Gestion des consommations de café
Objectifs: Ce TP a pour but de vous familiariser avec
l'API JDBC (package
java.sql de
l'API JavaSE),
vous aborderez ainsi les points suivants :
Contexte
Considérons le scénario suivant :
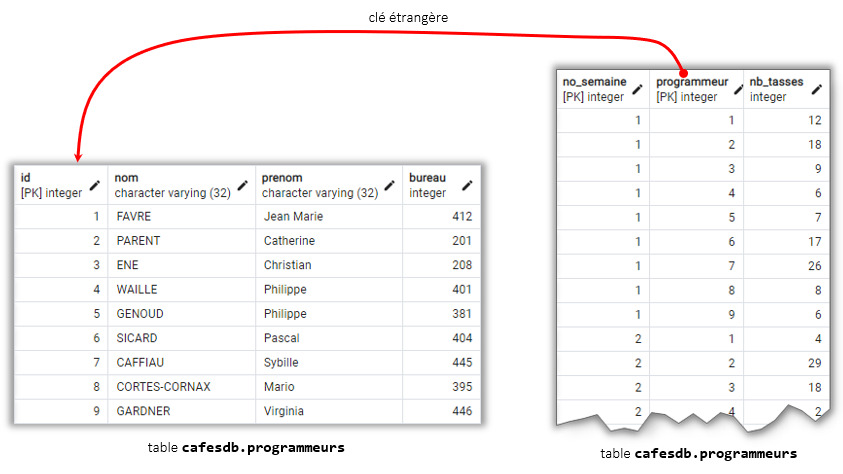
Il s'agit d'écrire une application Java permettant de suivre la consommation de café des programmeurs d'un projet de développement logiciel. Chaque semaine, le chef de projet relève le nombre de tasses de café consommées par les différents programmeurs. Ces informations seront stockées dans deux tables d'une base de données relationnelle (en l'occurence SQLite):
- programmeurs qui stocke les informations d'identification de chaque programmeur du projet,
- consos_cafe qui stocke les consommations de café semaine par semaine des différents programmeurs.
La structure de ces tables est la suivante :
1. Préparation de l'environnement pour le TP
Dans un premier temps vous allez récupérer le code des projets Java sur lesquels vous allez travailler durant ce TP et vérifier le bon fonctionement de la base de données.
1. Récupération du projet TP14_JDBC
Etape 1: Téléchargez le fichier TP14_JDBC.zip que vous décompresserez dans votre répertoire de travail POOJava. Un répertoire TP14_JDBC a été créé et contient les répertoires et fichiers suivants :

2. Vérification du bon fonctionnement de SQLite
Maintenant que vous avez récupéré le code du TP et vérifié que le projet MyFirstJDBCApp compile et s'exécute correctement, vous allez tester le bon fonctionnemeent de SQLite.
Etape 2:
-
Ouvrez un terminal dans le dossier database du projet MyFirstJDBCApp
-
En utilisant l'interpréteur de commandes SQLite, vérifiez que les tables sont bien accessibles (en jaune les commandes à rentrer. Pour avoir de l'aide sur les commandes disponibles taper .help dans l'interpréteur de commandes SQLite)
~/POOJava/TP14/MyFirstJDBCApp/databases>sqlite3 cafesdb.db # ouvre interpréteur de commandes SQLite sur la base de données cafes.db SQLite version 3.49.0 2025-02-06 11:55:18 Enter ".help" for usage hints. sqlite>.tables # affiche la liste des tables CONSOS_CAFE PROGRAMMEURS sqlite>.schema PROGRAMMEURS # donne le schéma de la table programmeurs CREATE TABLE PROGRAMMEURS ( ID INT NOT NULL, NOM VARCHAR(32), PRENOM VARCHAR(32), BUREAU INT, PRIMARY KEY (ID) ); sqlite> SELECT * FROM PROGRAMMEURS ORDER BY NOM; # liste le contenu de la table programmeurs 7|CAFFIAU|Sybille|445 8|CORTES-CORNAX|Mario|395 3|ENE|Christian|208 1|FAVRE|Jean Marie|412 9|GARDNER|Virginia|446 5|GENOUD|Philippe|381 2|PARENT|Catherine|201 6|SICARD|Pascal|404 4|WAILLE|Philippe|401 sqlite>.quit # quitte l'interpréteur de commandes SQLite ~/POOJava/TP14/MyFirstJDBCApp/databases> -
Si SQLite 3 n'est pas installé sur votre poste de travail l'installer (le site offciel de SQLite : https://www.sqlite.org/index.html)
2. Ecriture d'un premier programme JDBC
Avant de vous interesser au programme de gestion des consommations de café proprement dit, vous allez écrire un premier programme permettant simplement de lire le contenu de la table programmeurs et de l'afficher sur la console.
Exercice 2.1 : Ouvrir une connexion JDBC
-
Dans le répertoire TP14_JDBC ouvrez avec VS Code l'espace de travail TP14_JDBC.code-workspace
-
Modifier la méthode main de la classe Java App afin qu'elle contienne le code suivant :
public static void main(String[] args) { try ( Connection conn = DriverManager.getConnection("../databases/cafesdb.db") ) { System.out.println("\nConnexion réussie !"); // à compléter plus tard // ... } catch (SQLException ex) { System.out.println("Erreur SQL " + ex.getMessage()); ex.printStackTrace(); } System.out.println("\nConnexion réussie !\n"); } -
Exécutez ce programme et constatez qu'il provoque une erreur (SQLException)

Erreur d'exécution de l'application Java D'après vous quelle est la cause de cette erreur et que faut-il faire pour la corriger ?
Le pilote (driver) JDBC pour SQLite n'a pas été trouvé, en effet il faut que le fichier .jar du pilote soit dans le classpath de l'application au moment de l'exécution. Pour ce type de projet créé sans outils de construction de projet (build tools tels maven ou gradle), il faut rajouter un pilote jdbc pour SQLite dans le répertoire lib, l'Extension Pack For Java de VS Code se chargeant ensuite de l'inclure au classpath.
Pour trouver un pilote JDBC, vous pouvez vous rendre sur la page github du projet sqlite-jdbc.


ajout d'une dépendance maven au pilote PostgreSQL JDBC -
Après avoir enregistré le pilote JDBC de SQLite, réexécutez à nouveau l'application App. Vous devriez avoir un nouveau message d'erreur comme sur la capture d'écran ci-dessous.

A votre avis quelle est la cause de cette seconde erreur ? En quoi est-elle différente de la première ? Que faut-il corriger dans votre code ?
-
Une fois l'erreur précédente corrigée, vérifiez que le programme s'execute correctement. Vous devriez obtenir m'affichage suivant

Exécution de l'application Java : la connexion à la base de données a pu être établie
Exercice 2.2 : complétez le programme pour qu'il affiche le contenu de la table programmeurs par ordre alphabétique des noms.

Une fois l'objet connexion obtenu, créez à l'aide de celui ci un objet
Statement
et utilisez la méthode executeQuery de celui-ci pour effectuer la requête
SQL
SELECT.
Cette méthode retourne les résultats sous la forme de lignes de données encapsulées
dans un objet
ResultSet. Parcourez ce résultat
ligne par ligne en utilisant les méthodes next()
et getXXX() de l'interface ResultSet.
3. L'application GestionCafes
La base données ayant été installée, un premier programme simple vous ayant permis de comprendre le fonctionnement de base du JDBC, il est maintenant temps de passer à la réalisation d'une application de gestion des consommations de cafés qui permettra :
- d'effectuer des requêtes pour connaître :
- le programmeur ayant consommé le plus de cafés sur une semaine,
- le nombre total de tasses consommées par un programmeur donné,
- les consommations de tous les programmeurs pour une semaine donnée,
- l'ensemble des consommations hebdomadaires d'un programmeur donné,
- de saisir les consommations pour une semaine donnée,
- d'effectuer une requête quelconque,
- d'exporter des données vers un fichier texte (CVS),
- d'importer des données depuis un fichier texte (CSV).
3.1 Configurer le projet GestionCafés
Exercice 3.1 :
-
Rajouter le projet à votre espace de travail TP14_JDBC.

Ajout du projet GestionCafé à l'espace de travail TP14_JDBC -
Dans l'exercice précédent vous avez vu qu'il fallait intégrer un pilote JDBC dans le classpath de l'application pour pouvoir accéder à la base de données. Le projet gestion-cafes étant un projet Maven comment procéder ?
Ici, comme le projet est géré avec maven, il suffit de rajouter une dépendance vers un pilote jdbc pour SQLite. Maven se chargera de télécharger le fichier .jar et ensuite de l'inclure au classpath.
Pour trouver cette dépendance, vous pouvez vous rendre sur maven repository https://mvnrepository.com et faire une recherche avec les termes PostgreSQL jdbc driver.

ajout d'une dépendance maven au pilote JDBC pour SQLite -
Parcourez le code du projet pour comprendre l'organisation de l'application et le rôle des classes des différents packages qui la constituent.

organisation du projet Le modèle de données qui sert à représenter sous forme d'objets Java les données stockées en BD est présenté sur la figure ci dessous. Ces classes servent d'intermédiare entre l'application et la couche de persistance des données.

modèle de données -
Vérifiez que le programme principal contenu dans la classe GestionCafes compile et s'exécute correctement.
Le programme principal (méthode statique main) a la structure suivante:
Ouvrir une connexion JDBC. répéter afficher un menu proposant différentes opérations à l'utilisateur saisir le choix de l'utilisateur effectuer l'opération choisie tant que l'utilisateur veut continuer Fermer la connexionPour le moment, aucune des opérations liés à la base de données (ouverture et la fermeture de la connexion, requêtes SQL, affichage des résultats) ne sont implémentées. Cela sera à vous de le faire dans les exercices suivants.
3.2 Compléter et tester les classes du modèle
Exercice 3.2.1 : Refactoring de la classe Consommation
La classe Consommation est, elle, complètement implémentée, mais n'y aurait pas moyen de simplifier drastiquement son code ? Si oui faites le !
Par ailleurs écrivez du code JUnit pour la tester
Exercice 3.2.2 : Implémenter la classe Programmeur
Seul le squelette de la classe Programmeur a été implémentée et là aussi aucun programme de test n'a été écrit.
Complétez le code de cette classe conformément au model UML donné précédemment et aux commentaires documentants présents dans le code source de la classe et créez un programme de tests unitaires que vous compléterez au fur et à mesure de l'écriture de la classe Programmeur.
3.3 : Rechercher de l'information dans la base de données
L'application GestionCafes permet à l'utilisateur de consulter les informations suivantes:
-
le ou les programmeurs ayant consommé le nombre maximum de cafés en une semaine et leur consommation totale pour cette semaine.
exemple d'exécution de cette requête dans le programme GestionCafes (surlignées en jaune les réponse de l'utilisateur)
------------------------------------------ 1 : Plus gros consommateurs sur une semaine 2 : Nombre total de tasses consommées par un programmeur 3 : Consommations pour une semaine donnée 0 : Quitter l'application votre choix : 1 Le plus gros consommateur de cafés sur une semaine est : Catherine PARENT sa consommation est de 29 tasses de café la semaine 1Une requête SQL permettant de récupérer cette information est
SELECT programmeur,prenom,nom,nb_tasses,no_semaine FROM consos_cafe c JOIN programmeurs p ON p.ID=c.programmeur WHERE c.nb_tasses=(SELECT MAX(nb_tasses) FROM consos_cafe) -
pour un programmeur donné le nombre total de tasses de café consommées.
exemple d'exécution de cette requête dans le programme GestionCafes
------------------------------------------ 1 : Plus gros consommateurs sur une semaine 2 : Nombre total de tasses consommées par un programmeur 3 : Consommations pour une semaine donnée 0 : Quitter l'application votre choix : 2 Nom du programmeur : SICARD Pascal SICARD a consommé un total de : 148Une requête SQL permettant de récupérer cette information est
SELECT SUM(nb_tasses),nom,prenom FROM consos_cafe c JOIN programmeurs p ON p.ID=c.programmeur WHERE p.nom='SICARD' GROUP BY nom,prenom -
pour une semaine donnée la liste des programmeurs triée dans l'ordre décroissant selon leur nombre de consommations.
exemple d'exécution de cette requête dans le programme GestionCafes
------------------------------------------ 1 : Plus gros consommateurs sur une semaine 2 : Nombre total de tasses consommées par un programmeur 3 : Consommations pour une semaine donnée 0 : Quitter l'application votre choix : 3 Numéro de la semaine : 2 Programmeur Catherine PARENT : 29 Programmeur Virginia GARDNER : 22 Programmeur Pascal SICARD : 19 Programmeur Christian ENE : 18 Programmeur Philippe GENOUD : 11 Programmeur Sybille CAFFIAU : 6 Programmeur Jean Marie FAVRE : 4 Programmeur Mario CORTES-CORNAX : 3 Programmeur Philippe WAILLE : 2 Le nombre total de tasses consommé la semaine 2 est 114Une requête SQL permettant de récupérer cette information est
SELECT programmeur, prenom, nom, nb_tasses FROM consos_cafe c JOIN programmeurs p ON c.programmeur=p.ID WHERE c.no_semaine=2 ORDER BY nb_tasses DESC
Exercice 3.3.1 : Complétez le code de l'application pour réaliser les traitements précédents. Le code JDBC pour effectuer les requêtes doit être dans la classe CafeDAO. Le programme principal se charge uniquement d'ouvrir la connexion à la BD, d'invoquer les méthodes de CafeDAO et d'afficher leur résultats.
 slides du cours consacrés à
l'ouverture d'une connexion JDBC
slides du cours consacrés à
l'ouverture d'une connexion JDBC
-
Pour le traitement correspondant au choix 1 (Plus gros consommateurs sur une semaine) vous pouvez créer un objet de type Statement puis utiliser sa méthode executeQuery(String sql) en passant en paramètre la chaîne de caractères correspondant à la requête SELECT. Cette méthode retourne des résultats sous la forme de lignes de données dans un objet ResultSet. Les résultats sont examinés ligne par ligne en utilisant les méthodes next() et getXXX() de l'interface ResultSet.
-
Pour les traitements correspondants aux choix 2 et 3 (Nombre total de tasses consommées par un programmeur et Consommations pour une semaine donnée) vous créerez un objet de type PreparedStatement puis utiliserez ses méthodes setInt(int parameterIndex, int x) ou setString(int parameterIndex, String x) pour fixer la valeur des paramètres fournis par l'utilisateur. Vous pourrez ensuite executer la réquête avec la méthode executeQuery() qui retourne des résultats sous la forme de lignes de données dans un objet ResultSet. Les résultats sont examinés ligne par ligne en utilisant les méthode next() et getXXX() de l'interface ResultSet.
slides du cours consacrés
aux prepared Statements
Exercice 3.3.2 :
Ajoutez à l'application une fonctionnalité qui permet d'afficher toutes les consommations de café d'un programmeur donné triées par numéro de semaine croissant .
3.4 : Insérer des informations dans la base de données
On souhaite ajouter à l'application GestionCafes une fonctionnalité permettant à l'utilisateur de saisir et d'enregistrer dans la base de données les consommations des programmeurs pour une semaine donnée.
Le programme permet de saisir un numéro de semaine et ensuite pour chaque programmeur qui n'a pas déjà de consommation pour cette semaine de rentrer le nombre de tasses qu'il a consommées durant celle-ci.
exemple d'exécution de cette requête dans le programme GestionCafes
------------------------------------------
1 : Plus gros consommateurs sur une semaine
2 : Nombre total de tasses consommées par un programmeur
3 : Consommations pour une semaine donnée
4 : Saisie des consommations pour une semaine
0 : Quitter l'application
votre choix : 4
Numéro de la semaine : 9
nbre de tasses pour Jean Marie FAVRE (1) : 4
nbre de tasses pour Catherine PARENT (2) : 2
nbre de tasses pour Christian ENE (3) : 6
nbre de tasses pour Philippe WAILLE (4) : 0
nbre de tasses pour Philippe GENOUD (5) : 3
nbre de tasses pour Pascal SICARD (6) : 8
nbre de tasses pour Sybille CAFFIAU (7) : 7
nbre de tasses pour Mario CORTES-CORNAX (8) : 1
nbre de tasses pour Virginia GARDNER (9) : 4
Exercice 3.4.1 : Modifiez l'application GestionCafes afin d'implémenter cette fonctionnalité d'insertion de données dans la base.
une requête SQL permettant pour une semaine donnée de trouver tous les programmeurs pour lesquels aucune consommation n'est enregistrée est
SELECT ID, prenom, nom FROM programmeurs
WHERE ID NOT IN (SELECT programmeur FROM consos_cafe WHERE no_semaine = numsem ) ORDER BY IDoù numSem est le numéro de la semaine concernée.
une requête SQL permettant d'enregistrer la consommation d'un programmeur est
INSERT INTO consos_cafe (no_semaine, programmeur, nb_tasses)
VALUES(numSem, idProg, nbTasses)où
numSemest le numéro de la semaine concernée.idProgest l'identifiant du programmeur.nbTassesest le nombre de tasses qu'il a consommée durant cette semaine.
Pour exécuter les instructions SQL INSERT depuis le code Java, utilisez la méthode executeUpdate() d'un objet PreparedStatement qui retourne un entier (le nombre de lignes modifiées dans la table).
3.5 : Effectuer une requête libre et obtenir la méta information sur les types de données du résultat
L'application GestionCafes offre à l'utilisateur la possibilité d'exécuter n'importe quelle requête SQL qu'il peut entrer directement au clavier. Le résultat affiché dépendra de la nature de la requête.
- Si la requête est type
SELECTles informations suivantes sont affichées:- le nombre de colonnes de la table résultat est affiché,
- pour chaque colonne, son nom et le type des données est affiché,
- le contenu de la table est affiché ligne par ligne.
Par exemple, si la requête est :SELECT * FROM programmeurs ORDER BY IDle résultat affiché sera :
alors que la requête :le résultat contient 4 colonnes -------------------------------- Colonne : 1 nom ID TYPE : INT -------------------------------- Colonne : 2 nom nom TYPE : VARCHAR -------------------------------- Colonne : 3 nom prenom TYPE : VARCHAR -------------------------------- Colonne : 4 nom BUREAU TYPE : INT -------------------------------- Résultats de la requête 1 FAVRE Jean Marie 412 2 PARENT Catherine 201 3 ENE Christian 208 4 WAILLE Philippe 401 ...SELECT SUM(nb_tasses) FROM consos_cafe WHERE no_semaine = 1conduira à l'affichage suivant :
le résultat contient 1 colonne -------------------------------- Colonne : 1 nom SUM(nb_tasses) TYPE : INTEGER -------------------------------- Résultats de la requête 84 -
Sinon (la requête correspond à un
UPDATE,INSERT,DELETE,DROP TABLE,CREATE TABLE, ..) le résultat affiché est alors le nombre de lignes modifiées dans la table concernée.
Par exemple, si la requête est :
le résultat affiché sera :INSERT INTO consos_cafe(no_semaine, programmeur, nb_tasses) VALUES (41,2,10)Mise à jour de la base effectuée Nombre de lignes modifiées : 1
Exercice 3.5.1 : Modifiez le code de la méthode
requeteLibreEtMetaDonnees()
de la classe GestionCafes afin d'implémenter les opérations permettant de
supporter ces requêtes libres.
Pour exécuter une requête SQL libre depuis le code Java, vous utiliser la méthode execute() d'un objet Statement qui retourne un booléen de valeur true si la requête est de type SELECT, de valeur false sinon.
Si la requête a produit un ResultSet, vous devrez utiliser les méta-données de celui-ci (classse ResultSetMetaData) pour obtenir les descriptions des colonnes.
slides du cours consacrés aux méta
données et aux requêtes libres
3.6: Import/Export des données (Batch Updates)
Avant de disposer de l'application GestionCafes le manager utilisait un tableur pour saisir les consommations de cafés. Afin de lui permettre de continuer à utiliser éventuellement son outil préféré, on souhaite doter l'application GestionCafes d'une fonctionnalité d'import/export depuis/vers des fichiers textes au format CSV (Comma Separated Values, fichiers textes où les valeurs sont séparées par des virgules).
L'import/export se fait sur la base des tables de la base de données : à une table correspond un fichier. La figure ci dessous montre l'exemple de l'export des données des tables programmeurs et consos_cafe
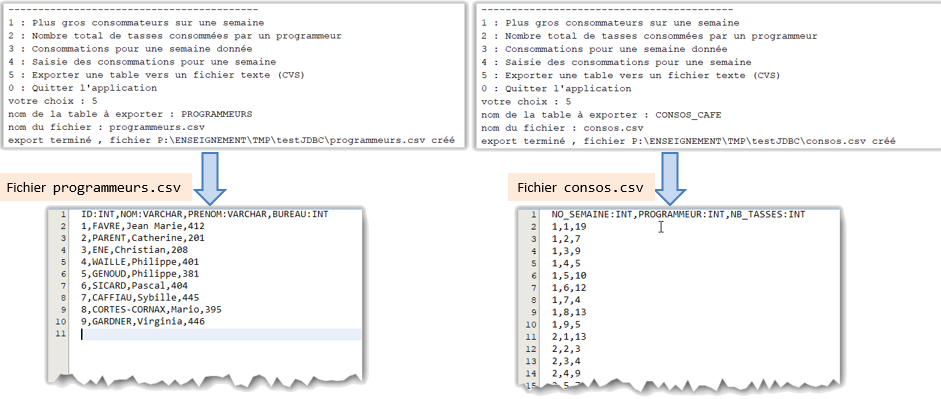
Le format des fichiers CSV est le suivant :
-
La première ligne contient les descriptions des colonnes de la table sous la
forme NomDeLaColonne:TypeSQLDeLaColonne séparées par des virgules.
Par exemple pour la table programmeurs on aura :
ID:INT,nom:VARCHAR,prenom:VARCHAR,BUREAU:INT -
Les lignes suivantes contiennent les valeurs des enregistrements présents dans
la table, valeurs séparées par des virgules. Par exemple un enregistrement dans
la table programmeurs sera écrit sous la forme :
1,FAVRE,Jean Marie,412
Exercice 3.3.1 : Modifiez la classe TableReaderWriter et le programme principal GestionCafes pour implémenter la fonctionnalité permettant d'exporter les données d'une table vers un fichier texte au format CSV.
La requête pour récupérer les données d'une table ne pose pas de problème (la sortie étant un fichier texte, on peut appliquer la méthode getString() sur chacune des colonnes du ResultSet). La seule 'difficulté' consiste à récupérer les noms et les types des colonnes pour produire la première ligne du fichier. Pour cela vous disposez d'un objet ResultSetMetaData que vous pouvez obtenir via le ResultSet.
Exercice 3.3.2 : De manière symétrique, modifiez la classe TableReaderWriter et le programme principal GestionCafes pour implémenter la fonctionnalité d'import des données à partir des fichiers texte au format CSV
L'opération d'import consiste à effacer le contenu d'une table cible, et de le remplacer par les données d'un fichier .csv. Le fichier .csv est ouvert en lecture et pour chaque ligne lue une opération d'insertion correspondante est réalisée dans la base de données.
Pour effectuer les test d'import deux fichiers de données ont été créés
progs.csvpour la liste des programmeurs,consos.csvpour la liste des programmeurs.
Le nombre de données étant relativement important (1612 lignes pour
consos.csv), pour des raisons d'efficacité il vous est recommandé
d'utiliser des Batch Updates plutôt que de faire les insertions avec de simple objets
Statement
et des messages executeUpdate() (pour en savoir plus, voir le cours JDBC
transparents 41 et 42).
slides du cours consacrés aux
BatchUpdates