Chapitre VI Démonstration de l'intérêt de l'apprentissage incrémental en TA statistique
Introduction
Dans l’objectif permanent d’améliorer la qualité de notre système de TA fr-zh, nous avons accumulé des bisegments de bonne qualité par post-édition sur la plate-forme SECTra_w/iMAG. Étant donné la controverse qu’il y avait vers 2012 sur l’utilité de l’apprentissage incrémental pour des systèmes de type Moses, nous avons cherché à monter une expérience pour déterminer les conditions favorables à l’utilisation de cette technique. Cette expérience a été menée en 3 phases. (1) J’ai d’abord construit un système appelé Moses_fr-zh_v0 à partir de 10K bisegments post-édités, et j'ai travaillé seulement sur la MT du LIG-LAB, en post-éditant des segments choisis parmi les 6000 non post-édités, et en faisant des mesures sur des ensembles croissants de segments post-édités. Après 10 itérations d’apprentissage incrémental, les résultats étaient encourageants mais pas encore concluants. (2) Dans le cadre d’un stage d’été, deux étudiants chinois ont travaillé sur la post-édition en chinois d’articles en français et sur des supports de divers cours de Master 1 environ 13000 segments. (3) Enfin, disposant d’environ 30K bisegments de qualité (en fr-zh), nous avons recommencé l’expérience en améliorant son organisation et en l’automatisant.
Au total, nous avons prouvé que l’apprentissage incrémental peut améliorer la qualité de TA fr-zh, en tout cas si l’on vise un « sous-langage », et si de temps en temps, on réentraîne le système en utilisant toutes les données d’entraînement.
VI.1 Contexte
VI.1.1 Motivations
Pour obtenir une bonne qualité avec un modèle de type Moses sur un "sous-langage" précis, on n'a pas besoin de très grandes quantités de données d’entraînement (comme les 200M de bisegments du système généraliste de l'UE), mais il en faut quand même un certain nombre, en fonction de la taille et de la complexité du sous-langage en question. Une expérience précédente a montré que, à l'extrême, on pouvait se contenter de 1000 bisegments dans le cas d'un tout petit sous-langage (SMS de petites annonces en occasion automobile (Daoud, 2007), (Hajlaoui and Boitet, 2008). Dans le cas de notes techniques et de la paire français-anglais, la société L&M est arrivée à des taux de BLEU de l'ordre de 70% avec 300K exemples.
Si l'on s'attaque à un nouveau sous-langage, on n'a pas encore de corpus de bisegments de taille suffisante. On commence donc par utiliser un système généraliste existant, et à post-éditer ses résultats, jusqu'à obtenir une taille suffisante. On entraîne alors son propre système sur un corpus d'entraînement petit mais de bonne qualité, en le mélangeant, si les résultats sont meilleurs, avec une certain quantité de corpus général, et on met ce système en service. Au début, la qualité d'usage, mesurée par exemple par le temps de post-édition, n'est en général pas supérieure à celle d’un système généraliste (comme GT). Mais, si l'on produit de nouvelles versions de « son » système de TA en intégrant aux données d'entraînement les post-éditions qu'il produit sur de nouveaux segments, on y arrive.
Malheureusement, la création d'une nouvelle version consiste à "tout recompiler" et est extrêmement longue (plusieurs dizaines d'heures en temps partagé). Par exemple, on a fait une expérience avec 1,2M bisegments fr-zh sur un serveur à quatre cœurs (Intel i7-3770 CPU 3.40GHz), qui a pris 17~20h pour l’entraînement.
C'est un obstacle majeur à l'accroissement régulier de la qualité. Or, il est très important que les utilisateurs aient l'impression que « le système apprend », et, par exemple, que les contributions qu'ils ont faites dans leur activité de post-édition sont prises en compte
Fin 2011, une possibilité d'apprentissage incrémental venait d'être introduite dans Moses, et L&M m'a demandé de l'étudier, ce que j'ai fait. C'était dans le cadre de la préparation d'une réponse à un appel d'offres, qui n'a pas été obtenu. L&M a alors provisoirement arrêté le travail sur ce point. Pour ma part, je continuais d'être intéressé par cette possibilité, et cela d'autant plus que mes expériences sur les corpus de L&M semblaient prouver que cette technique était prometteuse, même si les gains de qualité étaient nettement plus faibles que si l’on "recompilait tout", et aussi parce qu'il y avait dans le domaine diverses polémiques, l'une sur l'utilité potentielle de l'apprentissage incrémental dans Moses, et l'autre sur l'intérêt pour les traducteurs de post-éditer des résultats de TA. J’avais en particulier lu un article mettant en doute l’utilité de cette technique (Mirkin, 2014).
Je me suis donc demandé comment je pourrais démontrer l'utilité de cette technique, et ce thème est devenu assez important dans ma recherche. J’ai expérimenté cette technique pour la première fois dans le cadre de la création d’un corpus bilingue français-chinois dans le domaine de l’énergie (voir IV.3.3).
J’avais aussi constaté que les améliorations obtenues en ajoutant des « mini-batch » et en exécutant l’AI tendaient à diminuer avec le temps, et étaient toujours bien inférieures aux améliorations obtenues par un réentraînement complet.
Comme L&M a abandonné ce projet, n’ayant pas obtenu le contrat espéré avec EDF, j’ai poursuivi cette recherche dans le cadre du laboratoire, en prenant comme base expérimentale le site du LIG, pour lequel nous avions déjà une MT 8000 segments dont 2000 post-édités.
VI.1.2 Expérience sur le site du LIG
VI.1.2.1 Motivations et conditions expérimentales
Pourquoi le site du LIG ? Le site Web LIG-Lab[1] est le
site Web officiel du laboratoire LIG (Laboratoire d’Informatique de Grenoble). Le
LIG rassemble près de 500
chercheurs, enseignants-chercheurs, doctorants et personnels en support à la
recherche. C’est aussi le tout premier site Web pour lequel une iMAG a été créée (voir VI.1.2.1.2). Un certain nombre de
chercheurs, doctorants, ou stagiaires sont chinois, et ils souhaitent accéder notre
site Web traduit en chinois.
Sous-langage envisagé. Le site
Web du LIG contient la présentation du laboratoire, la présentation de ses 22
équipes de recherche, ses contributions du développement des aspects
fondamentaux de la discipline (modèles, langages, méthodes, algorithmes) et les
événements du laboratoire. Tous les contenus tournent autour de l’informatique.
Une instance d’iMAG existe depuis fin 2008 et
est dédiée à ce site, ou plutôt à son sous-langage.
Pré-condition de l’expérience. La
Figure
28 montre la page d’accueil
de cette iMAG dédiée (LIG-LAB) accédée
en chinois. La langue source est le français, et il y a 34 langues d’accès
possibles. Notre expérience porte sur la paire de langues français-chinois. L’iMAG du LIG contenait environ 8K
segments français (en février 2013), et environ 2K segments avaient été
post-édités.

Figure 28 : Site du LIG vu en chinois à travers une iMAG
VI.2 Expérimentation
VI.2.1 Phase 1 (2-6/2013)
VI.2.1.1 Expérience sur le site du LIG
Notre corpus
d'apprentissage initial a été construit en choisissant dans SECTra deux parties
tirées de deux MT différentes : une partie provenait de la MT de LIG-LAB[2], qui avait au total 8000 segments en
français, dont 2000 étaient déjà post-édités de français en chinois. L'autre
partie provenait de la MT demo2[3], qui avait été créée en 2012, et qui contenait
8000 segments post-édités de français en chinois. Ces 10K bisegments
post-édités ont été utilisés pour
créer la version initiale de notre système Moses français-chinois dédié au
sous-langage du LIG. Nous l’avons appelée Moses-LIG-fr-zh-V0 (Tableau
46).
Tableau 46 : Statistiques sur les données d'entraînement de la phase 1
|
|
Nb
de bisegments |
Nb
de mots |
Pages
standard |
Caractères |
Pages
standard |
|
Moses V0 (initial) |
10724 |
160K |
644 |
182K |
455 |
Dans l’expérience,
nous avons travaillé seulement sur la MT du LIG-LAB, en post-éditant des
segments choisis parmi les 6000 non post-édités, et en faisant les mesures sur
les ensembles croissants de segments post-édités.
Nous utilisons les
termes et les notations suivants.
·
Page standard : texte contenant 250 mots (1400 caractères)
en français, ou 400 caractères en chinois.
·
Segment : unité de post-édition (phrase ou un titre).
·
Page logique : page Web générée par SECTra_w pour
l’interface de PE et contenant N segments. La valeur par défaut est N=20.
· MT_LIG : MT de LIG-LAB.
· MT_INC : nouvelle partie de MT à extraire pour l'apprentissage incrémental.
· NewPE : ensemble des nouveaux segments post-édités.
·
Moses-LIG-fr-zh-VN : N-ième version de Moses-LIG-fr-zh (après N
mises à jour de Moses-LIG).
·
Moses_INC : opération d'apprentissage incrémental.
·
SEG[i] : segment VI.
·
SEGPE[i] : post-édition du segment i.
·
ApplyPE (Moses-LIGN, SEG[i]) : post-édition du segment i à partir de sa TA
par Moses-LIGN.
Dans cette expérience, j’ai post-édité
les segments non post-édités, par
pages logiques. SECTra note le temps de post-édition primaire (Tpe_1)[4] pour chaque segment. Lorsque 10
pages logiques (200 segments) ont été post-éditées, on les utilise pour mettre à jour Moses-LIG-fr-zh (de VN
à VN+1). Nous répétons cela
10 fois de suite (2000 segments), et mesurons le temps moyen de post-édition.
Enfin, nous utilisons les segments source du site LIG, leurs post-éditions à
partir de la MT de LIG-LAB, et les traductions par Moses-LIG-fr-zh de V1
à V10 pour évaluer la performance de chaque Moses-LIG-fr-zh-VN
par BLEU (Papineni, Roukos et al., 2002), NIST (Doddington, 2002) et par TER (Snover et al., 2009).
Il y a finalement 3 opérations essentielles
Opération 1 : post-édition
des segments non post-édités, traduits par Moses-LIG-fr-zh-VN.
SEGPE[i] := ApplyPE (Moses-LIG-fr-zh-VN,
SEG[i]) si SEGPE[i]![]() MT_LIG_PE
MT_LIG_PE
Opération 2 : apprentissage incrémental de Moses-LIG N+1.
MT_INCR:= Extraire (NewPE,
Niveau, Score) NewPE ![]() MT_LIG
MT_LIG
Moses-LIG-fr-zh-VN+1
:= Moses_INCR (Moses-LIG-fr-zh-VN, MT_INCR);
Opération 3 :
mesures (Voir VI.2.1.3).
VI.2.1.2 Processus d'AI
À l'itération N du
processus, tous les segments de la MT sont traduits par la version N du TA
(Moses-VN), y compris, de façon continue, les nouveaux segments
créés par le site. Certains segments non encore post-édités sont post-édités à
cette itération (de façon opportuniste ou organisée).
Quand on a un certain nombre de nouveaux segments post-édités, jugé "bons" (200 dans notre expérience), on les traite (séparation des mots, nettoyage, traitement de la casse (truecasing), alignement, etc.), et on les ajoute à la table de traductions.
Moses-VN est mis à jour vers Moses-VN+1. À la fin de l'itération N, on met en
service Moses-VN+1, et on lui fait traduire tous les segments,
post-édités ou non. Cela permet de mesurer la différence de qualité sur la
partie déjà post-éditée. On passe alors à l'itération N+1. On obtient ainsi une
suite de versions du STA (Moses-V1, ..., Moses-VN,
Moses-VN+1, ...), qui ne s'arrête (en usage) que quand tous les
segments sont post-édités et qu'il n'en reste pas assez de "bons"
pour procéder à l'itération suivante.
VI.2.1.3
Résultats
VI.2.1.3.1 Évolution du temps de post-édition
Ces temps
sont ceux mesurés par SECTra_w. Le temps moyen de
post-édition (PE), pour chaque nouvel ensemble de 200 segments, diminue à
chaque itération. Après la dixième, le temps moyen de PE par page standard (de
250 mots) a été réduit de 3,8 minutes sur 30,7 au départ, soit 12,4%. Si on le
compare avec le temps de PE en partant de résultats de GT, on voit qu’il s’en rapproche. La forme de la courbe faisait penser (à la
fin de cette phase 1 de l’expérience) qu'il passerait dessous après environ 30
itérations.
Tableau 47 : Évaluation du temps de post-édition (2-6/2013)
|
|
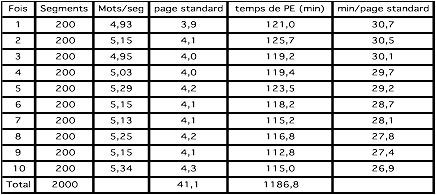
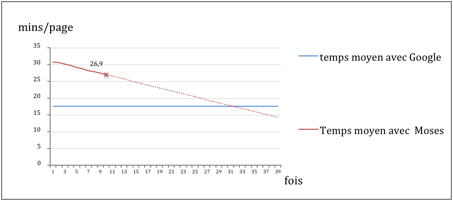
Figure 29 : Diminution de temps moyen de PE (par page standard) avec AI dans la phase 1 de l'expérience
VI.2.1.3.2 Évaluations basées sur des références
On a M segments post-édités, et on a la nouvelle version N de Moses-LIG. On traduit tous les segments avec elle, et on mesure BLEU, NIST et TER sur :
· Origine (OR) : les M segments post-édités.
· Nouveau (NV) : les 200 segments
nouvellement post-édités.
· Tout (TT): tout ce qui a été
post-édité.
Tableau 48 : Évaluations basées sur des références (BLEU, NIST, TER)
|
|
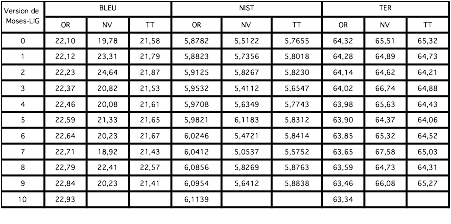
À la 10ième itération, il n’y avait pas de segments post-édités (assez bons). Au début de la Nième itération, M=2000+200*N, TT=2000+200*(N+1).
Conclusion
Nous avons fait une
première expérience sur l'évaluation et l'amélioration incrémentale de la TA,
réalisée avec le système Moses, basé sur SECTra_w et Moses-LIG. Les résultats des mesures montrent que la
méthode d'apprentissage incrémental
permet de réduire le temps de post-édition de 12,4% en 10 itérations, et
d'améliorer les mesures basées sur les références (BLEU :
![]() 0,83, NIST :
0,83, NIST : ![]() 0,2357, TER :
0,2357, TER : ![]() 0,98).
0,98).
VI.2.2
Phase 2 (7-9/2013)
VI.2.2.1 PE par deux étudiants chinois dans le cadre d'un stage d’été (Wu Jiang et Chen Shi)
Wu Jiang et Chen Shi étaient deux étudiants chinois de l'UJF
qui, en juin 2013, étaient en fin de leur 1ère année de master en informatique.
Ils ont fait un stage d’été en binôme au laboratoire, durant lequel ils ont
fait de la post-édition sur des textes et sur des supports de divers cours de Master
1, du français vers le chinois.
Ils ont travaillé sur 2 iMAG dédiées. (1) « Corpus par jour » [5] est un site Web que j’avais créé pour récupérer des ressources français-chinois. J’ai sélectionné des textes en français à partir de sites de journaux Le Monde et 20 minutes. Je les ai mis en format html, et les ai ajoutés dans mon site Web. La Figure 30 montre une capture d’écran de post-édition sur l’iMAG associée.
|
|

Figure 30 : Capture d'écran de l'iMAG « Corpus par jour »
À la fin de cette période (04/07/2013-13/09/2013), nous avions post-édité 21 articles français. La statistique est présentée dans le Tableau 49.
Tableau 49 : Statistiques de post-édition sur 21 articles français 4/7-13/9/2013
|
Nb de doc |
Segments |
Mots |
Mots/seg |
Page_std |
Temps |
Temps/page_std en sec. |
|
21 |
4775 |
115564 |
24,20 |
462,26 |
159408 |
344,85 |
(2) « MACAU » [6],
Cette iMAG a été créée dans le cadre du projet MACAU-OFI.
Elle permet aux étudiants étrangers de l’UJF d’accéder dans leur langue à des supports
pédagogiques, par l’amélioration contributive des "pré-traductions" obtenue
par TA (Figure
31).
(Voir la présentation de MACAU au III.2.3).
|
|
Figure 31 : Capture d'écran de Chamilo affichant le lien AXiMAG
En septembre 2013, nous avons post-édité les supports de cours de l’UJF comme « Complexité en M1 », « IHM en M1», « Logique en L2 », etc. Le Tableau 50 donne la statistique de post-édition sur les supports de cours.
Tableau 50 : Statistiques de post-édition sur les supports de cours
|
Nb de doc |
Segments |
Mots |
Mots/seg |
page_std |
Temps en
sec. |
Temps/page_std
(calculé) |
|
236 |
16069 |
136573 |
8,50 |
546,29 |
412784 |
755,61s =12,6 mn |
VI.2.2.2 Processus d'AI
Dans cette phase,
nous utilisons la méthode présentée au IV.3.4 pour construire notre système. Tout
d’abord, nous utilisons le système de TA français→chinois, qui est entraîné dans la phase 1, comme système de base
(« baseline »). Les
nouveaux segments post-édités sont utilisés pour entraîner la nouvelle partie
de TA. Les paramètres sont les même que ceux de la phase I.
Après la construction
du système de TA français→chinois
avec tous les segments post-édités (Phase I + Phase II)[7], nous avons fait une expérimentation pour
comparer le temps de post-édition parmi les différentes des système de TA dans
le cadre d’un stage M1 TER.
VI.2.2.3 Résultats
Pour évaluer notre système de TA, nous avons choisi 50 segments à partir du site Web du LIG en langue
française, et un étudiant chinois a ensuite post-édité les prétraductions produites
par GT et MosesLIG
français-chinois (100 observations) dans SECTra_w. En fait, dans cette situation, nous ne
pouvons pas analyser directement le ![]() ,
parce que, pour chacune des prétraductions, le segment source est le même, et
le temps de recherche lexicale (l’essentiel de
,
parce que, pour chacune des prétraductions, le segment source est le même, et
le temps de recherche lexicale (l’essentiel de ![]() )
est souvent passé sur la première prétraduction. Néanmoins, nous pouvons
analyser le
)
est souvent passé sur la première prétraduction. Néanmoins, nous pouvons
analyser le ![]() qui est fortement corrélé avec le
qui est fortement corrélé avec le ![]() .
.
VI.2.2.3.1 Évolution
du temps de post-édition
Dans le Tableau 51, le nombre moyen de mots par segment des
prétraductions de MosesLIG est presque le même qu’avec GT. Nous pouvons
constater que, pour post-éditer un segment prétraduit, le ![]() moyen de MosesLIG est
inférieur à celui de GT.
moyen de MosesLIG est
inférieur à celui de GT.
Tableau 51 : Résultat de l’expérimentation (en français-chinois)
|
Nb
moyen de mots |
Nb
moyen de mots |
|
|
|
|
MosesLIG |
26 |
25,4 |
23,4 s |
6,1 mn |
|
|
26 |
27,1 |
25,3 s |
6,3 mn |
VI.2.2.3.2 Conclusions provisoires
Dans la phase 2, nous n’avons pas fait l’AI comme dans la phase 1, mais nous avons réentraîné notre système de TA français-chinois avec une plus grosse MT. Notre expérimentation a produit un bon résultat. Du point de vue du temps de post-édition, le résultat est claire : notre système est maintenant un peu meilleur que GT.
VI.2.3 Phase 3 (9-12/14 et 7-11/15)
VI.2.3.1 Motivation
Dans la phase 1, nous avons fait le premier essaie de l’AI, et nous avons obtenu un résultat encourageant. Mais notre système de TA était limité par la quantité de segments post-édités, et la longueur moyenne du segments (7 ou 9 mots).
Dans la phase 2, nous n’avons pas pu faire d’AI. Nous avons réentraîné notre système avec une grande MT français-chinois, mais cela ne prouve pas que notre méthode (AI) peut améliorer le système de TA, mais ne permet pas non plus de trouver le point de « réentrainement du système ». Nous voulions donc refaire notre expérimentation pour répondre nos « doutes ».
VI.2.3.2 Poursuite de l'expérience en français-chinois sur le site du LIG
Dans cette phase,
nous avons exporté tous les segments post-édités de SECTra_w. Dans le Tableau 52, nous montrons la quantité de segments
post-édités.
Tableau 52 : Nombre de segments dans chaque MT
|
Nom du corpus / de la MT |
Quantité de segments PE |
|
Demo2 |
28K |
|
MT_INC |
7K |
|
MT_Macau |
16K |
|
MT_TED |
14K |
|
MT_énergie |
9K |
Préparation des données. Nous avons mélangé toutes les données, environ 80K bisegments, puis nous les avons nettoyées et les avons séparées en 16 parties. Chaque partie contient 5000 segments. Les statistiques sur les données nettoyées sont données dans le Tableau 53.
Conception de l’expérience. Nous avons fait 16 itérations. Le processus de l’AI a été présenté dans le VI.2.2.2. Le système Moses-LIG V0 a été construit avec 100K bisegments extraits à partir du corpus MultiUN.
Tableau 53 : Statistiques sur les données pour l'AI (phase 3 de l’expérience)
|
Incrémental |
Longueur moyenne de segment (source) |
Longueur moyenne de segment (cible) |
Nombre de mots (source) |
Nombre de caractères chinois |
Pages standard (source) |
Pages standard (cible) |
|
Base (MultiUN) |
52,7 |
41,8 |
263 K |
209 K |
1 054
|
522,50
|
|
1 |
42,9 |
27,3 |
214 K |
136 K
|
858 |
341,25
|
|
2 |
43,3 |
26,7 |
216 K
|
133 K
|
866 |
333,75
|
|
3 |
39,6 |
25,3 |
198 K |
126 K
|
792 |
316,25
|
|
4 |
34,5 |
23,3 |
172 K
|
116 K
|
690 |
291,25
|
|
5 |
31,7 |
22,3 |
158 K |
111 K
|
634 |
278,75
|
|
6 |
30,1 |
21,9 |
150 K |
109 K
|
602 |
273,75
|
|
7 |
28,8 |
21,5 |
144 K |
107 K
|
576 |
268,75
|
|
8 |
27,7 |
21,1 |
138 K |
105 K
|
554 |
263,75
|
|
9 |
27,1 |
20,9 |
135 K |
104 K
|
542 |
261,25
|
|
10 |
26,5 |
20,7 |
132 K
|
103 K
|
530 |
258,75
|
|
11 |
25,9 |
20,5 |
129 K |
102 K
|
518 |
256,25
|
|
12 |
25,5 |
20,4 |
127 K
|
102 K
|
510 |
255,00
|
|
13 |
25,1 |
20,2 |
125 K
|
101 K
|
502 |
252,50
|
|
14 |
24,8 |
20,1 |
124 K
|
100 K
|
496 |
251,25
|
|
15 |
23,6 |
19,2 |
118 K
|
96 K
|
472 |
240,00
|
|
16 |
22,3 |
19,1 |
111 K
|
95 K
|
446 |
238,75
|
|
Au total |
Longueur moyenne de segment |
Longueur moyenne de segment |
Nombre de mots
(source) |
Nombre de caractère chinois (cible) |
Pages standard (source) |
Pages standard (cible) |
|
|
31,3 |
23,1 |
2 660 K |
1 961 K |
10 642,00 |
4 903,75 |
VI.2.3.3 Résultats
VI.2.3.3.1 Évolution du temps de post-édition
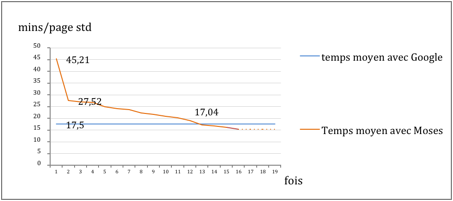
Pour évaluer le temps de post-édition, nous continuons à post-éditer les nouveaux segments sur l’iMAG LIG-LAB comme nous l’avons présenté au VI.2.1.3.1. Les segments sont sélectionnés dans la MT LIG-LAB. Nous avons filtré sur la longueur, et supprimé les segments très courts.
Tableau 54 : Évaluation du temps de post-édition (9-12/2014)
Figure 32 : Diminution du temps moyen de PE (par page) avec AI dans la phase 3 de l'expérience |
VI.2.3.3.2 Évaluations basées sur des références
Pour évaluer notre système de TA VN, nous avons choisi 500 bisegments à partir des données d’entraînement VN+1 comme données de test. Par exemple, nous avons fait l’AI avec les données « Incrémental 10 », et choisi 500 bisegments des données d’entraînement « Incrémental 11 » pour évaluer notre système. Les statistiques sur les données de test et le score BLEU sont données dans le Tableau 55.
Tableau 55 : Données de test et scores BLEU
|
|
Longueur moyenne de segment (source) |
Longueur moyenne de segment (cible) |
Longueur moyenne de segment (résultat) |
Nombre de mots (source) |
Nombre de caractère |
Nombre de caractère |
Pages standard (source) |
Pages standard (ref) |
Pages standard (résultat) |
BLEU |
|
Eval1 |
37,2 |
24,8 |
23,1 |
18612 |
12406 |
11544 |
74,4 |
31,0 |
28,9 |
0,1382 |
|
Eval2 |
40,6 |
25,8 |
27,6 |
20309 |
12912 |
13817 |
81,2 |
32,3 |
34,5 |
0,1428 |
|
Eval3 |
20,2 |
18,5 |
15,9 |
10098 |
9244 |
7974 |
40,4 |
23,1 |
19,9 |
0,1603 |
|
Eval4 |
20,7 |
18,3 |
16,3 |
10336 |
9141 |
8141 |
41,3 |
22,9 |
20,4 |
0,2357 |
|
Eval5 |
25,4 |
22,9 |
20,3 |
12687 |
11462 |
10165 |
50,7 |
28,7 |
25,4 |
0,2823 |
|
Eval6 |
19,1 |
17,3 |
15,4 |
9541 |
8646 |
7692 |
38,2 |
21,6 |
19,2 |
0,3346 |
|
Eval7 |
23,1 |
21,0 |
18,7 |
11543 |
10518 |
9356 |
46,2 |
26,3 |
23,4 |
0,3770 |
|
Eval8 |
20,7 |
19,3 |
17,2 |
10364 |
9651 |
8582 |
41,5 |
24,1 |
21,5 |
0,4285 |
|
Eval9 |
19,5 |
17,5 |
15,8 |
9725 |
8766 |
7901 |
38,9 |
21,9 |
19,8 |
0,4331 |
|
Eval10 |
21,8 |
19,8 |
17,8 |
10899 |
9921 |
8897 |
43,6 |
24,8 |
22,2 |
0,4597 |
|
Eval11 |
20,5 |
18,4 |
16,9 |
10248 |
9194 |
8459 |
41,0 |
23,0 |
21,1 |
0,4682 |
|
Eval12 |
23,0 |
20,5 |
18,5 |
11501 |
10251 |
9260 |
46,0 |
25,6 |
23,2 |
0,4694 |
|
Eval13 |
21,9 |
20,0 |
17,9 |
10973 |
10004 |
8964 |
43,9 |
25,0 |
22,4 |
0,4734 |
|
Eval14 |
14,5 |
13,0 |
11,3 |
7242 |
6481 |
5655 |
29,0 |
16,2 |
14,1 |
0,4792 |
|
Eval15 |
16,2 |
17,4 |
17,2 |
8107 |
8734 |
8622 |
32,4 |
21,8 |
21,6 |
0,4831 |
VI.3
Analyse des résultats
Après 16 itérations, les résultats des mesures montrent que la méthode d'apprentissage incrémental permet de réduire le temps de post-édition et d'améliorer les mesures basées sur les références (BLEU).
La V0 de notre système avait été entraînée sur le corpus MultiUN, et ce système trop généraliste ne pouvait pas nous donner une bonne qualité de traduction. Avec 45mn/ page_std, on avait en effet Q=10%=2/20.
Cependant en l’utilisant comme point de d épart, grâce à l’AI, nous sommes arrivé assez rapidement (16 itérations et environ 90h de calcul pour l’AI, sans jamais tout recompiler) à un système de bonne qualité (avec 15mn/page_std de PE en moyenne, notre formule donne Q=70%=14/20).
Les temps de PE primaire (Tpe_1) et les scores BLEU sont donnés dans le Tableau 54 et dans le Tableau 55.