Chapitre VIII Mise à disposition de ressources
Dans le cadre de ma thèse, je me suis aussi attaché à mettre à disposition de la communauté des chercheurs les ressources et outils que j’ai développés, sous des formes « statiques » ou « dynamiques ».
Les ressources et outils « statiques » sont mis à disposition sous forme de fichiers téléchargeables.
La mise à disposition dynamique consiste à proposer des serveurs Web d’utilisation de systèmes de TA et de post-édition collaborative de MT associées à des sites Web, via les iMAG associées.
Nos ressources « statiques » sont particulièrement
intéressantes à cause de leur taille, et parce qu’elles sont utilisables pour construire
on expérimenter des système de TA.
Nous avons mis à disposition des corpus multilingues post-édités dans des formats usuels comme TXT et XML. Ces formats sont bien adaptés aux systèmes existants : les segments source et les segments post-édités sont alignés, et sauvegardés dans deux fichiers TXT. Ils sont utilisables directement par les boîtes à outils comme Moses et Joshua pour entraîner des systèmes de TA. Le format XML peut être importé dans plusieurs plates-formes comme Déjà Vu, MemoQ, SDL Trados, etc.
Une grande partie de ces ressources statiques a été construite en utilisant la plate-forme SECTra_w/iMAG. Les segments post-édités sont munis de l’information associée, comme le temps de PE, le système de TA initial, la référence, etc. L’utilisateur en a besoin pour certains travaux, l’évaluation de systèmes de TA, par exemple.
Les MT tirées de la collection de brevets CLEF-IP sont les plus grosses (17,5M segments en fr-de-en). Suivent les MT fr-zh : 9000 pour le sous-langage d’EDF, 15000 pour celui du LIG, 23000 pour les documents pédagogiques de MACAU-UJF, et 10000 pour le roman de Jules Verne « Voyage au centre de la Terre ».
Les systèmes de TA téléchargeables sont ceux déduits de CLEF-IP (fr-de, de-fr, fr-en) et quelques variantes de notre système fr-zh MosesLIG-fr-zh.
Les services Web en ligne sont ceux des quelques iMAG parmi lesquelles deux servent actuellement à construire
de bonnes MT du français vers le somali et vers le comorien.
VIII.1 Contribution de ressources statiques sous forme de MT
VIII.1.1 Formats choisis
Nous avons choisi 2 types de format pour sauvegarder et partager nos mémoires de traduction, nous avons choisi 2 formats documentaires, TXT et XML.
TXT est le format plus utilisable pour l’apprentissage du système de TA. La boite à l’outil, comme Moses et Joshua, ils supportent des données en format txt (raw text) à entrainer les modèle. Figure 46 présente un exemple de la MT aligné CLEF-IP anglais-français. Voir l’exemple avec 100 bisegments anglais-français dans l’Annexe 11.
|
|
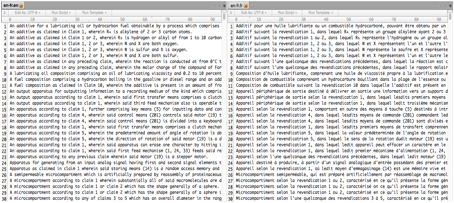
Figure 46 : Exemple des données en format TXT (MT CLEF-IP anglais-français)
Pour adapter aux système de l’aide de traduction comme SDL Trados et MemoQ, nous avons choisi le format XML (fichier TMX ou fichier XML avec fichier accompagne) pour partager ces données (Figure 47). Voir l’exemple avec 20 bisegments anglais-français en format TMX dans l’Annexe 13.
|
|
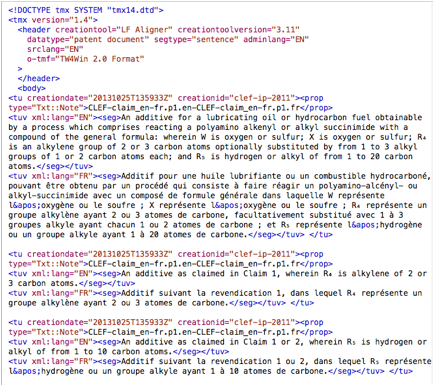
Figure 47 : Exemple des données en format TMX (MT CLEF-IP anglais-français)
VIII.1.2
Méthode de création
Nous avons construit les ressources statiques en utilisant 2
méthodes. Grâce à
SECTra_w, qui offre un système d'annotation de chaque traduction ou
post-édition d'un segment par un niveau de fiabilité (de * à *****) et un score
(de 0 à 20), il est possible d'extraire de la mémoire de traductions, associée
à un site Web, une sous-MT vérifiant n'importe quel prédicat basé sur les
niveaux et les scores. Le résultat de post-édition peut être exporté en format
XML et TXT. Nous avons choisi les segments post-édités de haute qualité (par
les critères de SECTra).
L'exemple suivant montre une extraction à partir de la partie français-chinois de la MT-demo2 associée à la iMAG-Doc_Par_Jour. Le prédicat est tout simplement [Level = 3 & score> = 13], et ses paramètres peuvent être modifiés directement via l'interface graphique.
|
|
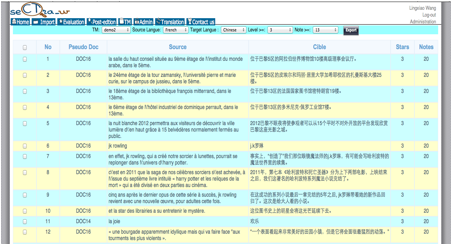
Figure 48 : Extraction d'une "bonne" MT de
la MT produite par post-édition "naturelle"
Avec l’autre méthode, nous récupérons d’abord les documents multilingues comme le corpus
CLEF-IP 2011, et analysons les documents.
Ensuite, nous extrayons
les segments parallèles, et les nettoyons.
Dans un troisième
temps, nous les alignons et les mettons en format TXT et TMX.
VIII.1.3 Résultats
Après les 4 premières années d'utilisation
(09/2011-09/2015), il y avait environ 80 sites Web accédés par des iMAG. Il y en a maintenant plus de 200. Les sites visités ont
plus de 8 langues comme langue source,
et plus de 10 langues comme langue cible avec de la post-édition. Il y a plus
de 820.000 segments, et environ
45% (370.000+) des segments ont été post-édités par des contributeurs
(payés ou non, organisés ou occasionnels). La plupart des segments parallèles sont en anglais-français, en
anglais-chinois, et en français-chinois.
Voici quelques données chiffrées.
Dans le Tableau 58, on donne la longueur du texte source des segments post-édités, le balisage XML personnalisé est supprimé, et on compte le nombre de caractères chinois pour le chinois.
Tableau 58 : Segments post-édités dans SECTra_w à partir de 3 langues source
|
Langue |
Phrase |
Mots |
|
anglais |
350 174 |
5 252 610 |
|
français |
55 642 |
834 621 |
|
chinois |
270 108 |
3 241 296 |
Le Tableau 59 présente les segments post-édités avec la
direction de post-édition et la taille de la MT.
Tableau 59 : Segments parallèles obtenus à partir des MT (mêmes remarques)
|
Paire de
langues (L1®L2) |
Phrase |
Mots L1 (ou
caractères) |
Mots L2 (ou caractères) |
Taille L1 |
Taille L2 |
|
anglais®français |
121 074 |
2 542 731 9 685,9 pages |
2 613 351 9862,1 pages |
10,1Mo |
10,4Mo |
|
anglais®chinois |
208 106 |
4 370 530 16 648,5 pages |
6 063 942 151 159,8 pages |
19,1Mo |
17,6Mo |
|
français®anglais |
29 079 |
627 661 2 326,3 pages |
610 098 2 210,1 pages |
4Mo |
3,9Mo |
|
français®chinois |
10 890 |
228 703 871,2 pages |
317 322 793,3 pages |
1,5Mo |
1,25Mo |
|
chinois®anglais |
2 013 |
58 656 146,6 pages |
42 275 161,1 pages |
240Ko |
263Ko |
|
chinois →français |
10 062 |
291 192 727,9 page |
211 185 804,7 page |
874Ko |
1Mo |
|
|
VIII.1.3.1 Français-chinois pour l'énergie
Dans le cadre de ma thèse, j’ai travaillé sur la construction d’un système de TA français→chinois pour un client potentiel de L&M. J’ai collecté la ressource française concernant le domaine de l’énergie, et puis nous l’avons post-éditée en chinois à l’aide de GT. La Figure 49 affiche 2 fichiers TXT exportés de SECTra. Le fichier en haut est celui des segments source, le fichier du bas est celui des segments post-édités.
|
|
|
|


Figure 49 : Segments post-édités pour la ressource énergie
Il y a environ 10K
segments français, que nous divisons en 500 pages Web. Après la post-édition, nous avons récupéré 9000 segments français→chinois (Tableau 61).
Tableau 61 : Statistique des données pour la ressource énergie
|
|
Nb de segments |
Longueur moyenne |
Nb de mot |
Page_std |
|
français |
9000 |
41 |
368K |
263 |
|
chinois |
9000 |
36 |
324K |
810 |
VIII.2 Contribution sous forme de système de TA
Il s’agit soit de systèmes téléchargables, soit de système utilisables comme des services Web.
VIII.2.1 Systèmes de TA téléchargeables
Nous les avons mis à l’url http://…. Il s’agit des systèmes créés en français-chinois et des systèmes créés à partir de la collection de brevets CLEF-IP 2011.
Tableau 62 : Systèmes de TA téléchargeables
|
Nom du système de TA |
Langues |
Ressources utilisées |
Commentaire |
|
Moses-L&M |
fr-zh |
MT de 9000 segments |
Qualité assez basse |
|
Moses-LIG |
fr-zh |
MT de 80K segments
PE |
|
|
Moses-CLEF-IP |
fr-de |
|
Très bien sur les parties de brevets BLEU : |
VIII.2.2 Systèmes de TA utilisables comme des service Web
Certains des systèmes précédents sont des services Web utilisables directement via l’API de Tradoh, ou la plate-forme JianDan-eval. Certains sites Web boursiers et économiques sont aussi utilisables via une iMAG, ce qui permet l’amélioration par AI.
Tableau 63 : Systèmes de TA utilisables comme des services Web
|
Nom du système de TA |
Langues |
Ressources utilisées |
Commentaire |
|
Moses-L&M |
fr-zh |
MT de 9000 segments |
Qualité assez basse |
|
Moses-LIG |
fr-zh |
MT de 80K segments
PE |
|
|
Moses-CLEF-IP |
fr-de |
|
Très bien sur les parties de brevets |
VIII.3 Passerelles iMAG vers des sites Web statiques ou dynamiques
Une ressource de ce type est simplement une iMAG-S dédiée à un site Web S. La MT associée peut être propre ou partagée, cela n’a pas d’importance pour les visiteurs. Nous distinguons les sites accédés S selon qu’ils sont statiques ou dynamiques.
VIII.3.1 Passerelles iMAG pour des sites statiques
Il s’agit essentiellement de sites contenant des documents mis sous forme html, et pour lesquels on vise à obtenir une assez bonne qualité de traduction.
Tableau 64 : Passerelles iMAG pour des sites statiques
|
iMAG |
Documents accédés |
Commentaires |
|
BemBook |
Le BemBook (de
livre 700 p.) |
Post-édité vers le français de façon occasionnelle Expérimentation organisée pour PE du chapitre 21 en 7~8 langues. |
|
Corpus par jour |
« Voyage au
centre de la terre » |
Post-édition de ce roman du français vers le chinois |
|
Manchanda |
« IITB : Monastery, Sanctuary, Laboratory » |
Préparé pour la PE vers français et hindi |
|
Macau |
Support de cours |
Pour les étudiants étrangers |
|
Powers |
« The book of me » de Powers |
Expérimentation de L. Besacier |
|
CLEF-IP |
Corpus de brevets « CLEF-IP 2011 » |
PE inutile pour les langues de la collection, mais possible vers le chinois |
VIII.3.2 Passerelles iMAG pour des sites dynamiques
Il s’agit ici de sites dont certaines pages changent régulièrement, par exemple celles des nouvelles dans des sites Web d’organismes ou de firmes.
Il y a aussi des sites de journaux, utilisés pour la construction de ressources (corpus parallèles, dictionnaires bilingues) utilisables pour construire ensuite des systèmes de TA (empiriques ou experts ou les deux) vers des langues peu dotées. C’est le cas des iMAG créées pour la Nation de Djibouti (thèse sur le somali) et pour La Gazette des Comores et Al-Watwan (thèse sur le comorien et plus particulièrement le shingazidja) visant à créer un système de lecture active de textes administratifs et juridiques écrits en français (appris à l’école) à l’intention des Comoriens qui parlent presque toujours le comorien en fait.
Tableau 65 : iMAG pour des sites dynamiques
|
iMAG |
sites accédés |
Commentaires |
|
LIG-LAB |
Site Web du LIG |
Post-édité vers le chinois (avec expérimentation) et l’anglais. Un peu vers l’allemand. |
|
lanationdedjibouti |
Site Web du journal La Nation de Djibouti. Environ 500 nouveaux segments par jour, 3 dernières années en ligne. |
Construction par PE (à partir des résultats de GT) d’une bonne MT français-somali. But : créer un système de TA Moses meilleure que GT pour d’accéder à ce journal. |
|
lametro |
Site Web de La Métro à Grenoble |
Site de La Métro. Gros travail (fr→zh/en) en 2010. |
|
alwatwan |
Sites Web des 2 journeaux Al-Watwan et La Gazette des Comores |
Construction par PE à partir des traductions en wahili de GT d’une bonne MT français-comorien |
VIII.3.3 Structure d'une contribution « dynamique » par iMAG
Il s’agit ici d’iMAG dédiées à des sites Web dynamiques. Les utilisateurs post-éditent le contexte sur SECTra_w/iMAG. Les segments post-édités sont sauvegardés dans les MT.
Il y a 2 types de sites Web dynamiques. (1) Un site Web (par exemple le site Web lamétro[1]) met à jour son contexte en temps réel. Pendant que nous accédons son iMAG dédiée dans une langue cible, nous choisissons les phrases intéressantes, et les post-éditons. Un segment peut être post-édité (vers une ou plusieurs langues) par un ou plusieurs post-éditeurs, donc chaque segment source peut avoir plusieurs versions de segments post-édités. Quand nous avons un certain nombre de segments post-édités, nous les exportons pour construire la MT. (2) Nous collectons des ressources spécifiques pour construire une MT adaptée au sous-langage. Tout d’abord, nous récupérons les textes, et les nettoyons. Ensuite nous les mettons en format HTML (Figure 50). Enfin, nous les ajoutons dans SECTra_w/iMAG.
|
|

Figure 50 : Exemple de contribution au format HTML (Chapitre 1 : Voyage au centre de la Terre)
VIII.3.4 Remarques sur la création de certains des sites « contribués »
Certaines de ces contributions ont demandé des travaux de préparation spécifiques.
VIII.3.4.1 La Métro
Le site Web de La Métro de Grenoble contient 2500 pages Web, soit environ 30000 segments. Plus de la moitié ont été post-édités en chinois pour l'Exposition universelle de Shanghai en 2010. Nous avons créé un système français-chinois spécifique en choisissant une partie "assez bonne" de cette MT du 26/06/2015 au 30/06/2015 par la sélection:
TM-lametro-extract-good = TM_select (lametro, [level=3 & score >=13 | level=4 & score >=13 | level=5 & score >=11.5], [langage_pair=fr-zh | langage_pair=fr-en | langage_pair=zh-fr], [Begin_date : 20150626, End_date : 20150630]).
VIII.3.4.2 MUMIA-CLEF
Avce Huanan Sun (M1-TER), nous avons construit 3 sites Web monolingues pour le corpus CLEF-IP. Chaque site Web contient environ 500K pages Web. Chaque page Web représente un fichier XML de CLEF-IP (Figure 51). J’ai créé 3 iMAG dédiées pour accéder à ces sites en utilisant les systèmes que nous avons créés pour les couples fr→en, de→fr, fr→de, et les services de TA disponibles pour les autres couples.
|
|
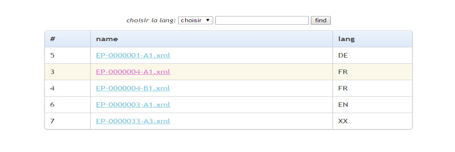
Figure 51 : Capture d'écran du site Web monolingue de CLEF-IP
La Figure 52 montre une capture d’écran de l’iMAG CLEF-en utilisée pour accéder dans d’autres langues aux brevets écrits initialement en anglais. Les segments entre parenthèses vertes ont été trouvés dans la MT CLEF-IP, et les segments entre parenthèses rouges ont été traduits par le système de TA anglais→français.
|
|
Figure 52 : Capture d'écran de l'iMAG dédiée CLEF-IP