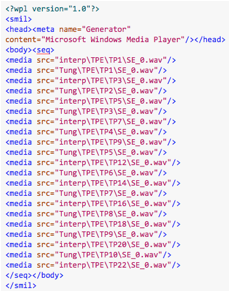
Figure 12 : Exemple du fichier french.wpl et vietnamese.wpl
Le répertoire du locuteur contient les fichiers .wav et 3 descripteurs (3 fichiers .xml : DSD.xml, DSL.xml TIER.xml).
· DSD.xml (Description Session Dialogue), enregistre l’information du session de dialogue.
· DSL.xml (Description Session Locuteur), enregistre l’information du locuteur.
· TIER.xml (Traces des Informations Emises et Reçues), enregistre (ou trace) la session de dialogue, ce qui en fournit un historique.
II.1.1.2.5 Corpus de brevets CLEF-IP 2011
Le corpus CLEF-IP contient des brevets, physiquement stockés comme une collection de fichiers XML encodant des documents de brevets. Voir le détail au VII.2.1.
II.1.1.3 Structure
interne des corpus est également hétérogène
Tableau 5 : Comparaison de l’organisations logiques, physiques, et interne de quelque corpus
|
Corpus |
Vue logique |
Organisation physique |
Organisation interne dans un corpus |
|
TRANSAT |
ensemble de multisegments |
Fichiers de texte par langue. |
L’entrée contient des segments avec des séparateurs de
segments et des scores. |
|
B@bel |
Ensemble de multisegments |
Fichiers de texte par langue |
Listes de paires d’énoncés <Seg_Source_L1,
Seg_Cible_L2>. |
|
EOLSS |
Ensemble de documents |
Chaque document correspond à un dossier, contenant 2
fichiers, .html et .unl. |
Le fichier .html est le « fichier principal », le fichier .unl
est le
« fichier compagnon », et est utilisé pour guider la
segmentation du
fichier .html. |
|
ERIM |
Ensemble de dialogues contenant des tours de parole avec
leur descripteurs. |
Chaque dialogue correspond à un répertoire, contenant des
fichiers son (.wav), des fichiers transcrits (.xml), et des fichiers texte
(.txt) |
Un fichier son (.wav) attaché à un fichier de
l’annotation selon une convention de nommage. |
|
CLEF-IP 2011 |
Ensemble de documents (.xml) |
Chaque document contient les segments multilingues. |
Un fichier XML |
II.1.2 Esquisse d'une méthode de modélisation des corpus de traductions
Pour modéliser la structure des données d’un corpus de traduction, nous nous sommes inspiré des bases lexicales et du modèle de données LEMON (LExicon Model for ONtologies). Nous souhaitons trouver une structure générique pouvant décrire tous les corpus de traductions, et une façon de décrire les relations entre de tels corpus. Nous distinguons les différents niveaux de structuration de ces corpus, et comparons les corpus existants pour identifier et lister les informations propres à chaque corpus de traductions (métadonnées).
II.1.2.1 Notions essentielles pour décrire un corpus
Pour décrire un corpus, nous utiliserons les notions de segment document, corpus, etc. définies dans la thèse de C. P. HUYNH et rappelées plus haut (pp. 20-23).
Les métadonnées sont par essence des informations sur les données. Elles servent le plus souvent à caractériser un objet par des informations homogènes, relativement à une collection d’objets. Pour formuler définir correctement les métadonnées, il faut donc bien connaître à la fois l’objet à décrire et les caractéristiques de la collection dans laquelle il doit être déposé. Nous avons choisi de décrire les corpus de traductions avec les informations du Dublin Core Metadata initiative[7]. Le Dublin Core (DC) est un schéma de métadonnées générique, et il permet de décrire des ressources numériques ou physiques et d’établir des relations avec d'autres ressources. Il comprend officiellement 15 éléments relatifs à la forme de description (titre, créateur, éditeur), à la thématique (sujet, description, langue, etc.) et relatifs à la propriété intellectuelle.
II.1.2.2 Niveau des métadonnées
Pour chaque entité (corpus, document, et segment), il contient les métadonnées adaptées. Chaque entité peut contenir des métadonnées génériques comme le norme de métadonnées dans le DC.
1. Title : nom donné à la ressource (celui par lequel elle est connue officiellement).
2. Subject : sujet du contenu de la ressource, décrit par un ensemble de mots-clés, par des phrases, ou par un code de classification.
3. Description : une description du contenu de la ressource. Peut contenir un résumé, une table des matières, une référence à une représentation graphique du contenu, ou un texte libre présentant le contenu.
4. Publisher : une entité responsable de la diffusion de la ressource, dans sa forme actuelle.
5. Contributor : la ou les entités qui ont contribué à la création du contenu de la ressource.
6. Date : une date associée à un événement dans le cycle de vie de la ressource.
7. Type : la nature ou le genre du contenu de la ressource.
8. Format : la matérialisation physique ou numérique de la ressource.
9. Identifier : référence non ambiguë à la ressource dans un contexte donné.
10. Source : référence à une ou plusieurs ressources à partir de laquelle la ressource actuelle a été dérivée.
11. Language : la langue du contenu intellectuel de la ressource.
12. Relation : référence à une autre ressource qui a un rapport avec cette ressource.
13. Coverage : portée ou couverture spatio-temporelle de la ressource.
14. Rights : information sur les droits associés à la ressource.
La norme de métadonnées du DC peut être utilisée dans différentes entités. Par exemple, quand on fait la description d’un corpus dans corpus, il faut préciser des métadonnées comme le nom du corpus, le sujet du contenu de la ressource, une description du contenu de la ressource, etc. Pour un document, il y a aussi les métadonnées de présentation. En même temps, il existe les autres métadonnées dans différentes entités. Par exemple, pour un segment post-édité dans une MT, il a un attribut « temps de post-édition ».
II.1.2.3 Niveau structurel
Pour la proposition d’une structure générique, nous étudions différents corpus, et nous proposons 3 niveaux de structure abstract d’un corpus : marco-, micro-, mésostructure.
La macrostructure décrit
l’organisation du corpus au niveau plus haut. Par exemple, un corpus contient
les documents monolingues, ou un corpus contient deux documents parallèles. Il
y a plusieurs types de macrostructure.
· Macrostructure-monolingue. le corpus contient un ou plusieurs documents monolingues.
· Macrostructure-multilingue. le corpus contient un ou plusieurs documents multilingues.
o Macrostructure-parallèle. Le corpus contient les documents parallèles.
o Macrostructure-comparable. Le corpus contient les documents comparables.
o Macrostructure-mixte. Le corpus contient des documents contenant des segments multilingues.
La microstructure décrit l'organisation des éléments dans un corpus. Par exemple, un document contient 100 segments français, et chaque segment est sauvegardé par ligne, ou un document du CLEF-IP contient les 3 champs <title>.
La mésostructure décrit les relations entre les éléments. Par exemple, "le segment B est la traduction du segment A", ou "le segment A a une description dans le document B".
II.1.3 Validation au niveau des métadonnées
II.1.3.1 Métadonnées pour le corpus d'évaluation à la TRANSAT
Les métadonnées du corpus d’évaluation à la TRANSAT contiennent 2 parties. La première concerne la description des segments monolingues extraits à partir du corpus BTEC, et l’autre concerne la description des résultats de TA avec les données d’évaluation.
Tableau 6 : Métadonnées du corpus BTEC (les segments extraits)
|
Métadonnées |
Valeur |
|
|
Nom de corpus |
BTEC |
|
|
Projet |
TRANSAT |
|
|
Langue source |
anglais |
|
|
Nombre de tours de
parole |
Partie I : 2223 |
4224 au total |
|
Partie II : 1998 |
||
|
Nombre de phrases |
Partie I : 2373 |
4486 au total |
|
Partie II : 2113 |
||
|
Nombre de mots |
Partie I : 14K (14001) |
22419 au total |
|
Partie II : 10K (10418) |
||
|
Nombre de mots par
tour de parole |
moyenne = 6,2; min =1; max =30 |
|
|
moyenne = 5.2; min = 1; max = 22 |
||
|
Nombre de mots par
phrase |
moyenne = 5,9; médiane = 5; min =1; max = 28 |
|
|
moyenne = 4,93; médiane = 5; min = 1; max = 19 |
||
|
Domaine |
Santé ; Accidents, perte, vol ; Itinéraire ;
Transports, et Location de voiture ; Non spécifique |
|
Tableau 7 : Métadonnées des données d’évaluation à la TRANSAT
|
Métadonnées |
Valeur |
|
|
Langue cible |
français |
|
|
Nom du système de TA |
Systran / Reverso |
|
|
Version du système de
TA |
Version 4 (Systran) Version 10 Pack Monde (Reverso) |
|
|
Évaluation subjective
à la NIST |
Fluidité |
(F1) Formulation parfaitement compréhensible sans effort,
que le style soit écrit ou oral. (F2) Formulation acceptable à l'oral, éventuellement
compréhensible en faisant un effort. (F3) Formulation non acceptable. |
|
Adéquation |
(A1) Toute l'information est transportée.
(A2) Presque toute l'information est transportée.
(A3) La moitié de l'information est transportée. (A4) Peu d’information est transportée.
(A5) Aucune information n’est transportée, ou il y a un
contresens.
|
|
|
Évaluation objective
fondée sur la distance d’édition |
Distance d’édition en
mots |
Par exemple : Dc=20,
Dw=7, D=9.6 Dc : Character distance Dw : word distance D : sentence distance |
|
Distance d’édition en
caractères |
||
|
Distance d’édition
pondérée |
||
|
BLEU |
Par exemple : 34.36% |
|
|
NIST |
Par exemple : 4,08 |
|
|
Évaluateur |
Par exemple : Hervé
Blanchon, Jean-Philippe Guillaud |
|
II.1.3.2 Métadonnées pour le corpus Unesco/B@bel
Dans le cadre du projet UNESCO/B@bel, on a traduit le texte du site Web B@bel (équivalant 173 pages standard, 43200 mots) de l’anglais vers le chinois, le français, le russe, et l’espagnol. Ce corpus parallèle a été produit par la post-édition, donc il contient les métadonnées relatives à la description de la post-édition.
Tableau 8 : Métadonnées du corpus UNESCO-B@bel
|
Métadonnées |
Valeur |
|
|
Nom de corpus |
B@bel |
|
|
Nom du projet |
B@bel UNESCO |
|
|
Type de corpus |
Corpus parallèle
multilingue |
|
|
Méthode de création |
Post-édition |
|
|
Langue source |
Anglais |
|
|
Langue(s) cible(s) |
Chinois, français,
russe, espagnol |
|
|
Nombre de mots |
43200 |
|
|
Système de TA |
Systran v 5.0
Premium (en→fr/es/ch)
ETAP3 (Labo IPPI)
(en→ru) |
|
|
Nombre de l’UNL graphe |
906 graphes UNL |
|
|
UNL graphe |
Par exemple :
voir l’Annexe 3 |
|
|
Échantillon de graphes
UNL |
50 graphes UNL
(environ 5 pages standard) |
|
|
Temps de post-édition
sur les segments |
Temps de post-édition
(par segment) |
Par exemple :
voir l’Annexe 3 |
|
Temps de post-édition
(au total) |
25 minutes / page
standard (Systran) 20 minutes / page
standard (ETAP3) |
|
II.1.3.3 Métadonnées pour le corpus EOLSS
Le corpus EOLSS contient 25 documents. Chaque document est constitué de 2 fichiers .aspx (.html), et d’un fichier compagnons .unl, et de fichiers satellites (images, icônes, et autres hors-texte). Le fichier .unl contient les graphes UNL représentant des segments découpés à partir du fichier .html correspondant. Pour la description du corpus EOLSS, nous essayons de présenter les métadonnées en 3 niveaux de structure abstraite au niveau plus haut (macro-, micro-, mésostructure).
Les métadonnées de macrostructure ont pour but de décrire l’information globale du corpus (Voir Tableau 9).
Tableau 9 : Métadonnées du corpus EOLSS au niveau de la macrostructure
|
Métadonnées |
Valeur |
|
Nom du corpus |
EOLSS (Encyclopedia of Life Support Systems) |
|
Langue source |
Anglais |
|
Nombre des documents |
25 |
|
Système de TA |
Systran V6 |
|
Nombre des mots source
|
220K |
|
Méthode de création |
Post-édition |
|
Lien original |
|
|
Lien source |
|
|
Nom du document |
Par exemple : D2_E2_03_05_TXT |
|
Nom du fichier html |
Par exemple : D2_E2_03_05_TXT_English.html D2_E2_03_05_TXT_French.html |
|
Nom du fichier UNL |
Par exemple : D2_E2_03_05_TXT.unl |
|
Nom du fichier
satellite |
Par exemple : D2_E2_03_05_TXT_skeleton.txt |
Les métadonnées de microstructure
décrient la structure des données dans un document. Nous présentons un
exemple du document 2 (Ground and soil water characteristics). Il
y a les métadonnées pour les fichiers HTML, un fichier
source avec son fichier cible a les mêmes métadonnées. Dans le Tableau 10,
on prend le fichier source comme un exemple.
Tableau 10 : Métadonnées d’un fichier HTML au niveau de la microstructure
|
Métadonnées |
Valeur |
|
Nom du fichier source |
D2_E2_03_05_TXT_English.html |
|
Type du fichier |
.html |
|
Nombre de segments |
502 |
|
Nombre de mots |
6911 |
|
Titre |
“Ground and soil water
characteristics” |
|
Langue source |
anglais |
|
Auteur |
A.G. Kocharyan |
|
Adresse |
Laboratory of Water Quality, Water Problems Institute, Russian Academy of Sciences, Moscow, Russia |
|
Mots-clés |
“physically bound
water, free water, water structure, soil and ground water …...” |
|
Résumé |
“Water bedded under
the earth’s surface in the crust is called ground water……” |
|
Chapitre relatifs |
“Chapter 2” |
|
Glossaire |
“Artesian water :
all ground water, excluding subsoil water, bedded between ……” |
|
Bibliographie |
“Bloch A.M. (1965).
Water structure and geological processesLeningrad, "Nedra( This book
reveals the links between the physical structure and chemical peculiarities
of water)……” |
|
Esquisse biographique |
“Andrey G. Kocharyan
graduated from the Geological Faculty, Institute of Chemistry and Oil, Baku,
in 1960. He received his Ph. D. in geochemical techniques of deposits’ search
in 1968 at Baku State University, Geological faculty. …….” |
|
Date de livraison |
2007-12-03 |
|
Date de la dernière mise
à jour |
2008-06-26 |
Dans le Tableau 11, on donne les métadonnées du fichier .unl.
Tableau 11 : Métadonnées d’un fichier UNL au niveau de la microstructure
|
Métadonnées |
Valeur |
|
Nom du fichier |
D2_E2_03_05_TXT_en.unl |
|
Type du fichier |
.unl |
|
ID |
{S:1} |
|
Phrase source |
{org} Agriculture
water reuse and health {/org} |
|
UNL |
{unl} and(health(icl>state):0U.@entry, reuse(icl>act):0K) obj(reuse(icl>act):0K, water(icl>liquid):0E) mod(water(icl>liquid):0E, agriculture(icl>activity):02) {/unl} |
Les métadonnées de la mésostructure
(Tableau
12) visent à montrer la relation entre les éléments du corpus, Par exemple, on montre
la relation de traduction existant entre une phrase source et une phrase cible,
avec éventuellement l’information complémentaire.
Tableau 12 : Métadonnées d’un corpus EOLSS au niveau de la mésostructure
|
Métadonnées |
Valeur |
|
ID |
$$_sent_1 |
|
Phrase source |
Agriculture water reuse and health |
|
Langue source |
anglais |
|
Phrase post-éditée |
RÉUTILISATION DE L'EAU D'AGRICULTURE ET SANTÉ |
|
Langue cible |
français |
|
Système de TA |
Systran |
|
Sortie de TA |
RÉUTILISATION ET SANTÉ DE L'EAU D'AGRICULTURE |
|
Post-éditeur |
GETALP/XWikiGuest |
|
Niveau de postéditeur |
3 |
|
Date |
2008-09-26 11:14:40.0 |
|
Temps de post-édition |
17s |
|
Score de qualité |
17/20 |
|
Version |
1 |
II.1.3.4 Métadonnées pour les corpus ERIM
Le Tableau 13 montre des métadonnées du corpus ERIM au niveau de la macrostructure.
Tableau 13 : Métadonnées d’un corpus ERIM au niveau de la macrostructure
|
Métadonnées |
Valeur |
|
Nom du corpus |
ERIM français-vietnamien |
|
Type du corpus |
Parole + fichier accompagnons |
|
Support |
.wav + .xml |
|
Langues de parole |
français ↔ vietnamien |
|
Nombre de tours de
parole du corpus |
Par exemple : 4 séances contenant 102 tours de parole dans “Réservation d'hôtel” |
|
Date de création |
“2006-09-08” |
|
Date de la dernière
modification |
“2006-09-10” |
|
Nombre de tour de
parole par séance |
Par exemple : 22 tours de parole dans la séance “Réservation d'hôtel 060908-1344” |
|
Locuteur |
Par exemple, Tung / Eric Faffiote |
|
Langue du locuteur |
français/vietnamien |
|
Interpréteur |
… |
Le Tableau 14
montre des métadonnées du corpus ERIM au niveau de la microstructure.
Tableau 14 : Métadonnées de la séance dans le corpus ERIM a au niveau de la microstructure
|
Métadonnées |
Valeur |
|
Nom |
“Réservation d'hôtel 060908-1344” |
|
Sujet |
“Réservation d'hôtel” |
|
Langues de parole |
A et B (Par exemple, français ↔ vietnamien) |
|
Nombre de tour de
parole |
41 |
|
Date de création |
“2006-09-08” |
|
Date de la dernière
modification |
“2006-09-10” |
|
Nombre de tours de
parole en langue A |
11 |
|
Nombre de tours de
parole en langue B |
11 |
|
Locuteur |
Par exemple, Tung et Cantona |
|
Langue du locuteur |
Par exemple, français / vietnamien |
|
Interprète |
… |
|
Taille de parole |
06 : 0908 mn |
Le Tableau 15
montre les métadonnées du corpus ERIM au niveau de la mésostructure. À ce niveau, les
métadonnées ont pour but présenter l’information sur les fichiers .wav (parole).
Tableau 15 : Métadonnées d’un corpus ERIM au niveau de la mésostructure
|
Métadonnées |
Valeur |
|
Nom (de l’unité de
parole) |
“TP1” (Tour de parole 1) |
|
Lien entre fichiers |
TP1_fr.wav + TP1_fr.xml |
|
Langues de parole |
français |
|
Rôle |
Par exemple, descripteur TP1_fr.xml |
|
Locuteur |
Par exemple, Cantona |
|
Sexe du locuteur |
Par exemple, male |
|
Nationalité |
français |
|
Langue du locuteur |
français |
|
Attributs |
Taux
d’échantillonnage : 22000 Bits par
échantillonnage : 16 Canaux audio : 1 |
|
Heure de début |
Par exemple, 10 :20 :00 |
|
Heure de fin |
Par exemple, 10 :20 :33 |
|
Durée |
13 |
|
Transcription associée |
TP1_fr.txt |
|
Date de création |
“2006-09-08” |
|
Date de la dernière
modification |
“2006-09-10” |
II.1.3.5 Métadonnées pour les corpus de brevets CLEF-IP 2011
Du point de vue des métadonnées, le corpus CLEF-IP
2011 est un exemple spécifique. Il contient non seulement les
métadonnées génériques, mais encore les métadonnées du document de brevet. On
sépare des métadonnées en 2 parties. La première partie est constituée par les
métadonnées du corpus CLEF-IP, et la seconde par celles
concernant sur un document de brevet.
Tableau 16 : Métadonnées du corpus CLEF-IP 2011
|
Métadonnées |
Valeur |
|
Nom du corpus |
CLEF-IP 2011 |
|
Auteur |
EPO |
|
Type de fichier |
Xml |
|
Langues |
anglais, français,
allemand |
|
Langue source |
multilingues |
|
Langue cible |
multilingues |
|
Nombre de documents |
> 2,5M |
|
Type de document de
brevets |
xml |
|
Nombre de brevets |
> 1,5M |
|
Nombre de fichiers |
3,5M fichiers xml |
|
Version |
|
|
Date de création |
|
|
License |
Creative Commons
Attribution-NonCommercial-ShareAlike 3.0 Unported License. |
Pour présenter les métadonnées d’un document de brevet, nous
prenons un document (EP-0000007-B2.xml)
comme exemple. Voici les métadonnées principales ;
une version complète est donnée dans l’Annexe 6.
Tableau 17 : Métadonnées d’un document de brevet
|
Métadonnées |
Valeur |
|
|
Nom du fichier |
EP-0000007-B2.xml |
|
|
ucid (ID unique) |
EP-0000007-B2 |
|
|
Pays |
EP (EPO) |
|
|
Numéro du fichier |
0000007 |
|
|
Genre |
B2 |
|
|
Langue |
fr |
|
|
Date de publication |
19841121 |
|
|
Date de production |
20100220 |
|
|
ID de famille |
Identificateur de la famille DOCDB
(utilisation pour le regroupement des familles simples) |
|
|
ID de référence du
fichier |
interne (utilisé par le fournisseur de
données) |
|
|
Nom du document de
brevet |
EP-78200026-A |
|
|
Retrait |
Retrait d’un document (oui est la seule
valeur utilisée) |
|
|
Page du document |
Utilisé dans les données EP/WO pour la
section de recherche-rapport. Cet
élément concerne les références à la description et les revendications
(amendées) du document. |
|
|
Relation |
"addition, division, continuation,
continuation-in-part, continuing-reissue, reissue, us-divisional-reissue,
reexamination, us-reexamination-reissue-merger, correction,
utility-model-basis, us-provisional-application, related-publication" |
|
|
document-id |
pays, numéro de document, genre, date, texte, langue |
|
|
abstract |
langue et source |
|
|
description |
invention-title technical-field background-art disclosure description-of-drawings |
best-mode mode-for-invention industrial-applicability sequence-list-text heading|img|imgref|p |
|
claims |
langue, type déclaration, revendication texte de revendication référence de revendication |
|
|
claim |
id, numéro type de
revendication |
|
II.2 Conception de nouvelles fonctionnalités et développements en cours
II.2.1 Nouvelles fonctionnalités
II.2.1.1 Intégration de « minidictionaires » associés aux segments
Pour faciliter l’utilisation des ressources lexicales, nous avons intégré des « minidictionaires » à l’interface d’iMAG et de SECTra_w. Pour les ressources « finalisées », à savoir les traductions des mots et des termes qui sont présents dans des traductions (de segments) de qualité suffisante (pas les sorties brutes de TA, mais les post-éditions).
Parmi ces traductions, on peut encore distinguer celles qui sont « recommandées » pour le projet en cours. Pour chaque segment, on dispose aussi des informations lexicales potentiellement utiles, dans la liste des ressources indiquées, et on peut sauvegarder le résultat dans une structure de données (minidictionaires) associée à ce segment. La structure de minidictionaires est donnée dans l’Annexe 7.
II.2.1.2 Création d’une API pour appeler le système CREATDICO
CREATDICO est un intergiciel de consultation de dictionnaires. Avec cet intergiciel, on peut envoyer un texte ou un segment pour demander une consultation pour chaque lemme du texte ou du segment. Pour faire les lemmatisations, CREATDICO appelle LEXTOH (intergiciel de lemmatisation). L'API de CREATDICO a 10 paramètres :
Tableau 18 : 10 paramètres de l'API de CREATDICO
|
typeEntry
(type
d'entrée), |
input (type d'entrée) |
|
output (type de sortie) |
ls (langue source en ISO
639-2) |
|
lc (langue cible en ISO
639-2) |
serv (serveur de service) |
|
dico (nom de dictionnaire) |
lemmat (outils d'analyse
morphologique) |
|
trace (trace pour debogage) |
formule (affichage de l'interface
de formulaire) |
La sortie de CREATDICO est une sortie dédiée à la structure "MS (Minidico_SECTra)" (Voir l’Annexe 7). Pour cette sortie, il y a un fichier de configuration qui permet de définir des valeurs par défaut des paramètres, par exemple :
Tableau 19 : Exemple de fichier de configuration de CREATDICO
|
typeEntry = txt lemma = xip (condition : ls = {fra, eng}) lemma = jieba (condition : ls = {zho}) etc. serv = pivax dico = * // commentaire : tous les dictionnaires de pivax |
Dans notre cas, on n'utilise jamais les paramètres : trace et formule, et ils ne sont pas obligatoires. Voici un exemple de l'utilisation de l'API de CREATDICO :
Tableau 20 : Exemple d’un lien pour l'utilisation de l'API de CREATDICO
Pour faciliter l’utilisation des dictionnaires, nous avons ajouté
un panneau de dictionnaires à l’interface de SECTra_w.
Quand l’utilisateur fait la post-édition, il peut double-cliquer sur un mot,
puis choisir les dictionnaires existants dans ce panneau.
|
|
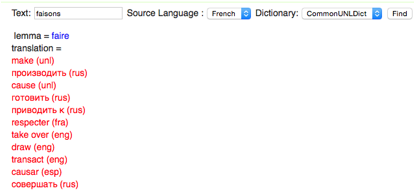
Figure 13 : Capture d'écran de panneau de dictionnaires ajouté à SECTra_w
Le résultat est affiché dans le champ en bas. Par exemple, si on double-clique sur le mot « faisons », il est ajouté automatiquement dans le champ de saisie. On choisit la langue source et le dictionnaire, et on clique sur le bouton « Find ». Le résultat est affiché en couleur rouge (Figure 13).
II.2.1.3 Manipulation de la MT
Sur un segment. Le résultat des systèmes de TA a évolué lors des mises à jour. Sur SECTra_w, il faut permettre à l’utilisateur de supprimer les traductions de TA, et à de rappeler les systèmes de TA de la dernière version. Si la post-édition n’est pas bonne, s’il existe les erreurs sur le segment post-édité, il faut aussi permettre à l’utilisateur de le supprimer. Pour réaliser cette fonction, nous avons ajouté 2 boutons avant la traduction de TA. Le bouton « Clean » permet de supprimer la traduction de TA sur l’interface de SECTra_w, et aussi sur la MT. Le deuxième bouton « Get » permet de recalculer (retraduire) le segment source par TA. Si la post-édition n’est pas bonne, on peut le supprimer par bouton « Delete ». (Voir Figure 14).
|
|
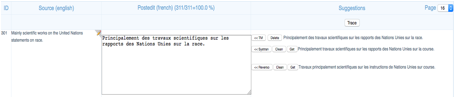
Figure 14 : Interface de SECTra_w intégrant les boutons « Delete », « Clean » et « Get »
Sur un corpus. On a besoin de (re)traduire une sélection de segments, éventuellement tous, depuis l’interface de SECTra_w. Pour réaliser cette fonction, nous avons créé une interface permettant de choisir les segments source et un ou plusieurs systèmes de TA. L’utilisateur peut cocher les segments sources, et les traduire par le système de TA choisi. Sur cette interface, il peut aussi importer des résultats de TA dans la MT associée. Il demande de préparer les segments source et les traductions, et les phrases sont alignées par ligne.
Voici une image d’écran (Figure 15).
|
|
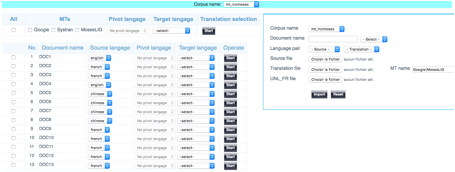
Figure 15 : Traduction des segments sélectionnés et ajout à la MT
II.2.2 Programmabilité
II.2.2.1 API avec CREATDICO, Tradoh, SegDoc
SECTra_w a montré une possibilité de l’utilisation de l’API, et il permet l’accès à différents types
de services. Pour appeler CREATDICO, Tradoh et SegDoc, on a intégré l’API sur SECTra_w, et les
fonctions sont réalisées en Groovy. On peut suivre une instruction pour remplir les paramètres dans un
lien. Quand on accède ce lien avec nos valeurs pour les paramètres, on peut
recevoir le résultat immédiatement sur une nouvelle page Web. Par exemple, on
peut appeler les systèmes de TA via Tradoh sur l’API de SECTra_w (Figure
16). On remplit les paramètres (nom de TA,
langue source/cible, et texte source), et le système génère un lien pour
obtenir la traduction.
|
|
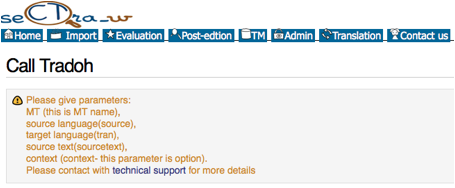
Figure 16 : Exemple de l'API « Call Tradoh »
II.2.2.2 Vers
un langage de commandes pour SECTra_w
La définition d’un tel langage est particulièrement
intéressante parce qu’il permettra de réaliser toutes les opérations sur les
corpus, à la fois en ligne de commande et en une formulaire, et aussi de
générer des codes pour les interfaces, ce qui accélérera leur développement
tout en assurant leur homogénéité.
L’exemple le plus utilisé de langage déclaratif dédié à la
sélection d’éléments et à la commande d’actions à exécuter sur toutes les données
sélectionnées est SQL. Le langage à définir est bien de
cette nature.
Par exemple, en MySQL, la commande qui sélectionne tous les enregistrements de la relation mémorisée dans la table `demo2`.`segments` et dont le champ `creation_date` est compris entre '2013-01-16' et '2013-01-18' est :
SELECT * FROM `demo2`.`segments` WHERE `creation_date` > '2013-01-16' AND `creation_date` < '2013-01-18'.
Le langage d'interrogation des données permettant les sélections, la définition de sélections dans les corpus doit s’en inspirer.
Par exemple :
Selection 3 = $seg \in demo2 \and $creation_data \in 2013-01-06 .. 2013-01-18 \and {{ $level = 3 \and $score > 13}}
L’analyseur du langage en question sera faite en ANTLR (Parr and Quong, 1995), générateur de compilateurs dont le GETALP a une grande expérience, à cause du projet Ariane-Y. Les règles de grammaire décrivant le langage et transmises à ANTLR peuvent définir des actions.
II.2.3 Modularité
II.2.3.1 Extraction de codes depuis XWiki vers Java dans des fichiers externes
Dans II.2.2.3, nous avons un peu parlé du problème de la programmation en XWiki, et nous avons listé et classifié les fonctions de SECTra_w/iMAG dans le cadre du projet Traouiero. Pour réaliser la modularité de SECTra_w/iMAG, nous avons aussi extrait les codes de XWiki (en Groovy). Comme Groovy est proche de Java, nous les avons reprogrammés en Java, et les avons publiés sous forme de packages de Java (.jar).
Par exemple, l’extraction de la fonction « Segmentation de la page Web » est détaillée à http://tools.aximag.fr/prepaTradSeg/_README.htm.
La version initiale de ce service avait seulement pour objectif de fournir aux iMAG le prétraitement d'une page Web. D’abord, on a l'URL de la page ou un contenu HTML (sérialisation du DOM fournie par un navigateur). Ensuite on appelle un outil de segmentation d'un contenu HTML en segments, avec le service http://tools.aximag.fr/enrichir/seghtml et un paramétrage de l'appel à ce service, tel que le résultat soit fourni dans un format attendu par l'uniformisateur d'appels à des systèmes de TA. Cela produit la même forme de sortie que celle qu'aurait fournie le service GT pour le contenu source, avec l'habillage de chaque segment source identifié par le traitement du segmenteur par l'intercalage de 2 nœuds imbriqués dans le DOM.
II.2.3.2 Vers un "serveur corporal pour la TA" avec lien en cours SECTra-Ariane
Ariane-G5 est un générateur de systèmes de TA reposant sur 5 langages spécialisés pour la programmation linguistique (LSPL)[8]. Chacun de ces langages est compilé, et les tables internes produites sont données en paramètres au "moteur" du langage.
Bien que le système Ariane-G5 ait déjà une fonction de post-édition et de gestion de corpus, on voudrait déléguer à un « serveur corporal » le soin de gérer les corpus. La motivation de cette délégation est identique à celle des connaissances lexicales où on pourrait profiter des avantages d’un système sur le Web comme SECTra_w, et surtout avancer vers une unification des ressources corporales.
Dans le système Ariane-G5, à l'entrée et à la sortie du processus de traduction, l'unité de traduction est une simple chaîne de caractères. Les chaînes doivent être codées en EBCDIC Dans l’implémentation Ariane-H (Héloïse de V. Berment (Boitet and Berment, 2012)), elle sont en ASCii.
En Ariane-G5, l’organisation est la suivante :
· fichier texte source.
· fichier de description arborescente (utilisé pour calculer les unités de traduction).
· fichier de segmentation en unités de traduction, selon une fenêtre paramétrable par le linguiste (200-300 caractères).
· fichiers d’arbres de résultats intermédiaires possibles.
o chaque fichier selon la chaîne d’exécution/production
o fichiers selon les phrases. Chaque fichier contient la liste des arbres fournis par cette phase, un pour chaque unité de traduction.
· fichiers résultats de traduction automatique d’une ou plusieurs chaînes d’exécution. Le numéro de la chaîne d’exécution est inclus dans le nom de fichier.
· fichiers de révision.
Avec un corpus, on a 2 fichiers « spéciaux », $DESCR contenant la liste des textes de ce corpus avec le format <nom externe, nom interne>, et un autre contenant une liste hiérarchique de séparateurs (au maximum 8).
Ariane-G5 a 3 types de fichier de résultat.
Résultat intermédiaire (liste d’arbres décorés) est un format d’échange entre les étapes du système. Ce format représente des arbres décorés, les formes et UL utilisées.
Résultat brut de la traduction est la concaténation des traductions des unités de traduction, et on n’a plus accès aux unités individuelles.
Révision. Pour un texte donné, il y a un seul fichier de révision par langue et par chaîne de traduction.
La version actuelle de SECTra_w a été construite pour être utilisable aussi bien par des programmes que par des utilisateurs humains. Pour l'intégrer à Ariane-G5, il faut :
· définir et implémenter certaines fonctions sur les corpus, existant en Ariane-G5, mais pas encore intégrées à SECTra_w ;
· définir une syntaxe appropriée pour échanger avec Ariane-G5 des segments, des documents, des corpus et des mémoires de traductions (formats d'import-export)
· définir une structure interne dans Ariane-Y pour les données "corporales".
En particulier, la révision (en construction) Ariane-Y doit pouvoir envoyer des résultats de traitement,
· sur des segments (par exemple des arbres d’analyse ou des graphes UNL, à ranger comme des « annotations » au même titre que les TA et les PE),
· sur des documents (graphe de chaînes d’arbres, par exemple).