Chapitre V Construction de systèmes de TA pour le chinois avec Moses en contexte de recherche : le projet TABE-FC
Introduction
Au laboratoire,
notre recherche sur la TA fr-zh a été surtout menée dans le cadre du projet TABE-FC, défini et
commencé grâce à un séjour sabbatique d’un an du Pr Yidong Chen de XMU. Un des
buts de ce projet est de pouvoir comparer différents « paradigmes »
de TA, sans se limiter aux systèmes purement « Moses ». Il s’agit aussi de systèmes « à
règles » comme Neon (de XMU), ou de systèmes empiriques utilisant des statistiques ainsi que
des informations sémantiques et pragmatiques (architecture du Pr. Yidong Chen (Chen et al., 2014)).
Pour construire des
systèmes de TA français-chinois de bonne qualité en contexte de recherche, nous
étions libre de sélectionner des sous-langages très restreints (comme des
« brèves » de sites
boursiers), ou pour lesquels nous aurions déjà un corpus parallèle de bonne
qualité (comme pour le site du LIG). Nous avons travaillé sur les deux
sous-langages mentionnés ci-dessus, et présentons ce qui a été fait pour celui
des sites boursiers et économiques.
Après avoir extrait environ 1000 pages Web de ces sites, nous avons extrait environ 3000 bisegments, puis les avons filtrés et avons obtenu une MT de bonne qualité. La quantité de segments parallèles n’étant pas suffisante pour entraîner un système Moses, nous avons créé 3 iMAG pour 3 sites Web boursiers, et nous avons post-édité les segments prétraduits par GT, grâce à la participation de 4 stagiaires chinois étudiants à l’UJF. Cela fait, nous avons pu construire des systèmes Moses, et les avons évalués (distance de post-édition, temps, ainsi que BLEU et NIST). Nous sommes arrivés à des résultats compréhensibles, mais pas encore très fiables.
V.1 Buts du projet TABE-FC
Le projet TABE-FC est un projet
collaboratif mené par l'Université de Grenoble, LIG-GETALP et l'Université de
Xiamen (XMU, 厦门大学, Xiamen
University), et visant à créer des instances d'un nouveau type de système de
traduction automatique statistique utilisant des ressources lexico-sémantiques
et discursives.
V.1.1 Buts théoriques
Le but concret est de développer des systèmes de TAS français↔chinois pour des sites boursiers et économiques. Comme très peu de corpus ou de dictionnaires bilingues français↔chinois sont disponibles sur Internet, l'anglais est utilisé comme « pivot » pour construire les équivalents français↔chinois par transitivité. Outre la description générale de ce projet, nous décrivons les progrès sur deux axes de recherche lies à ce projet. Pour cela, nous utilisons une méthode, proposée par XMU, d'induction de probabilité fondée sur la similarité thématique, qui produit des tables de traduction français-chinois à partir de tables de traduction français-anglais et anglais-chinois. Pour disposer de bons corpus parallèles français-chinois, nous utilisons un système Web de post-édition collaborative qui peut déclencher l'amélioration incrémentale du système de TA en utilisant des mesures d'évaluation de TA et en extrayant la "meilleure partie" de la mémoire de traductions courante.
V.1.2 Buts pratiques
Ce projet se concentre sur deux objectifs pratiques. Nous prenons qu’une utilisation opérationnelle permettrait d’obtenir une excellente qualité. Le premier est de construire un service de systèmes de TA français↔chinois. Tout d’abord, nous nous restreignons à des sous-langages observés, puis nous récupérons et construisons la ressource français↔chinois, et créons finalement un système de TA.
À cause de la limitation des ressources français-chinois, nous essayons de construire le système de TA français-chinois via une langue pivot (anglais) pour faire l’extraction de la traduction équivalent.
Le deuxième objectif est intégré notre système de TA dans SECTra_w/iMAG (via Tradoh). Pour cela, nous créons des iMAG dédiées pour les sites Web boursiers et économiques. Notre plate-forme permet d’accéder aux sites Web en multilingue, et fournit déjà une traduction français→chinois de bonne qualité.
V.1.3 Définition du projet
Nous avons organisé ce projet avec une architecture à trois niveaux, contenant sept « missions » (Figure 22). Tout d’abord, nous travaillons pour la construction de ressources français-chinois orientées vers l’économie (corpus parallèles, ressources sémantiques bilingues, banques d’annotations discursives, etc.) en vue du développement. Ensuite, nous construirons un nouveau modèle de TA basé sur la sémantique et l’information de discoure (niveau de la recherche fondamentale). Enfin, nous prévoyons de construire un système Web de TA, et de l’appeler par SECTra_w/iMAG ou par JianDan-eval pour améliorer la qualité de traduction des sites Web économiques (niveau de l’application).
|
|
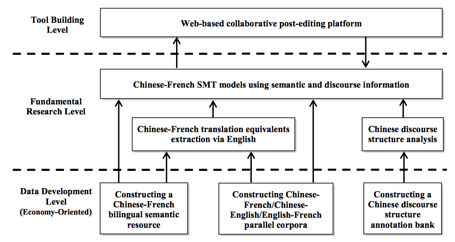
Figure 22 : Architecture à 3 niveaux et 7 « missions » du projet TABE-FC (Chen, Wang et al., 2014)
V.2 Constitution des corpus d'apprentissage
V.2.1 Recherche de sites et collecte de pages Web monolingues et bilingues
Comme déjà dit, il est difficile de construire un grand corpus parallèle chinois-français, en particulier pour le domaine économique.
Par conséquent, il est raisonnable de construire les ressources destinées à la construction de systèmes de TA chinois-français en utilisant l'anglais comme un pivot. Nous construisons un corpus anglais-chinois et le corpus anglais-français liés au domaine de l'économie. Ensuite, pour soutenir l'apprentissage des connaissances sur les transformations structurelles entre le chinois et le français, nous créons un corpus parallèle français-chinois par transitivité et révision (en PE).
Nous avons essayé de chercher une ressource existante pour construire des données d’apprentissage. Certains sites Web économiques contiennent des segments multilingues, par exemple, le site « Bourse de Paris »[1] (français-anglais), le site « TMX »[2] de Toronto (anglais-français), « SZSE » de Shenzhen (chinois-anglais) (深圳证券交易所), et le site « abnnewswire.net »[3] (multilingue).
Nous avons téléchargé les pages Web parallèles (.html) (Figure 23), et puis fait l’alignement et l’extraction des segments parallèles sur les pages Web en utilisant LF Aligner.
|
|
Figure 23 : Exemple de page Web économique parallèle
V.2.2 Nettoyage et filtrage
À partir des sites Web liés à l'échange d'actions, environ
1000 pages bilingues ont été explorées et traitées (le Tableau 43
présente les statistiques de cet ensemble de données).
Tableau 43 : Statistiques des pages Web collectées
|
Paire de langues |
Nombre de pages |
Taille |
|
chinois-anglais |
761 |
39,4Mo |
|
anglais-français |
250 |
12,5Mo |
Pour obtenir un
corpus parallèle propre, il est nécessaire de nettoyer les pages Web
récupérées. Ce nettoyage est une opération informatique qui demande un
paramétrage souvent poussé.
Nous avons présenté
plus haut les problèmes à résoudre pour « filtrer » des corpus
bilingues provenant de la faire du Web. Dans le cas des pages du site Web « Bourse
de Hong Kong », une page Web en anglais contient le texte entouré de balises
html, avec
une valeur particulière de l’attribut class.
Dans la Figure 24, le texte anglais et le texte chinois sont
alignés, ils ont différentes valeurs de « class ». Nous choisissons d’abord les balises associées (<div class= ‘…’), puis nous comparons le nom
de « class », et ajoutons un
suffixe “_c” pour la partie chinoise. Nous extrayons
enfin le texte anglais et le texte chinois. Nous trouvons qu’il y a un
commentaire mélangé avec le texte, et nous ne pouvons pas être sûr que ce texte
est bien traduit, donc nous l’éliminons.
|
|
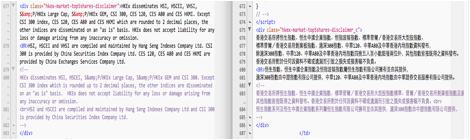
Figure 24 : Exemple d’une page Web du site de "Bourse de Hong Kong" en format html
À la fin de ce
processus, nous avons obtenu 3000 bisegments « propres » extraits des
sites Web boursiers, en anglais-chinois. Les segments chinois étaient en caractères
traditionnels ; nous les avons convertis en caractères simplifiés, grâce
au système de conversion intelligente des caractères chinois simplifiés et
traditionnels (Shi et al., 2013) [4].
Tableau 44 : Exemple de conversion des caractères chinois du traditionnel vers le simplifié
|
Traditionnel |
董事會整體負責確保集團的會計及財務匯報制度健全,並設有適當的內部監控及風險管理系統。 |
|
Simplifié |
董事会整体负责确保集团的会计及财务汇报制度健全,并设有适当的内部监控及风险管理系统。 |
|
Traditionnel |
財務匯報 董事會承諾以平衡及清晰可明的方式向股東及其他權益人評估集團的表現、財務狀況及前景。 |
|
Simplifié |
财务汇报 董事会承诺以平衡及清晰可明的方式向股东及其他权益人评估集团的表现、财务状况及前景。 |
|
Traditionnel |
這承諾包括所有發布資料,包括但不限於財務報表、按監管要求發出的公告和其他公司通訊。 |
|
Simplifié |
这承诺包括所有发布资料,包括但不限于财务报表、按监管要求发出的公告和其他公司通讯。 |
Nous les avons mis
en format txt et tmx. Voici un exemple des segments extraits au format tmx dans le Figure 25.
|
|

Figure 25 : Exemple de segments chinois-anglais extraits à partir de pages Web
Nous avons utilisé
la même méthode pour extraire des segments parallèles anglais-français à partir
du site Web « Bourse de Paris ». Nous avons obtenu 2000 segments
français-anglais (voir le Tableau 45).
V.2.3 TA par GT, puis PE (production d'un corpus parallèle)
Nous avons donc pu créer un corpus chinois-anglais par extraction de bisegments à partir des sites Web boursiers, et la traduction anglaise est d’assez une bonne qualité. Nous avons donc pu les utiliser pour entrainer le système de TA.
Pour la paire de langues français-chinois, nous n’avons pas de corpus parallèle, bien que nous ayons trouvé des sites Web boursiers et économiques disponibles en français et en anglais. C’est le cas du site « TMX » de Toronto, où le texte français est traduit par TA sans PE en anglais, mais pas en chinois.
Remarque : les utilisateurs semblent bien « couler » en anglais, mais il y a de nombreux contresens.
Pour construire le corpus français-chinois, nous créons une iMAG pour post-éditer les segments du français vers le chinois. Nous choisissons le site Web « Bourse de Paris[5] » comme la ressource française. 2 étudiantes chinoises nous ont aidé à faire la post-édition dans le cadre de leurs stages TER de M1-info.
|
|
Figure 26 : Capture d'écran de l'iMAG "Bourse de Paris" en chinois
Pour assurer la qualité des segments, il faut choisir quelques segments à post-éditer. Le site Web « Bourse de Paris » contient un centre d’apprentissage, et il présent les règles du marché, des définitions, une glossaire de bourse, etc. Nous avons post-édité les résultats de TA fournis par GT.
Dans la Figure 27, nous montrons un exemple de la traduction de GT et la post-édition faite dans SECTra_w. GT traduit “Action” comme “Ce que l’on fait.” (行动), mais ici, il faut le traduire par « stock » (股票).
|
|
|
|
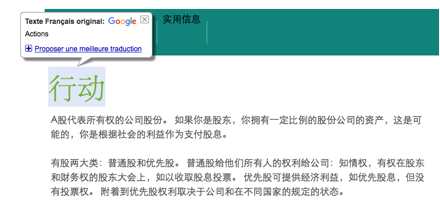
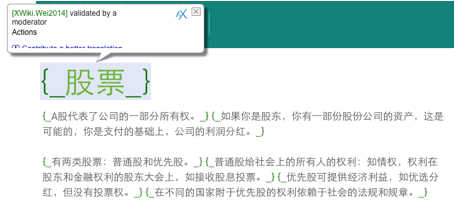
Figure 27 : Comparaison de la traduction de GT et de la post-édition humaine
Les deux post-éditeurs étaient des étudiantes chinoises en informatique à l’Université Joseph Fourier, sans connaissances particulières en économie. Cependant, on voit dans la Figure 27 que les segments post-édités sont très compréhensibles et fidèles.
V.3 Construction de systèmes de TA
V.3.1 Construction de systèmes Moses "ligne de base"
Pour construire des systèmes de TA français-chinois adaptés au domaine économique et boursier, nous avons extrait des segments français-anglais, anglais-chinois à partir de sites Web boursiers et économique. Nous avons ainsi obtenu 2000 segments français-chinois via la post-édition (voir le Tableau 45).
Tableau 45 : Statistiques sur la ressource économique et boursière
|
Paire de langues |
Nb de segments |
Nb de mots |
Nb de mots |
Nb de p_std |
Nb de p_std |
|
anglais-chinois |
3000 |
104K |
128K (caractère chinois) |
416 |
321 |
|
anglais-français |
2000 |
60K |
54K |
241 |
215 |
|
français-chinois (PE) |
2000 |
44K |
46K (caractère chinois) |
176 |
115 |
Dans le cadre du
projet TABE-FC, nous avons d’abord construit deux systèmes de TA (anglais→français et anglais→chinois). Ensuite nous avons traduit les
segments anglais extraits de « Bourse de Paris» vers le chinois, et les
segments anglais extrait de « Shenzhen Stock Exchange (SZSE)[6] » vers le français. Enfin nous avons
construit le système de TA français→chinois en utilisant les segments traduits par les systèmes de TA et les
segments post-édités du français vers le chinois.
V.3.1.1 Système de TA anglais→ français
Nous sommes parti des 2000 segments parallèles anglais-français obtenus à partir du site Web « Bourse de Paris », concernant le domaine boursier et économique. Comme ces données ne sont pas suffisantes pour entraîner un système de TA français→anglais avec Moses, nous avons ajouté aux données d’entraînement 2M bisegments du corpus MultiUN anglais-français.
Le système de TA anglais→français a été utilisé pour traduire les segments anglais (3000 segments) extraits du site Web « SZSE » vers le français.
Enfin, nous avons produit 3000 bisegments français-chinois, et la partie française a été traduite par le système de TA anglais→français.
V.3.1.2 Système de TA anglais→chinois
Pour construire le système de TA anglais→chinois, nous avons pris 3000 segments parallèles anglais→chinois extraits du site Web « SZSE », et nous avons ajouté aux données d’entraînement 2M bisegments du corpus MultiUN anglais-chinois.
Le système de TA anglais→chinois a été utilisé pour traduire les segments anglais extraits du site Web « SZSE » vers le français.
Enfin, nous avons produit 2000 bisegments français-chinois,
et la partie chinoise a été traduite par notre système de TA anglais→chinois
de bonne qualité.
V.3.1.3 Système de TA français→chinois
Nous avons traduit 3000 segments d’anglais en français, et 2000 segments d’anglais en chinois. Plus de 2000 segments ont été post-édités du français vers le chinois. Au total, nous avons obtenu 7000 bisegments français-chinois de bonne qualité.
V.3.1.4 Système de TA chinois→français
Pour l’instant, nous n’avons pas de corpus parallèle de bonne qualité pour entraîner un système de TA du chinois vers le français adapté au domaine économique et boursier, et nous n’avons pas non plus de MT post-éditée du chinois vers le français. Pour tester la traduction français→chinois, nous avons essayé d’utiliser la MT français→chinois « à l’envers ». Mais les résultats, comme on pourrait s’y attendre, sont assez désastreux.
V.3.2 Avancement de l'expérimentation
Pour obtenir plus de segments post-édités, nous avons construit deux nouvelles iMAG pour les sites Web « SIX Swiss Exchange (SIX)[7] » (français→chinois), et « Hong Kong Stock Exchange (HKEx)[8] » (anglais→chinois).
Cette expérience est toujours en cours au moment de la
rédaction. Nous utilisons nos systèmes de TA et post-éditons leurs résultats
sous SECTra_w. Les systèmes de TA sont installés sur un
serveur du laboratoire LIG, et on peut y accéder via Tradoh.
V.3.3 Résultats provisoires
Nous avons commencé à utiliser notre système pour post-éditer les pages Web boursières et économiques des sites « SIX », « HKEx », et « Bourse de Paris ». Pour l’instant, nous n’avons pas encore assez de données pour présenter des statistiques et surtout une évaluation significatives. Nous espérons que nous pourrons fournir cela au moment de la soutenance, et que nous pourrons répondre à trois questions importantes dans ce contexte :
1. La qualité d'usage est-elle suffisante ou non sans intervention humaine ?
2. Le passage par l'anglais est-il une bonne chose (avec ou sans PE de l'anglais) ?
3. Peut-on réduire significativement le temps de recompilation d’un système Moses avec de nouvelle données (bisegments) obtenue par PE.