Chapitre IV
Outils génériques pour BDLex
"actives" (29,75 p.)
Un point important pour faire progresser le domaine des BDLex et de la lexicographie computationnelle en général est de les faire fonctionner de façon fiable et performante comme des serveurs Web, qui peuvent s'appeler mutuellement (comme Pivax et SECTra), et générer de grandes quantités d'appels. Par exemple, SECTra peut demander à Pivax de recalculer en tâche de fond et itérativement un "mini-dictionnaire" pour chaque segment d'une ou plusieurs mémoires de traductions. Cela demande la lemmatisation de tous les mots de ces segments. Mais cette fonction de lemmatisation peut elle-même être appelée par bien d'autres services, par exemple par un service de "lecture active" comme celui récemment réalisé par M. Mangeot en utilisant la BDLex japonais-français qu'il a réalisée à partir du dictionnaire de Cesselin (85 000 entrées) et de la partie japonais-français du dictionnaire de Jim Breen (~15 000 entrées venant du sous-projet du projet Papillon de Jean-Marc Desperrier).
Dans ce chapitre, nous présentons d'abord la solution retenue (ActiveMQ) pour réaliser la gestion des tâches et des requêtes entre des serveurs lexicaux et d'autres serveurs (comme des serveurs de lemmatisation via Lextoh, de traduction automatique via Tradoh, de gestion de corpus et mémoires de traductions comme SECTra, et de lecture active ou de présentation bilingue).
Nous présentons ensuite l'intergiciel Lextoh qui permet d'appeler un ou plusieurs services de lemmatisation, puis d'unifier et de filtrer leurs résultats, en utilisant le langage TRACOMPL du système Ariane-G5.
Enfin, nous décrivons le logiciel CreatDico qui permet de construire des "mini-dictionnaires" de formes et de formats variés, typiquement à partir d'un segment (phrase ou titre) ou d'un paragraphe.
I.1 Gestion des travaux par ActiveMQ (6 p.)
I.1.1
Motivations : besoins attestés et
fonctionnalités désirées (2,5 p.)
I.1.1.1 Besoins attestés (2 p.)
I.1.1.1.1
Besoins
de SECTra et de Tradoh (0,75 p.)
SECTra_w (Système d'Expoitation de Corpus de Traductions sur le Web) était disponible avant mon arrivée au laboratoire. Ce système a été développé par C.-P. Huynh durant sa thèse [Huynh, C.-P., 2010] et amélioré par H.-T. Nguyen [Nguyen, H.-T., 2009], L. X. Wang [Wang, L. X., 2015] et Ch. Boitet. Il est utilisé pour l'évaluation de systèmes de TA et pour la postédition collaborative de pages Web prétraduites par un ou plusieurs systèmes de TA.
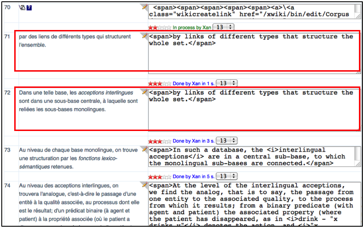
Les prétraductions sont obtenues via des appels à Tradoh [Vo-Trung, H., 2004]. Tradoh est un intergiciel d'appel à un ou plusieurs services de traduction automatique. SECTra envoie souvent une suite de requêtes à Tradoh. Il n'y a pas de gestion de files d'attente entre les requêtes de SECTra et les réponses de Tradoh, ce qui provoque parfois un problème de décalage entre segments source et segments cible. Voir la Figure 71.
|
Figure 71 :
Décalage de prétraductions dans SECTra après plusieurs
appels consécutifs à Tradoh |
I.1.1.1.2
Besoins
de Pivax
pour les mini-dictionnaires (0,25 p.)
H.-T. Nguyen a essayé vers la fin de sa thèse de créer un mini-dictionnaire pour le projet et pour chaque segment dans SECTra par des appels à Jibiki-1/Pivax-1. Cet effort n'a pas réussi à cause des mauvaises performances de Jibiki-1/Pivax-1 (voir I.1.4.3, I.1.4.3 et II.2.4) et du manque d'outil de gestion de files d'attente. Avec Jibiki-2/Pivax-3, même si les performances sont meilleures qu'avec Jibiki-1/Pivax-1, on ne peut toujours pas garantir un délai de réponse.
I.1.1.1.3 Besoins de Lextoh et CreatDico (0,5 p.)
Les nouveaux intergiciels Lextoh et CreatDico ont les mêmes besoins. Lextoh est un intergiciel de lemmatisation. CreatDico est un intergiciel de création de dictionnaires relatifs à un ensemble de mots. Ils seront présentés en détail dans les sections suivantes.
Un exemple d'utilisation simple de Lextoh par SECTra est une demande d'analyse morphologique de chaque segment pour annoter les deux parties d'un corpus bilingue et préparer l'apprentissage d'un système Moses de type "factoriel".
Un scénario d'utilisation de CreatDico est la création de mini-dictionnaires pour SECTra. SECTra peut envoyer 1000 requêtes en même temps à CreatDico. Chaque requête concerne la demande d'un mini-dictionnaire pour un segment. Pour traiter une requête, CreatDico envoie le segment à Lextoh pour demander son analyse morphologique. Après avoir reçu les lemmes, CreatDico envoie la requête à Pivax. Même si on peut consulter plusieurs lemmes dans une requête en utilisant l'API de Jibiki[1], le délai de réponse est parfois dépassé.
I.1.1.1.4
Besoins
d'autres projets (1 §.)
Il y a également d'autres outils ou projets de notre équipe, comme SegDoc [Kalitvianski, R., 2013], OMNIA [Rouquet, D. & Nguyen, H. T., 2009 ; Rouquet, D. et al., 2013], IToldU [Bellynck, V. et al., 2005] qui ont besoin d'un outil de gestion de flots de travaux.
I.1.1.2 Fonctionnalités désirées (0,5 p.)
I.1.1.2.1
Gestion
de flots de travaux (files d'attente
et priorités) (1 §.)
Pour permettre de traiter des "flots de travaux" envoyés de n'importe où, il ne faut pas seulement des files d'attente, mais aussi des priorités. Une requête de consultation par un humain doit être traitée le plus vite possible.
I.1.1.2.2
Possibilité
de gagner en sécurité et d'assurer l’intégrité des données (1 §.)
Nous avons aussi la nécessité de sécurité et d'intégrité. Il ne faut pas perdre les requêtes après un redémarrage du serveur de type "boîte aux lettres". Il faut garantir que toutes les requêtes seront traitées, renvoyer automatiquement une requête s'il y a un grand délai impossible (on considère alors que la requête est perdue). Il faut aussi pouvoir traiter les requêtes de manière asynchrone.
I.1.1.2.3
Surveillance
des travaux en cours et compatibilité (1 §.)
Il faut pouvoir surveiller toutes les tâches de "boîte
aux lettres" par une interface. En plus, comme on a plusieurs outils écrits
dans plusieurs langages de programmation, on désire pouvoir traiter une grande
variété de clients et de protocoles écrits en PHP, JAVA, C++. La simplicité d'utilisation
est également importante.
Comme ce type de système demande un gros développement, nous avons cherché un outil qui pourrait nous convenir.
I.1.2 Approches envisageables (1 p.)
I.1.2.1
Extension de Blexisma (0,25
p.)
Blexisma (Base LEXIcale Sémantique Multi-Agents) est un système d'agents à gros grains, développé par Didier
Schwab dans le cadre de sa thèse [Schwab, D.,
2005], qui portait sur la désambiguïsation
lexicale et les fonctions lexicosémantiques.
Pendant le projet Traouiero (2011-2012),
notre équipe avait prévu de développer une extension de Blexisma [Schwab, D., 2013]. L'objectif était de passer d'une organisation en clients et serveurs à une organisation en agents à
gros grains. Au niveau de la réalisation, le but de cette tâche était de
construire un dispositif de contrôle du système complet et d'organiser les modules principaux comme des
agents à gros grains. Mais la personne compétente a été prise sur un autre
projet et rien n'a été fait.
I.1.2.2
Reprise du "réseau Cash/Lidia"(0,25 p.)
Ariane-G5 (système de développement et d'exploitation d'applications
de traduction automatique) fonctionne grâce à un "réseau de machines
virtuelles" sur un serveur IBM équipé de zVM/CMS. La réalisation du réseau
CASH/LIDIA par Pierre Guillaume utilise comme dispositif d'interconnexion le "Spooling System" de VM et la mise en communication des
lecteurs-perforateurs (READER PUNCHER) des machines virtuelles d'un même site
VM/SP. Il s'agit donc de communications asynchrones et les problèmes de conflit
d'accès sont laissés à VM/SP. La communication entre machines virtuelles se
présente comme des échanges de fichiers (fichiers SPOOL) et de gestion de files d'attente (sur des
lecteurs virtuels). Il s'est également avéré indispensable d'envisager une
gestion de messages permettant une synchronisation rapide de l'état du réseau
(machines serveurs Ariane-G5 invitées à stopper en fin de leur
traitement courant par exemple). Ce réseau intègre la (ou les) machines
virtuelles gérant le "Remote
Spooling" de façon à
pouvoir éventuellement prolonger le réseau vers des sites extérieurs.
Ce système ne nous convenait
pas, car nous voulions que tous les "agents" ou simplement
"services" soient des services Web.
I.1.2.3
Utilisation de JobCenter[2] (0,25 p.)
JobCenter est une plate-forme de gestion des travaux et d'exécution de travail distribué. Cet outil a
été développé par Bio Med, et est en source ouvert.
Il y a deux types
de composants dans ce système : client et serveur. Les deux types sont
écrits en Java. Toutes les communications avec le serveur de JobCenter sont
réalisées par un pilote du client. Le client peut envoyer un message à une file
d'attente avec sa priorité.
Nos outils
devraient appeler d'abord les
composants clients de JobCenter pour communiquer avec le serveur. Les
appels sont fait par le protocole HTTP en utilisant une API
REST et XML.
JobCenter aurait été une très bonne solution. On ne l'a finalement pas utilisé, parce que son installation
est lourde et qu'il y a peu d'exemples d'utilisation. De plus, il faut le déployer sur le serveur et sur chaque client. Cet outil
demande également l'installation
d'une base de données sur le
serveur, dans laquelle les configurations des clients sont enregistrées. Après
chaque ajout d'un client, il
faut mettre à jour la base de données du serveur.
I.1.2.4
Utilisation de ActiveMQ[3] (0,25 p.)
ActiveMQ est un intergiciel à messages utilisable pour le développement d'une architecture MOM (Middleware Oriented Messages). Cet outil a été créé par la fondation Apache, et est en source ouvert. Il est écrit en Java en utilisant JMS (Java Message Service). Il supporte beaucoup de langages et de protocoles pour les clients. Il est utilisé par plusieurs grands projets comme Apache Camel[4], Jetty[5], Apache Mix[6], Mule[7] et également UIMA.
Cet outil nous convient très bien car il couvre tous nos besoins. Il est de plus encapsulé dans un fichier téléchargeable. Après une simple décompression, l'outil est utilisable, sans installation particulière. Le serveur ActiveMQ est déployé automatiquement par l'exécution d'une ligne de commande. Il n'y a pas besoin de le déployer sur les clients.
Il y a beaucoup d'exemples et de tutoriels détaillés sur le
site officiel d'ActiveMQ. Il supporte aussi beaucoup de
langages de programmation sur les clients (Java, Perl, Php, Pyton, C, C++, C#, Ruby). De base,
il est possible de se connecter en TCP, mais il est
aussi possible d'échanger du texte via HTTP (REST ou SOAP). On l'a choisi aussi
pour sa bonne intégration avec la plate-forme Spring[8].
Cela nous a permis de diminuer le temps de programmation.
I.1.3 Intégration d'ActiveMQ
I.1.3.1 Étude et analyse d'ActiveMQ
I.1.3.1.1 Mécanismes de traitement de messages (0,5 p.)
Il y a deux mécanismes de traitement de messages : le mode diffusion/écoute (topic) et le mode message suivi (queue). Les différences sont montrées dans la Table 13.
Table 13 : Comparaison des mécanismes de traitement de messages d'ActiveMQ
|
Mécanisme |
Diffusion/écoute (topic) |
Message suivi (queue) |
|
Statut d'enregistrement |
Pas d'enregistrement |
Le message est enregistré par défaut comme un fichier. On peut également l'enregistrer
dans une base de données par une configuration. |
|
Intégrité et
sécurité |
Si un client n'a pas lancé le programme d'écoute, il ne peut pas recevoir
le message. Ce mécanisme ne supporte pas le traitement asynchrone. |
Après réception d'un message adressé à un client, le système crée un
symbole de traitement pour ce message. Si le programme de réception du destinataire
ne s'exécute pas, le message sera enregistré, et sera envoyé quand le
programme de réception du destinataire sera activé. |
|
Destination |
Un message est consommé une ou plusieurs fois par un ou plusieurs
destinataires. |
Un message est consommé une seule
fois par un seul destinataire. |
Après cette analyse, on a choisi le mode message suivi pour
nos premières implémentations. Chaque client est créé comme destinataire de
type queue.
I.1.3.1.2
Attributs de message et fonctionnalités
correspondantes (0,5 p.)
Chaque message contient une suite d'attributs : Destination, ReplyTo, Type, DeliveryMode, Priority, MessageId, Timestamp, CorrelationID, Expiration et Redelivered. Ces attributs nous permettent de spécifier les différents types de requête.
I.1.3.2 Implémentation
I.1.3.2.1 Architecture globale (0,5 p.)
On déploie une seule fois ActiveMQ comme serveur de gestion des travaux. Un système ou un outil comme Lextoh, Pivax, SECTra, etc. est défini comme un client.
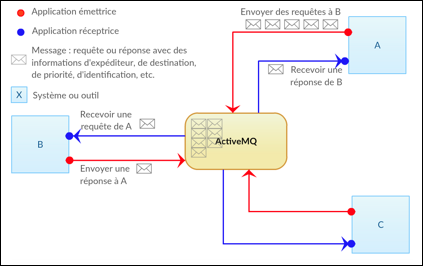
Chaque client doit fournir deux petites implémentations de ses spécifications : une implémentation de producteur (ou émetteur) et une implémentation de récepteur (ou consommateur, ou écouteur). Les producteurs sont lancés par un programme spécial ou par une commande au terminal pour envoyer les requêtes. Quand les requêtes sont envoyées, le programme du producteur s'arrête tout de suite. Les récepteurs activent leur programme d'écoute en boucle pour recevoir les requêtes. Voir la Figure 72. Chaque message est enregistré comme un fichier sur le serveur.
|
Figure 72 : Architecture "client- serveur"
de gestion de travaux en utilisant ActiveMQ |
I.1.3.2.2 Interfaces et disponibilité
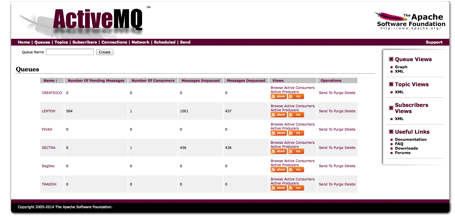
La Figure 73 montre la page d'accueil de l'interface de contrôle d'ActiveMQ.
Notre serveur ActiveMQ est disponible sur la machine aximag2 (http://46.105.41.94:8161/admin/).
|
Figure 73 : Page d'accueil de l'interface de contrôle d'ActiveMQ |
I.1.3.3 Expériences et validations (0,5 p.)
I.1.3.3.1
Pour vérifier ce système, on a fait des expériences sur le problème du décalage des prétraductions par TA dans SECTra, présenté au IV.1.1 ci-dessus.
La procédure principale est la suivante :
SECTra→ActiveMQ→Tradoh→ActiveMQ→SECTra
SECTra envoie une suite de requêtes via
l'émetteur de SECTra vers la queue Tradoh,
via le serveur ActiveMQ. Chaque requête contient une
demande de prétraduction d'un segment avec ses paramètres. Ces requêtes sont
enregistrées au niveau d'ActiveMQ quand elles arrivent.
L'écouteur de Tradoh traite ces requêtes, et appelle l'API de Tradoh pour les traiter une
par une. Ensuite l'émetteur de Tradoh envoie les
réponses à la queue SECTra sur le serveur ActiveMQ. Les prétraductions sont faites correctement et sans
décalage.
La Table 14 montre quelques détails sur ces expériences. Les informations supplémentaires, le fichier des requêtes source et le fichier des prétraductions reçues dans l'expérience 1 sont donnés dans l'Annexe 9.
Table 14 : Expériences sur les appels de Tradoh à partir de SECTra via ActiveMQ
|
Expérience |
Nombre de requêtes |
Langue source |
Langue cible |
Système de TA |
Longueur moyenne de segment |
Temps utilisé |
|
1 |
100 |
zho |
fra |
Google |
39.66 |
00:41 |
|
2 |
500 |
zho |
fra |
Google |
40.688 |
03:20 |
|
3 |
1 000 |
zho |
fra |
Google |
40.657 |
05:59 |
|
4 |
2 000 |
zho |
fra |
Google |
40.657 |
08:38 |
|
Remarque : ·
L'envoi des requêtes est fait très
rapidement (moins d'une
seconde dans les expériences 1 et 2, et moins de deux secondes dans les
expériences 3 et 4). ·
Temps
utilisé = Début d'envoi
de requête – Dernière prétraduction reçue par SECTra ·
Longueur
moyenne = longueur moyenne des segments source (chinois) en caractères |
||||||
I.2 Lextoh
Lextoh est un intergiciel de lemmatisation. Nous le présentons en 3 sous-sections : motivations, conception globale et expérimentation/validation. Pour éviter une longue description purement technique, les spécifications détaillées sont mises en annexe (Annexe 10).
I.2.1 Motivations (1 p.)
I.2.1.1 Support de systèmes de TA de type Moses (0,35 p.)
MosesLIG-fr-zh est un système de traduction automatique français→chinois, réalisé par L. X. Wang dans le cadre de sa thèse [Wang, L. X., 2015]. Il a utilisé 80000 bisegments post-édités pour construire le modèle de traduction.
Les entrées (les ressources pour entraîner le modèle de traduction et également les textes à traduire) des systèmes de TA de type Moses n'acceptent que les textes avec des séparateurs de mots. Il le faut pour toutes les langues.
Par exemple, pour le français, c’est →c⍽’⍽est.
Pour le chinois, c'est difficile à faire. On est obligé d'utiliser des segmenteurs spécifiques. Par exemple, 这周末有日内瓦车展。(Il y a le salon de l'auto de Genève ce weekend.) → 这(ce)⍽周末(weekend)⍽有(avoir)⍽日内瓦(Genève)⍽车展(le salon de l'auto).
Au début, L. X. Wang a utilisé l'outil Xelda[9] de Xerox avec la licence de L&M[10]. Après sa thèse, il ne pouvait plus l'utiliser, et il a utilisé des segmenteurs libres de droits comme celui de Stanford et celui de XMU (Université de Xiamen).
D'autre part, pour entraîner les systèmes Moses
à facteurs, en plus de la segmentation en mots, il faudra annoter les corpus
par des résultats d'analyse morphologiques et éventuellement de
désambiguïsation lexicale (WSD).
I.2.1.2 Consultation dictionnairique avancée (0,5 p.)
I.2.1.2.1 État de l'art (de l'existant)
La recherche avec lemmatisation et segmentation en mots est une fonction assez répandue. Par exemple, dans le projet OMNIA [Rouquet, D. & Nguyen, H. T., 2009], les mots composés sont pris en compte. Cela veut dire, que pour le texte white paper wall, on a besoin de consulter les possibilités suivantes dans la BDLex : white, paper, wall, white paper, paper wall et white paper wall. On a utilisé NooJ et Delaf pour ce projet (voir II.2.3.1).
Dans leurs thèses, H.-T. Nguyen [Nguyen, H.-T., 2009] et C.-P. Huynh [Huynh, C.-P., 2010], ont proposé d'intégrer la recherche dictionnairique avec analyse morphologique (ex. Pivax-1) dans le système THAM (ex. SECTra) en utilisant l'outil NooJ[11]. Ils ont également discuté des possibilités d'utiliser Pilaf[12] pour le français.
D'autre part, pour la plate-forme Jibiki, on a besoin d'une fonction de ce type pour toutes les BDLex. M. Mangeot a utilisé l'analyseur morphologique du japonais MeCab[13] et l'analyseur du français TreeTagger[14] pour réaliser la fonction "lecture active"[15] dans le cadre de son projet Jibiki-Japonais→français à l'Université Hosei [Mangeot, M., 2016]. Cette fonction a également été reprise dans le sous-projet Lexinnova du projet Innovalangues.
I.2.1.2.2 Analyse
Le point important est que, jusqu'ici, dans le contexte de Jibiki, ou des autres BDLex ayant la possibilité de lemmatiser ou de segmenter en mots, on doit écrire du code spécifique pour chaque langue de chaque BDLex et chaque lemmatiseur, et on ne peut appeler qu'un lemmatiseur à la fois. Notre objectif ici est d'avoir un outil générique permettant d'intégrer facilement tous ces analyseurs dans nos systèmes.
I.2.1.3 Production de mini-dictionnaires de formats variés
La dernière motivation est de disposer d'un outil permettant de construire des mini-dictionnaires. Nous présenterons la production de mini-dictionnaires dans la section suivante (IV.3). Pour pratiquement tous, il faut commencer par une lemmatisation.
I.2.2 Conception de Lextoh (5,25 p.)
I.2.2.1 Fonctionnalités désirées (1,75 p.)
Serveur. Lextoh est un serveur paramétrable d'appel de lemmatiseurs, ou plus généralement de segmenteurs, de racineurs, ou d'analyseurs morphologiques complets. Nous l'appelons en bref "intergiciel de lemmatisation". Il fonctionne comme un service Web avec méthodes POST ou GET.
Interfaces. Les programmes peuvent accéder au service par l'API, et les utilisateurs humains peuvent accéder au service par l'API ou par un formulaire.
La requête d'URL par l'API contient les paramètres texte, langue, choix de lemmatiseur, format de sortie, formalisme de représentation etc., voir le paragraphe suivant (Entrées et sorties).
L'interface de type formulaire permet à des utilisateurs humains d'accéder facilement au service en utilisant des boutons et des zones de texte. On a repris le formulaire proposé par V. Bellynck, formulaire général auto-rempli[16] en PHP.
Outils à intégrer. Il y a plusieurs outils disponibles selon les langues comme Jieba, xip, XeLDA, Ariane-Heloise, Standford-CoreNLP, Standford-Segmenter, le Delaf, etc. On donnera une brève présentation de chaque outil au IV.2.2.2.2. Lextoh est un système générique, c'est-à-dire que chaque outil y est intégré par un plugin.
Entrées et sorties. Les entrées de Lextoh contiennent les paramètres suivants.
· lang : langue source, 3 caractères latins selon la norme iso 639-2/T.
· lemmat : choix du lemmatiseur.
· output : format de sortie (ex. txt, Json, Xml).
· formalism : grammaire formelle (ex. réduit, graphe-Q), voir l'explication ci-dessous.
· text : texte à analyser, un texte directement extrait d'un document.
· debug : 1 ou 0, il permet d'afficher tous les paramètres et leurs valeurs de requête dans le composant de debug, sur la même interface que le résultat.
· window (pour le Delaf) : offset des résultats de tokenisation (ex. window=3, text=pomme de terre, le résultat de tokenisation est "pomme", "de", "terre", donc le système va vérifier les lemmatisations pour "pomme", "pomme de", "pomme de terre", "de", "de terre", "terre").
· form : 1 ou 0, si 1, affichage du formulaire ; si 0, affichage seulement des résultats (API-REST).
Pour les sorties, il y a les formalismes de sortie et les formats de sortie. Les formalismes définissent les éléments affichés dans une sortie et la forme de l'affichage.
Par exemple, le formalisme graphe-Q(AC)[17] est une combinaison de type
forme + (lemme ou UL) + POS + toutes les informations (genre, nombre, temps, etc.) + Géométrie en graphe de chaînes.
Le formalisme réduit est une combinaison de type
forme + lemme + POS + Géométrie en liste sans répétition.
On peut afficher chaque formalisme dans n'importe quel format de sortie. Par exemple, pour le format Json, on a ce qui suit.
· Formalisme graphe-Q
|
Entrée : , var JSONObject=[ {"system":"delaf",
"langue":"fra", "output":"json",
"formalism":"graphe-Q(AC)"}, {-0-$OCC($FORME(les),$LU($LEMMA(le),$CAT(DET),$AC(gender_masculine,number_plural)))-3-}, {-0-$OCC($FORME(les),$LU($LEMMA(la),$CAT(DET),$AC(gender_feminine,number_plural)))-3-}, {-0-$OCC($FORME(les),$LU($LEMMA(le),$CAT(PRON),$AC(person_3,gender_masculine,number_plural)))-3-}, {-0-$OCC($FORME(les),$LU($LEMMA(le),$CAT(PRON),$AC(person_3,gender_feminine,number_plural)))-3-}, {-3-$OCC($FORME(#U#20#),$LU($LEMMA(#U#20#),$CAT(UNK),$AC(none)))-4-},[18] {-4-$OCC($FORME(pommes),$LU($LEMMA(pomme),$CAT(NOUN),$AC(gender_feminine,number_plural)))-10-}, {-4-$OCC($FORME(pommes),$LU($LEMMA(pommer),$CAT(VERB),$AC(tense_ind,person_2,number_singular)))-10-}, {-4-$OCC($FORME(pommes),$LU($LEMMA(pommer),$CAT(VERB),$AC(tense_subj,person_2,number_singular)))-10-} ] |
· Formalisme réduit
|
Entrée : les pommes var JSONObject=[ {"system":"delaf",
"langue":"fra", "output":"json",
"formalism":"réduit"}, {"form":"les",
"lemma":"le", "pos":"DET"}, {"form":"les",
"lemma":"la", "pos":"DET"}, {"form":"les",
"lemma":"le", "pos":"PRON"}, {"form":"les",
"lemma":"la", "pos":"PRON"}, {"sep":" "},[19] {"form":"pommes",
"lemma":"pomme", "pos":"NOUN"}, {"form":"pommes",
"lemma":"pommer", "pos":"VERB"} ] |
Lextoh permet aussi d'afficher les sorties des différentes étapes (le flot de traitement), de la sortie native (le retour d'appel de lemmatiseur) à la sortie finale, voir l'Annexe 10.
Configurations et
autres fonctionnalités. Les
fichiers de configuration permettent de configurer les outils, les langues, les
formalismes et les formats utilisables. On a prévu également d'offrir d'autres
fonctions dans cette interface par formulaire, comme la fonction "trace ou
debug" pour le débogage, l'interface d'explication, les exemples d'utilisation
d'API et d'utilisation de formulaire, etc.
Robustesse. La fiabilité
du système est nécessaire pour qu'on puisse lui envoyer un grand nombre de
requêtes en même temps. Pour la gestion de files d'attente, on utilise ActiveMQ.
I.2.2.2 Architecture globale de LEXTOH (1,25 p.)
I.2.2.2.1 Schéma de l'architecture logicielle (1 p.)
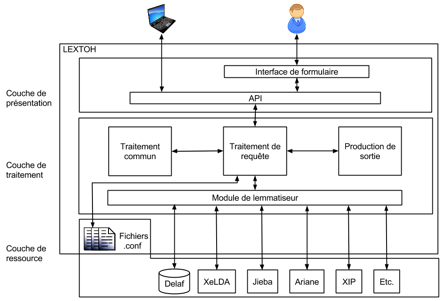
Lextoh est composé de trois couches principales : une couche de présentation, une couche de traitement et une couche de ressource/outil. Voir la Figure 74.
Couche de présentation. Elle est responsable des interactions avec les utilisateurs. Après avoir reçu une requête dans cette couche, le système envoie les paramètres à la couche de traitement.
Couche de traitement. Dans cette couche, il y a plusieurs modules. Le module "traitement de requête" est le module principal.
Le deuxième module est le module d'appel aux lemmatiseurs (les plugins, un plugin pour chaque outil). Chaque plugin contient deux fonctions. La première est le prétraitement et la méthode d'appel. La deuxième est le post-traitement (nettoyage, changement d'encodage, etc.).
Le troisième module est le module "traitement commun". Ce module comporte plusieurs étapes de traitement pour obtenir une sortie bien uniformisée.
Le quatrième module est le module de "sortie". Il s'agit de transformer la sortie uniformisée vers une sortie demandée par l'utilisateur, combinant un formalisme et un format.
Couche de ressource. Cette couche correspond aux lemmatiseurs externes et aux fichiers de configuration.
|
Figure 74 : Architecture de Lextoh |
I.2.2.2.2 Outils appelés (0,5 p.)
Jieba[20] est un segmenteur du chinois (avec un peu d'analyse syntaxique), libre de droits.
XIP[21]
est un analyseur syntaxique de Xerox, créé par Claude
Roux. Il contient pour chaque langue traitée, l'analyseur morphologique
développé en XSLT et contenu dans le produit Xelda. Le GETALP en a une
licence de recherche pour le français et l'anglais.
XeLDA[22]
est un produit de Xerox qui contient également les
analyseurs morphologiques pour une vingtaine de langues. L&M en a une
licence industrielle, et j'ai pu l'utiliser durant ma thèse.
Ariane-Héloïse
contient tous les analyseurs morphologiques écrits en Ariane
et développés au sein du GETA, puis du GETALP pour
l'allemand. V. Berment a créé une API permettant d'appeler tous les analyseurs qui tournent sur son serveur Héloïse[23] [Berment, V. & Boitet, C., 2012]. Il y en a pour le russe, le français, l'anglais, le
portugais, l'espagnol (depuis 2015), et l'allemand.
CoreNLP[24] contient
des analyseurs morphologiques développés sur cette plate-forme par Alshawi et
son équipe de l'université de Stanford, libres de droits.
Segmenter[25]
est un autre outil de l'université de Stanford. Il contient les segmenteurs de
l'arabe et du chinois, libres de droits.
Le Delaf[26] est un dictionnaire de formes (par opposition au Delas, dictionnaire de lemmes) développé par le LADL (M. Gross et son équipe) pour le français et pour l'anglais. La forme Xml de cette ressource est téléchargeable gratuitement. Pour l'utiliser, on peut le convertir en sql par un script puis l'importer dans une base de données.
En plus des lemmatiseurs présentés ci-dessus, Lextoh a prévu d'appeler trois outils externes.
SegDoc [Kalitvianski, R., 2013] est un outil pour segmenter un grand texte source.
TRACOMPL [Guillaume, P., 1989] est un des langages spécialisés d'Ariane-G5. Il permet de programmer très simplement la transformation d'une décoration d'un "jeu de décorations" Jeu1 vers un "jeu de décorations" Jeu2. On peut l'utiliser pour normaliser les symboles utilisés pour noter les variables et leurs valeurs.
Par exemple, il existe des normes différentes pour les résultats d'analyse morphologique pour différentes langues et différents outils. Cela permettra de diminuer la programmation, de fusionner les résultats de plusieurs analyseurs morphologiques si nécessaire, et de filtrer pour ne sortir que les variables/valeurs utiles pour la recherche dans une BDLex.
ATEF [Chauché, J., 1975] développé en 1972 par J. Chauché, P. Guillaume et M. Quézel-Ambrunaz, est le langage utilisé en Ariane-G5 pour écrire les analyseurs morphologiques. On l'a déjà mentionné au III.4.2.3.
Pour les communications avec TRACOMPL et ATEF, nous avons spécifié et nous sommes en train de réaliser les implémentations, mais ce n'est pas encore mis en service. Pour la version actuelle publiée sur notre serveur, nous les avons réalisées de façon ad hoc.
I.2.2.3 Utilisateurs et scénarios (3 p.)
I.2.2.3.1 Utilisateurs (0,75 p.)
a. Humain (0,325 p.)
|
Rôle d'utilisateur humain |
Droits |
|
Administrateur |
· Modification de la liste des outils appelables (leur "déclaration") et modification de la configuration. · Lancement du serveur. |
|
Linguiste lexicographe |
· Modification de certains paramètres (par exemple, les filtres), ou renommage d'une version. · Aussi et surtout : tests du fonctionnement de Lextoh. |
|
Linguiste-informaticien |
· Exécution de tâches spécifiques (par exemple, ajout d'un nouvel outil en créant un plugin). |
b. Machine (0,325 p.)
|
Rôle d'utilisateur machine |
Tâches |
|
CreatDico (que l'on présentera au IV.3) |
CreatDico sera appelé par SECTra/iMAG. Il appellera Lextoh pour obtenir
une sortie (Lemme + POS), puis appellera les services dictionnairiques,
construira un mini-dictionnaire, et le renverra à l'appelant. |
|
Jibiki |
Lemmatisation pour consultation d'un dictionnaire. |
|
JianDan-eval[27]/MosesLIG |
Pour obtenir des "textes annotés" par l'analyseur morphologique,
destinés à l'apprentissage de systèmes Moses à facteurs. Segmentation des entrées multilingues (surtout pour le chinois). |
|
Programme non encore spécifiés. On pense à OMNIA. |
Annotation et extraction de contenu. |
I.2.2.3.2
Scénarios (1,5 p.)
Les utilisations de Lextoh pourraient être nombreuses. On donne ici quatre scénarios complètement différents. Le premier est une utilisation par un programme, avec un grand nombre de requêtes. Le deuxième est une utilisation par un programme, avec une requête qui est activée par un humain. Le troisième est une utilisation directe sur l'interface de Lextoh. Le quatrième concerne la configuration.
On montre les résultats de ces scénarios (avec des mesures et des interfaces) à la section suivante IV.2.3.2.
a. Scénario 1 : Demande de JianDan-eval d'annoter un corpus en utilisant ActiveMQ (0,5 p.)
1. JianDan-eval demande 1 000 requêtes à la fois (annotation de 1 000 segments postédités) par un bouton d'interface de JianDan-eval. Il s'agit de 310 segments anglais (155 avec l'outil Xelda, 155 avec l'outil xip), 280 segments chinois avec l'outil Jieba et 410 segments français (205 avec l'outil Xelda et 205 avec l'outil xip) dans la mémoire de traductions.
2. Le producteur associé à JianDan-eval envoie ses requêtes à ActiveMQ avec deux types de paramètre : paramètres d'attributs de message (il s'agit des paramètres d'ActiveMQ, par exemple, destination = Lextoh, Priority = 4) et paramètres de contenu de message (il s'agit de paramètres de Lextoh, par exemple le segment, la langue, le choix du lemmatiseur et la sortie).
3. ActiveMQ enregistre ces requêtes dans le serveur.
4. Si Lextoh est libre, le consommateur de Lextoh reçoit une requête à la fois selon la priorité du message et selon le moment d'arrivée. Puis ActiveMQ considère que Lextoh est occupé.
5. Lextoh traite un message. Pour ces 1 000 requêtes, il y a deux cas différents :
a. Si le traitement est fini et est réussi, le consommateur associé à Lextoh est libre et envoie un symbole ACKNOWLEDGE à ActiveMQ. L'attribut ReplyTo de cette requête est JianDan-eval, le consommateur de Lextoh demande au producteur de Lextoh d'envoyer le résultat de cette requête à JianDan-eval (avec deux types de paramètres : paramètres d'attributs de message et paramètres de contenu de message, comme à l'étape 2). Ce programme est lancé en parallèle avec le consommateur de Lextoh.
b. Si Lextoh termine son traitement sans réussite, le consommateur de Lextoh est libre et sans symbole ACKNOWLEDGE. La requête sera renvoyée par ActiveMQ.
6. Boucler sur les étapes 4 et 5 jusqu'à ce qu'il n'y ait plus de requête.
b. Scénario 2 : Demande de lemmatisation par Pivax-2 (0,25 p.)
On utilise ActiveMQ pour la gestion des travaux, comme dans le scénario 1. Comme une description avec ActiveMQ est longue et compliquée, on simplifie les scénarios suivants.
Par exemple, ce scénario 2 concerne une demande de lemmatisation par Pivax-2. La procédure est Pivax-2→ActiveMQ→Lextoh→ActiveMQ→Pivax-2.
On simplifie : Pivax-2→Lextoh→Pivax-2.
Il y a une chose à remarquer ici, c'est que la requête est lancée par un humain, pas par un programme, donc nous fixons une priorité élevée : Priority = 7[28]. C'est une réalisation/spécification dans le producteur de Pivax-2.
1. L'utilisateur
arrive sur la page de consultation avancée de Pivax-2.
2. Il
entre les conditions de consultation avec les paramètres : le
mot-vedette est "allongerons"
et le
lemmatiseur est "xip".
3. Il
lance la requête par le bouton "è".
4. La page est mise à jour et le résultat est affiché.
c. Scénario 3 : Utilisation d'un exemple de formulaire par un linguiste (0,15 p.)
Il s'agit d'un linguiste-informaticien ou d'un lexicographe qui fait une
expérience dans la page de formulaire en utilisant l'exemple (le lien pré-rempli par un clic) en
bas de la page.
1. L'utilisateur arrive à la page d'accueil de Lextoh.
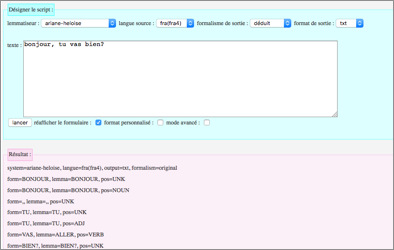
2. Il clique sur un lien d'exemple en bas de la page Web : http://46.105.41.94/Ci-Hai/Lextoh/index.php?text=bonjour, tu vas bien?&lemma=ariane-heloise&window=5&lang=fra(fra4)&output=txt&formalism=reduit&formule=1
3. La page est mise à jour avec des paramètres pré-remplis et le résultat est affiché.
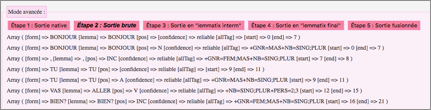
4. L'utilisateur clique sur le bouton "mode avancé" pour suivre le flot de traitement.
d. Scénario 4 : Configuration des outils appelables par l'administrateur (0,15 p.)
Il s'agit d'un administrateur qui modifie les outils appelables et leurs décorations par les fichiers de configuration.
1. L'administrateur ouvre le fichier conf_ressource.xml.
2. Il désactive l'analyseur morphologique XeLDA (il a mis la description de XeLDA en commentaire). Voir la Figure 78.
I.2.3 Expérimentation et validation (2 p.)
I.2.3.1 Interface principale et disponibilité (1 p.)
La version interne est la version la plus récente, installée sur le serveur interne danang.imag.fr du GETALP. On a travaillé et testé sur cette version. Mais ce n'est pas une version stable, et elle ne permet pas l'accès depuis Internet.
La version publiée est installée sur http://46.105.41.94/Ci-Hai/Lextoh.
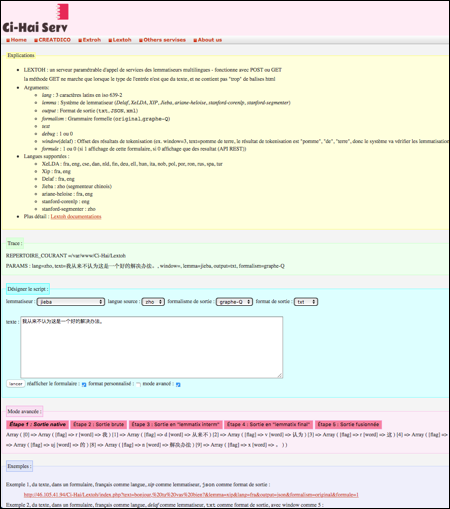
L'interface principale est montrée dans la Figure 75.
|
Figure 75 : Interface principale de Lextoh |
I.2.3.2 Test du système (1,25 p.)
I.2.3.2.1 Utilisation pour l'annotation de corpus (JianDan-eval)
Voici le résultat pour le scénario 1.
|
Nbr req |
Langues |
Lemmatiseurs |
Temps total |
Remarque |
|
310 |
Anglais |
Xelda ou xip |
28min20s |
Annotation de
corpus : s'il n'y avait que des
segments français et anglais, ça serait beaucoup plus rapide. Mais avec le chinois,
le lancement de Jieba est lent. |
|
280 |
Chinois |
Jieba |
||
|
410 |
Français |
Xelda ou xip |
I.2.3.2.2 Utilisation pour la consultation de dictionnaires (Pivax-2)
On a déjà présenté cette utilisation au II.3.3. Le résultat est affiché sur la Figure 29.
I.2.3.2.3 Utilisation d'un exemple de formulaire par un linguiste (résultat du scénario 3)
|
Figure 76 : Résultat de Lextoh pour l'exemple utilisant Ariane-Heloise |
|
Figure 77 : Résultat en mode avancé de Lextoh pour l'exemple utilisant Ariane-Heloise |
I.2.3.2.4
Configuration des
outils appelables par l'administrateur (résultat du scénario 4)
Après la désactivation de XeLDA, XeLDA n'est plus contenu dans la liste de lemmatiseurs affichée sur l'interface. On ne peut plus l'utiliser. Si on demande les services sur l'API, le système nous envoie un message d'erreur (lemmatiseur indisponible).
|
<RESSOURCES dateCreation="20140221" dateDerniereModif="201501218" typeRessources="parOutil"> <Outils codeLM = "xip" codeEnt = "utf8" codeLg = "fra
eng" sortiesPossibles = "arbre_A" url = "https://open.xerox.com/Services/XIPParser/" requeteType
= "API" requete="http://atoum.imag.fr /getalp/Services/Web/CREATDICO/callXip.php?lang=$langSource&text=$fichEnt"/> <!-- Modifié par Ying. Il n’y a plus de license à
partir du 1 novembre 2015 --> <!--Outils codeLM = "XeLDA" codeEnt =
"utf8" codeLg = "fra eng cse dan nld fin deu ell hun ita nob
pol por ron rus spa tur" sortiesPossibles = "liste xml" url = http://www.xrce.xerox.com/About-XRCE/History/Historical-projects/XeLDA/
requeteType = "EXEC" requete = "xelda MorphoAnalysis
plaintext $fichSort $fichEnt $langSource FST FSTPOSTag"/--> …… </RESSOURCES> |
Figure 78 : Fichier de configuration des outils appelables
|
Figure 79 : Affichage d'un message d'erreur de Lextoh (lemmatiseur indisponible) |

I.3 CreatDico (12 p.)
CreatDico est un intergiciel de création de "mini-dictionnaires".
Après l'analyse morphologique d'un texte ou d'un "mot-forme", on peut recevoir les lemmes grâce à Lextoh. CreatDico permet de
fabriquer le dictionnaire pour chaque lemme de façon générique.
Cette section est
divisée en 3 sous-sections : motivations, conception globale et
expérimentation/validation. Comme pour Lextoh, les
spécifications détaillées ont été mises en annexe (voir l'Annexe 11).
I.3.1 Motivations : des besoins variés (2 p.)
I.3.1.1 Besoins des systèmes d'aide à la traduction (0,5 p.)
L'intégration des mini-dictionnaires dans les systèmes de THAM est un objectif déjà présenté et justifié dans la thèse de Huynh [Huynh, C.-P., 2010].
Pour le support des informations lexicales, on a besoin de mini-dictionnaires pour réaliser la fonction d'aide lexicale proactive. Il s'agit de "permettre à des contributeurs d'accéder pendant la post-édition à des ressources lexicales distantes de façon proactive".
La solution présentée dans [Huynh, C.-P., 2010] est le stockage d'un mini-dictionnaire associé à un segment dans la base de données, et les mini-dictionnaires sont préparés à l'avance et toujours disponibles pour la post-édition.
Définition 25. Un mini-dictionnaire contient les informations lexicales associés aux
mots d'un fragment de texte, le plus souvent un segment. (Ces informations
contiennent souvent les traductions dans une ou plusieurs langues.)
|
Figure 80 : Lecture active dans Kindle |

I.3.1.1 Besoin humain de lecture active (0,5 p.)
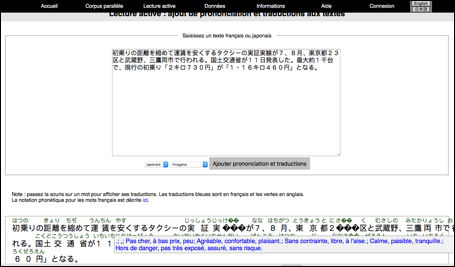
On a déjà mentionné la fonction "lecture active" au IV.2.1.2.1. Cette fonction a déjà été implémentée dans plusieurs systèmes, comme Ficus [Lafourcade, M. & Chauché, J., 1998] par M. Lafourcade, et Jibiki-Japonais→français par M. Mangeot (voir la Figure 81) [Mangeot, M., 2016], et aussi dans quelques outils comme Kindle.
Le logiciel iMAG (interactive Multilingual Access Gateway) a été développé par C.-P. Huynh en parallèle avec SECTra (voir IV.1.1.1.1) comme une extension qui en est un "frontal". Il permet de naviguer sur des sites Web dans diverses langues, et d'améliorer les prétraductions dans le contexte de lecture. iMAG a également un besoin de lecture active. Il y a aussi ce besoin pour le projet Innovalang-LexInnova (voir III.4.2), car c'est très utile pour apprendre une langue étrangère. Sans CreatDico, ces réalisations seraient faites séparément, et on devrait programmer pour chaque système et chaque couple de langues.
|
Figure 81 : Lecture active dans Jibiki-Japonais↔français |
I.3.1.2 Besoins pour des systèmes de TA (0,5 p.)
Les systèmes de TA ont besoin de dictionnaires spécialisés ; voici deux exemples.
1. Dictionnaires utilisés dans un système de TA sous Ariane-G5.
|
|
|
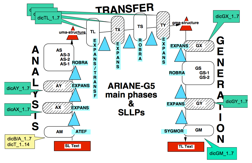

Figure 82 : Structure d'Ariane-G5 et exemples d'entrées de dictionnaires
2. Dictionnaire pour Systran (lemma-AA pour dictionnaire monolingue, et transfert-AABB pour dictionnaire bilingue).
|
Figure 83 : Exemples de dictionnaires pour Systran |

I.3.1.3 Besoins pour des outils spécialisés (0,5 p.)
Comme dit plus haut au II.2.3.1,
pour un projet comme OMNIA, on a besoin de mini-dictionnaires lemmes-UW sous forme de grammaires-Q.
I.3.2 Conception de CreatDico
I.3.2.1
Fonctionnalités désirées
Serveur. CreatDico est un serveur paramétrable d'appel de dictionnaires ou de bases lexicales pour créer les "mini-dictionnaires" (un "intergiciel de création de mini-dictionnaires").
Comme Lextoh, il fonctionne comme un service Web avec méthodes POST ou GET.
Interfaces. CreatDico a été développé
juste après l'installation de la
1ère version de Lextoh. L'interface de type formulaire a été développée à partir de celle de Lextoh (voir IV.2.2.1).
Pour l'API, la requête d'URL contient les paramètres serveur, dictionnaire, langue source, langue cible, lemmatiseur, format de sortie, texte etc., voir le paragraphe suivant (Entrées et sorties).
Outils
dictionnairiques. CreatDico permet d'accéder à plusieurs
bases lexicales et dictionnaires en ligne : Papillon-CDM, Pivax-2, IATE, Wiktionary etc.
À chaque service dictionnairique correspond un plugin.
Entrées et sorties. Les entrées de CreatDico contiennent les paramètres suivants :
·
serv : serveur de
dictionnaire.
·
dico : dictionnaire (pour le
cas de multi-dictionnaire dans un serveur, ex. Papillon-CDM[29], s'il
n'y a qu'un seul dictionnaire dans un serveur, ce paramètre n'est pas activé).
· lang : 3 caractères latins en iso 639-2.
·
lc : langue cible, 3
caractères latins en iso 639-2, plusieurs sont possibles.
·
lemmat : outil d'analyse
morphologique (choix parmi les outils disponibles sur Lextoh).
·
output : format de sortie.
· text : texte à analyser, un texte directement extrait d'un document.
·
detail : 1 ou 0, si 0 affichage
des mots-vedette en traduction, 1 affichage de tous les détails. Dans certains
types de sortie, ce paramètre n'est pas activé.
·
debug : 1 ou 0, il permet d'afficher
tous les paramètres et leurs valeurs de requête dans le composant de debug,
sur la même interface que le résultat.
·
form : 1 ou 0, si 1 affichage
de la formulaire, si 0 affichage que des résultat (API-REST).
On distingue les
sorties générales et les sorties dédiées.
Les sorties générales sont des sorties par défaut. On présente ces formats dans l'Annexe 11. Les sorties dédiées (mini-dictionnaires) sont des sorties spécifiées et filtrées par les utilisateurs (ex. SECTra, OMNIA etc.). Les formats dédiés sont réalisés par des plugins.
Il y a deux sous-types de mini-dictionnaire, un qui permet seulement la consultation, l'autre qui permet en plus de contribuer vers nos systèmes de type Pivax (en cours d'implémentation, ce n'est pas encore mis en service), dans des limites précises. Pour permettre les contributions, on a prévu d'utiliser l'API de Jibiki-2, réalisée par M. Mangeot.
Voici un exemple de mini-dictionnaire
de SECTra (seulement
la consultation).
|
<?xml version="1.0"
encoding="UTF-8"?> <!DOCTYPE SETRAMINIDICO
"SETRAMINIDICO.dtd"> <minidico> <description> <format>minidico_sectra</format> <segment>Hello
World</segment> <langueSource>eng</langueSource> <langueCible>zho</langueCible> <lemmatiseur>xip</lemmatiseur> <serv_dico>wikitionary</serv_dico> <id>demo2_doc18_seg1059</id> <date>20150705-10:59:54</date> </description> <dictionnaires> <dictionnaire>
<lemme>hello</lemme>
<traductions>
<traduction>(用于问候、接电话或引起注意)你好,喂,(用于询问所在的地方是否有人)请问 有人在吗</traduction>
<traduction>(表示惊讶)嘿</traduction>
</traductions> </dictionnaire> <dictionnaire>
<lemme>world</lemme>
<traductions>
<traduction>世界</traduction>
<traduction>地球和包括其所有的棲息生物,及位於其上的所有東西(环境) </traduction> </traductions> </dictionnaire> </dictionnaires> </minidico> |
Configurations et
autres fonctionnalités. Les
fichiers de configuration permettent de configurer les outils utilisables.
Ils permettent
également de configurer les préférences d'utilisateurs, par exemple, le lemmatiseur préféré, le service
dictionnairique préféré, etc. Avec ces fichiers de configuration, les utilisateurs
n'ont pas besoin d'envoyer tous les paramètres chaque fois. Ils
les envoient uniquement s'ils
sont différents de ceux de la configuration courante.
Comme pour Lextoh, on a réalisé les
fonctions "trace ou debug" pour le débogage, l'interface d'explication,
les exemples d'utilisation d'API et d'utilisation de
formulaire, etc.
Robustesse. Comme pour Lextoh, on utilise ActiveMQ pour la gestion des tâches et des files d'attente.
I.3.2.2
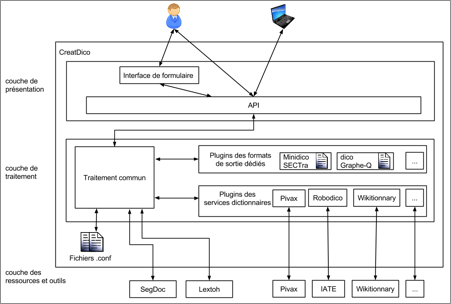
Architecture globale de CreatDico (1 p.)
|
Figure 84 : Architecture de CreatDico |
Couche de présentation. Elle permet l'interaction avec les utilisateurs humains (par formulaire ou par API) et les programmes
(par API
via le serveur d'ActiveMQ).
Couche de traitement. Il y a un module "traitement commun" et deux plugins (l'un pour les appels des dictionnaires, l'autre pour les productions des mini-dictionnaires)
dans cette couche.
Le module "traitement commun" contient les programmes principaux, qui réalisent
plusieurs étapes de traitement pour traiter les requêtes, unifier le résultat
natif des outils différents, communiquer avec les plugins, etc. Il est
également responsable de la communication avec SegDoc et Lextoh.
Si l'entrée est un grand texte (plus d'une page, 1400 octets), ce module envoie le
document à SegDoc pour qu'il le segmente.
Si l'entrée est un terme, un
segment ou un petit texte, le système l'envoie à Lextoh directement. Après avoir reçu les lemmes de Lextoh, le module "traitement commun" les envoie à un plugin de service
dictionnaire en fonction de la demande de l'utilisateur.
Chaque plugin de
service dictionnaire correspond à un outil dictionnairique. Il spécifie le
prétraitement, la méthode d'appel
et le post-traitement.
Le dernier module est le module des plugins de sortie dédiés (les mini-dictionnaires). Chaque plugin réalise un mini-dictionnaire (transformation de la sortie uniformisée vers une sortie spécifiée). Il y a un fichier de configuration pour chaque plugin. Ces fichiers mémorisent les préférences des utilisateurs, par exemple quel lemmatiseur est préféré pour quelle langue, quel dictionnaire est préféré pour quel couple de langues.
Couche des ressources et outils. Cette couche correspond aux dictionnaires externes et aux fichiers de configuration de CreatDico (ex. les services dictionnairiques et les lemmatiseurs appelables).
I.3.2.3 Utilisateurs et scénarios (3 p.)
I.3.2.3.1 Utilisateurs (1 p.)
a. Humain
|
Rôle d'utilisateur humain |
Droits |
|
Administrateur |
· Activation ou désactivation de la liste des outils appelables et de la liste de sortie dédiée par les fichiers de configuration. · Lancement du serveur. |
|
Linguiste lexicographe |
· Négociation (ex : demande d'ajouter un autre outil de service dictionnaire, demande d'une sortie particulière etc.). · Tests du fonctionnement de CreatDico. |
|
Informaticien |
· Exécution de tâches spécifiques (ex : ajout d'une nouvelle sortie dédiée). |
|
Utilisateur indirect |
· Par exemple, contribution ou évaluation sur les mini-dictionnaires via SECTra/iMAG (pas encore mis en service). |
b. Machine
|
Rôle d'utilisateur machine |
Tâches |
|
SECtra |
Demande de mini-dictionnaires. |
|
iMAG |
Demande de dictionnaires pour "lecture active". |
|
OMNIA |
Demande de mini-dictionnaires en grammaires-Q. |
|
Ariane |
Demande de dictionnaires pour des systèmes de TA. |
|
Autres |
Programmes non encore spécifiés. On pense à l'évaluation comparative de
différents services dictionnairiques. |
I.3.2.3.2 Scénarios (2 p.)
Comme pour Lextoh, les utilisations de CreatDico pourraient être nombreuses. On donne ici trois scénarios différents. Le premier est une utilisation complète, qui concerne Lextoh, CreatDico, SECTra, Pivax-2, et également ActiveMQ, avec un grand nombre de requêtes. Le deuxième est une utilisation directe sur l'interface de CreatDico. Le troisième concerne la configuration.
On montre les résultats de ces scénarios à la section suivante IV.3.3.2.
a. Scénario 1 : Un exemple complet de demande de mini-dictionnaire par SECTra (0,5 p.)
C'est une utilisation assez complète (globale)
avec plusieurs systèmes : Lextoh, CreatDico, SECTra et Pivax-2. Les appels entre les systèmes sont réalisés
par l'outil ActiveMQ. Pour
faciliter l'explication, on cache
l'utilisation d'ActiveMQ.
1. SECTra appelle CreatDico pour
demander des mini-dictionnaires pour 50 segments français vers toutes les
autres langues possibles.
2. Pour chaque segment, CreatDico appelle Lextoh avec les paramètres adéquats.
3. Lextoh appelle xip (dans la fichier
de configuration, xip est l'analyseur préféré
pour la combinaison de SECTra+français) pour réaliser l'analyse morphologique de ce segment.
4. xip renvoie le
résultat à Lextoh.
5. Lextoh produit le
format souhaité et renvoie le résultat à CreatDico.
6. CreatDico envoie les
lemmes à Pivax-2 pour consulter la base lexicale.
7. Pivax-2 envoie les
résultats sous forme de dictionnaire en html à CreatDico.
8. CreatDico regroupe les
dictionnaires associés aux différents lemmes du segment, crée la sortie en
format dédié "mini-dictionnaire
de SECTra", et le renvoie à SECTra.
On
boucle sur les étapes de 2 à 8, jusqu'à ce qu'il n'y ait plus de segment.
|
Figure 85 : Procédure de demande de mini-dictionnaires par SECTra |

b. Scénario 2 : Utilisation de formulaire par un linguiste (0,5 p.)
Il s'agit ici d'un
linguiste-informaticien ou lexicographe qui fait trois expériences en utilisant
le formulaire.
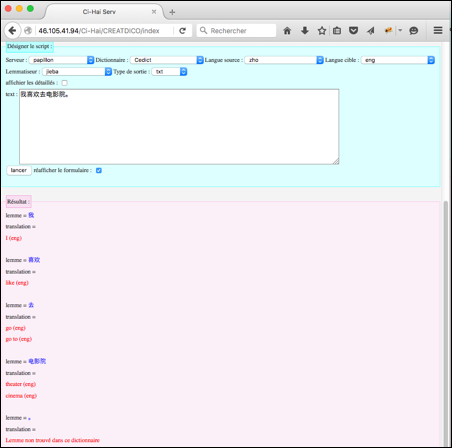
Expérience 1. Consultation d'un segment avec une langue cible produisant
une sortie simple.
1. L'utilisateur arrive à la page d'accueil de CreatDico.
2. Il remplit le formulaire avec les
paramètres suivants.
· Serveur =
papillon
· Dictionnaire
= Cedict
· langue
source = zho
· langue
cible = eng
· lemmatiseur
= jieba
· type de
sortie = txt (une
sortie générale)
·
text = 我喜欢去电影院。 (j'aime bien aller au cinéma.)
·
réafficher le formulaire = oui
3. Il clique sur le bouton "lancer".
4. La page est mise à jour et le résultat
est affiché.
Expérience 2. Consultation d'un segment avec demande des équivalents dans
plusieurs langues cible produisant une sortie simple.
1. Il modifie le formulaire avec les
paramètres suivants.
· Serveur = iate
· Dictionnaire
= iate (comme le
serveur IATE n'a pas plusieurs dictionnaires, ce champ est rempli
automatiquement après le choix du serveur.)
· langue
source = eng
· langue
cible = toutes
· lemmatiseur
= xip
· type de sortie
= txt (une
sortie générale)
· text = Hello world.
· réafficher
le formulaire = oui
2. Il clique sur le bouton "lancer".
3. La page est mise à jour et le résultat est affiché.
Expérience 3. Consultation d'un segment avec une langue cible produisant
une sortie détaillée.
1. L'utilisateur modifie le formulaire avec les paramètres suivants.
· Serveur =
papillon
· Dictionnaire
= Cedict
· langue
source = eng
· langue
cible = zho
· lemmatiseur
= delaf
· type de
sortie = txt (une
sortie générale)
· afficher
les détaillés = oui (une sortie générale détaillés)
·
text = Hello world.
·
réafficher le formulaire = oui
2. Il clique sur le bouton "lancer".
3. La page est mise à jour et le résultat est affiché.
c. Scénario 3 : Configuration des outils appelables disponibles et modification des préférences d'une sortie dédiée par l'administrateur (0,5 p.)
Il s'agit de deux niveaux de configuration.
(1) Configuration de CreatDico : l'administrateur modifie les outils disponibles par les fichiers de configuration.
(2) Configuration d'un plugin de sortie spécifique : l'administrateur modifie le lemmatiseur préféré pour les mini-dictionnaires de SECTra.
1.1. L'administrateur ouvre le fichier conf_ressource.xml.
1.2. Il désactive le service IATE (en mettant la description d'IATE en commentaire).
2.1. Il ouvre le fichier conf_minidico_Sectra.xml.
2.2. Il modifie le serveur préféré serveur_pref = Pivax pour la demande de mini-dictionnaire de fra→eng.
I.3.3 Expérimentation et validation (3,5 p.)
I.3.3.1 Interface principale et disponibilité
Comme Lextoh, la version interne est installée sur le serveur danang.imag.fr du GETALP pour tests et développements. Elle ne permet pas l'accès depuis Internet.
La version publiée
est installée sur http://46.105.41.94/Ci-Hai/CREATDICO. Le formulaire est
similaire à celui de Lextoh. Il y a 5 composants : Explications, Trace,
Désigner le script, Résultat et Exemples. On affiche seulement le composant "Désigner
le script" ici. Pour le formulaire complet, voir la Figure 75.
|
Figure 86 : Composant "Désigner le script" d'interface CreatDico |
I.3.3.2 Tests fonctionnels (2 p.)
I.3.3.2.1 Demande de mini-dictionnaires par SECTra (résultat du scénario 1) (1 p.)
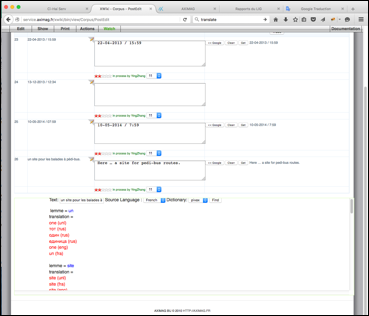
Le temps de réponse est acceptable. On a pris environ 4,5 minutes sans erreur pour le scénario 1 (50 segments français vers toutes les autres langues, voir IV.3.2.3.2a). L'interface de SECTra est montrée dans la Figure 87. Ici, le mini-dictionnaire est grand, c'est pourquoi L. X. Wang a implémenté un ascenseur dans le composant d'affichage.
|
Figure 87 : Mini-dictionnaire (multicible) intégré dans SECTra pour le segment "un site pour les balades à pédi-bus." |
I.3.3.2.2 Utilisation du formulaire par un linguiste (résultat de scénario 2) (1 p.)
a. Résultat de l'expérience 1
Nous avons déjà montré le résultat de l'expérience 1 (consultation d'un segment avec une langue cible produisant une sortie simple) dans la Figure 86.
b. Résultat de l'expérience 2
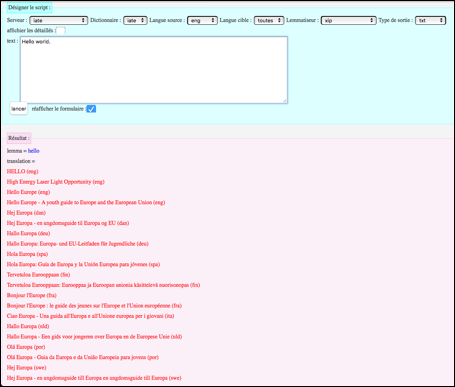
Le résultat de l'expérience 2 est présenté dans la Figure 88.
|
Figure 88 : Consultation d'un segment en "multicible", produisant une sortie simple |
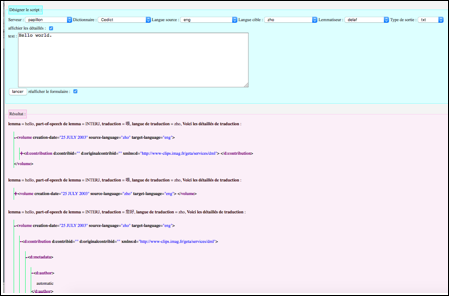
c. Résultat de l'expérience 3
Le résultat de l'expérience 3 est montré dans la Figure 89. Pour chaque traduction, la sortie "détaillée" en Xml permet de décrire toutes les informations qu'on peut trouver, par exemple, la date de création, l'auteur, l'origine, les exemples, les définitions, les catégories grammaticales, les prononciations etc.
C'est une sortie bien informatisée et bien uniformisée. Toutes les sorties dédiées sont réalisées à partir de cette sortie "détaillée" par des programmes simples (plugins). Il s'agit principalement du filtrage, du renommage des balises pour obtenir un nouveau mini-dictionnaire de format Xml, de la transformation de Xml vers d'autres formats (ex. Json, tsv, ou une nouvelle structure de Xml etc.).
Pour un segment, cette sortie "détaillée" pourrait être très longue. Notre interface permet d'ouvrir ou de fermer les nœuds Xml de n'importe quel type en utilisant les boutons "+" ou "-" devant des balises.
|
Figure 89 : Consultation d'un segment avec une langue cible produisant une sortie détaillée |
I.3.3.2.3 Configuration de CreatDico et de plugin (résultat de scénario 3)
a. Résultat d'expérience 1
Après la désactivation de IATE, IATE n'est plus contenu dans la liste des serveurs de dictionnaires affichée sur l'interface. On ne peut plus l'utiliser. Si on demande les services sur l'API, le système envoie un message d'erreur (serveur/dictionnaire indisponible).
|
<?xml version="1.0"
encoding="UTF-8" standalone="yes"?> <RESSOURCES dateCreation = "20140222" dateDerniereModif = "20151207" Auteur = "Ying" Accessible = "Public"> <!-- Services dictionnairiques--> <SERVEURS> <SERV codeServ = "Papillon" codeEnt = "utf8" callType="API" url = "http://www.papillon-dictionary.org/papillon/api/$dico/$lang/cdm-headword/$headword/cdm-translation?strategy=EQUAL" />
<SERV codeServ = "Pivax" codeEnt = "utf8" callType="API" url = "http://getalp.imag.fr/pivax/api/$dico/$lang/link/manger?strategy=EQUAL" />
<!-- Désactivation d'IATE, Test de configuration
-- > <!-- SERV codeServ = "IATE" codeEnt =
"utf8" callType="EXEC" url = "
http://iate.europa.eu" requete="php -f Robodico.PHP LS=$lang LC=$lc
lemme=$text" /-->
…… </SERVEURS> </RESSOURCES> |
Figure 90 : Fichier de configuration des dictionnaires appelables
b. Résultat d'expérience 2
Après la modification du dictionnaire préféré pour les mini-dictionnaires de SECTra, si aucun dictionnaire n'est spécifié dans la requête, CreatDico prend le nouveau dictionnaire préféré.
|
<!-- configuration de Mini-dictionnaire de Sectra
-- > <MINIDICO name="sectra" dateCreation = "20140225" dateDerniereModif = "20160205" Auteur = "Ying" Accessible = "Public"> <!-- lemmatiseur préféré pour chaque langue
--> <Lemmatisation ls = "eng" lemmat = "xip"/> <Lemmatisation ls = "zho" lemmat = "jieba"/> <Lemmatisation ls = "fra" lemmat = "delaf"/> <Lemmatisation ls = "rus" lemmat = "ariane-heloise"/> …… <!-- Service dictionnairique préféré par couple
de langue --> <Dico ls = "eng" lc = "zho" serv = "pivax" dico = "" /> <Dico ls = "zho" lc = "eng" serv = "papillon" dico = "Cedict" /> <Dico ls = "eng" lc = "fra" serv = "pivax" dico = "" /> <Dico ls = "fra" lc = "eng" serv = "pivax" dico = "" /> …… </MINIDICO>
|
Figure 91 : Fichier de configuration de plugin
de mini-dictionnaires de Sectra