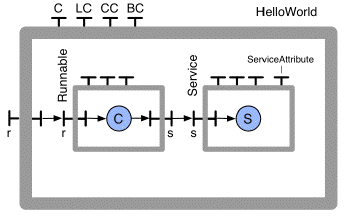
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!DOCTYPE definition PUBLIC
"-//objectweb.org//DTD Fractal ADL 2.0//EN"
"classpath://org/objectweb/fractal/adl/xml/basic.dtd">
<definition name="HelloWorld">
<interface name="r" role="server" signature="java.lang.Runnable"/>
<component name="client" definition="ClientImpl"/>
<component name="server" definition="ServerImpl"/>
<binding client="this.r" server="client.r"/>
<binding client="client.s" server="server.s"/>
</definition>
This fragment specifies the HelloWorld component in terms of
its contained components, whose definitions follow (XML headers are
omitted from here on):
<definition name="ClientImpl">
<interface name="r" role="server" signature="java.lang.Runnable"/>
<interface name="s" role="client" signature="Service"/>
<content class="ClientImpl"/>
</definition>
<definition name="ServerImpl">
<interface name="s" role="server" signature="Service"/>
<content class="ServerImpl"/>
</definition>
The names of the implementation classes are the same as the names
of the definitions. This is only a convention, not a necessity.
These definitions could in fact be embedded into the description of
the HelloWorld component, which would make the overall
description more concise; however, in that case, the descriptions of
the contained components could not be reused.
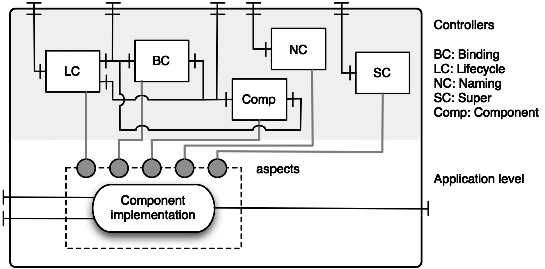
The controller of a primitive or composite component may be specified
by defining a controller descriptor, as well as an attribute controller interface,
and attribute values:
<definition name="ServerImpl">
<interface name="s" role="server" signature="Service"/>
<content class="ServerImpl"/>
<attributes signature="ServiceAttributes">
<attribute name="header" value="->"/>
<attribute name="count" value="1"/>
</attributes>
<controller desc="primitive"/>
</definition>
Component types may be defined, which allows using inheritance,
by adding new clauses to an existing type:
<definition name="ClientType">
<interface name="r" role="server" signature="java.lang.Runnable"/>
<interface name="s" role="client" signature="Service"/>
</definition>
<definition name="ClientImpl" extends="ClientType">
<content class="ClientImpl"/>
</definition>
The above definition of ClientImpl is equivalent to that
previously given. New clauses can also override existing ones.
Other aspects of the Fractal ADL may be found in the tutorial
[Fractal ].
The Fractal ADL tool-set
The first set of tools using the Fractal ADL are factories used
to instantiate a configuration from its ADL description. Thus,
using the HelloWorld example, the following sequence
instantiates a ClientImpl component:
Factory f = FactoryFactory.getFactory();
Object c = f.newComponent("ClientImpl", null);
Here Factory and FactoryFactory are provided in the
Fractal distribution. The second argument of the newComponent method
may be used to specify additional properties. The component
creation proper is done by a back-end component, which comes in several
versions (using either the Java reflection package or the API provided
by the Fractal framework for component creation).
Another use of the Fractal ADL is as a pivot language for various tools.
In particular, the ADL serves as a support for a graphical interface
that provides a graphical view of a Fractal configuration, which can
be directly manipulated by the users.
As a final illustration of the association between tool-sets and
architectural system descriptions, we briefly describe the design of
an extensible tool-set [Leclercq et al. 2007] initially developed with
Fractal ADL as a support language, but potentially usable by other
ADLs. The tool-set is operated as a workflow, made up of three main
components.
- The loader reads a set of input files (typically ADL
descriptions) and generates an abstract syntactic tree (AST), using
grammars and parsers for each input language. The AST represents
the structure of a system in an extensible, language independent
form. Each node represents an element of the system under
description (e.g., components, interfaces, methods, etc.), and has
an extensible set of interfaces (e.g., to retrieve its properties or
to give access to its children).
- The organizer processes the AST to generate a graph of tasks to
be executed (e.g., creating component instances, creating bindings
between components, etc.).
- The scheduler determines the dependencies between the tasks in
the graph, and schedules the execution of the tasks in an order that
respects these dependencies.
The tool-set support the following services: verification of the
architecture's correctness (e.g., correct binding of the interfaces,
including type-checking); generation of "glue code" for components;
generation of stubs and skeletons for distributed components;
compilation of source code and instantiation of components. This
range of services is easily extensible, thanks to the modular structure
of the tool-set and to the extensibility of the AST format. More details
may be found in [Leclercq et al. 2007].
In conclusion, the main features of the Fractal ADL are its
modularity, its extensibility, and its use as a pivot format for a
variety of tools. Dynamic extensions are the subject of current
research.
7.7 Case Study 2: OSGi, a Dynamic, Component-Based, Service Platform
The OSGi Alliance [OSGI Alliance 2005], founded in 1999, is an independent
non-profit corporation that groups vendors and users of networked
services. Its goal is to develop specifications and reference
implementations for a platform for interoperable, component-based,
applications and services.
The OSGi specification defines both a component model and a run time
framework, targeted at Java applications ranging from high-end servers
to mobile and embedded devices. OSGi components are called bundles. A
bundle is a modular unit composed of Java classes, which
exports services, and may import services from other bundles running
on the same Java Virtual machine (JVM). A service is typically
implemented by a Java class provided by a bundle, and is accessible
through one or several interfaces. In addition, a service may be
associated with a set of properties, which allow services to be
dynamically published and searched, using a service discovery service
(3.2.3
) provided by the framework.
In the rest of this section, we briefly summarize the main aspects of
the OSGi specification, and we show how it is
used to develop service-based applications. We
conclude with a review of some implementations and extensions.
7.7.1 The OSGi Component Model
An OSGi bundle is a unit of packaging and deployment, composed of Java
classes and other resources such as configuration files, images, or
native (i.e., processor-dependent) libraries. A bundle is organized
as a Java Archive (JAR) file11, containing Java classes and other
resources, together with a manifest file, which describes the contents
of the JAR file and provides information about the bundle's
dependencies (i.e., the resources needed for running the bundle).
The unit of code sharing between bundles is a Java package. A bundle
can export and import packages12. Exported packages are made available to other bundles,
while imported packages are taken from those exported by other
bundles. If the same package is exported by several bundles, a single
instance is selected (the one exported by the bundle with the highest
version number, and the oldest installation date). Packages that are
neither imported nor exported are local to the bundle.
Package sharing between bundles takes place within a JVM and relies on
the class loading mechanism of Java. Each bundle has a single class
loader. The class space of a bundle is the set of classes visible from
its class loader, through class loading delegation links; it includes,
among others, the imported packages and the required bundles specified
by the bundle. Thus the OSGi framework supports multiple class spaces,
which allows multiple versions of the same class to be in use at the
same time.
In terms of the Fractal component model, OSGI bundles may be seen
as having the equivalent of a binding controller and a lifecycle
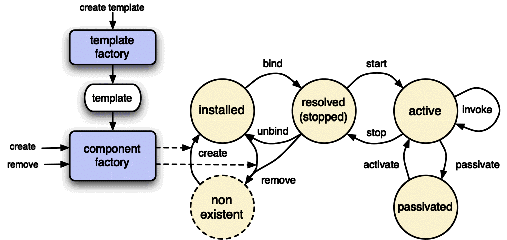
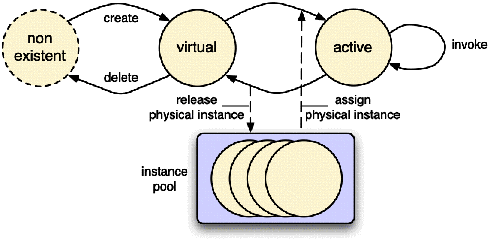
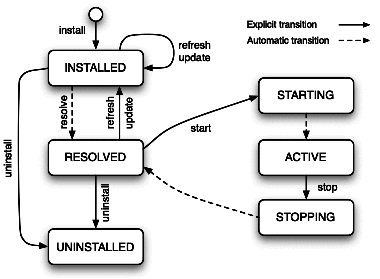
controller. A bundle's lifecycle is represented on Figure
7.19. The states and transitions are
summarized as follows.
Installation
Installation is the process of loading the JAR file that represents the
bundle into the framework. The bundle must be valid, i.e., its
contents must be consistent and error-free. A unique identifier is
returned for the installed bundle. The installation process is both
persistent (the bundle remains in the INSTALLED state until
explicitly un-installed) and atomic (if the installation fails, the
framework remains in the state in which it was prior to this
operation).
Resolution
An installed bundle may enter the RESOLVED state when all its
dependencies, as specified in its manifest, are satisfied. Resolution
is a binding process, in which each package declared as imported is
bound (or "wired", in the OSGi terminology) to an exported package
of a RESOLVED bundle, while respecting specified constraints.
These constraints take the form of matching attributes, e.g., version
number range, symbolic name, etc. Resolution of a bundle is delayed
until the last possible moment, i.e., until another bundle requires a
package exported by that bundle.