Les objectifs de cette scéance de TP est d'expérimenter avec les API de programmation du framework Apache JENA (APIs core et ARQ), d'explorer le serveur SPARQL de Jena Fuseki et d'aller plus en avant dans l'utilisation de SPARQL, en particulier avec les requêtes fédérées et les requêtes de mise à jour.
1. Jena Core API
Dans les TP précédents il vous avait été proposé d'écrire des programmes Java permettant de:
-
Générer un jeu de données RDF à partie des données CSV d'Artemis Bookstore
-
Interroger les données RDF à l'aide du programme Java et de l'API core de Jena.
-
Lier les données d'Artemis Bookstore avec celles de DBPedia.
Ces programmes sont regroupés dans un projet Java maven accessible depuis GitHub: ArtemisBookStore.
Exercice 1: Clonez ou téléchargez ce projet et étudiez son contenu.

Une fois le projet téléchargé recréez les données RDF pour Artemis Bookstore
-
A l'aide du programme
GenerateBookStoreGraphcréez le graph RDF à partir des données CSV (exercice 5 du TP1). -
Une fois le graphe créé, enrichissez le en créeant des liens vers DBpedia.
- Récupérez les URIs et les noms des écrivains américains dans DBpedia (exercice 3.a du TP2)
-
A l'aide du programme
DBpediaMatchingcréer des liensowl:sameAsentre les écrivains d'Artemis BookStore et les écrivains de DBpedia. (exercice 3.b du TP2)
Exercice 2: Le programme ListBooks.java n'est pas terminé. Il
permet simplement de retrouver
un écrivain à partir de son nom et éventuellement son prénom. Complétez-le en utilisant
l'API Jena Core, afin que, une
fois le nom de l'écrivain saisi, soit affichée, si l'écrivain existe, la liste
des livres qu'il a écrit.
Exercice 3:
a) En plus de liens vers DBpedia on voudrait avoir les liens vers wikidata dont les données
sont
plus 'rigoureuses', modifiez la requête dbpediaAmericanWriters.rq qui a permit
de créer le fichier
dbpediaAmericanWriters.csv utilisé pour lier les données de Artemis BookStore à
DBpedia pour
récuperer en plus l'URI de la ressource wikidata associée.
Exécutez cette requête dans le sparql endpoint de Dbpedia et récupérez le résultat sous la
forme d'un fichier csv.
Solution
b) modifiez le programme de matching, pour créer en plus des liens owl:sameAs
vers DBpedia,
des liens owl:sameAs vers wikidata.
2. Utilisation de fuseki
a) installation
Attention: Au 14/10/2020 la version disponible de Fuseki est la 3.16.0. Elle nécessite un version de Java 8+.
site web: http://jena.apache.org/documentation/fuseki2/index.html
Pour l'installation du serveur FUSEKI procédez comme suit
1) Télecharger FUSEKI
Sur la page de téléchargement de Jena téléchargez le serveur FUSEKI et décompressez le fichier correspondant (.tar.gz ou .zip).

2) Démarer le serveur Fuseki
-
Dans un terminal, placez vous sur le répertoire
apache-jena-fuseki-3.x.xoù vous avez décompressé jena-fuseki -
Exécutez le script
fuseki-server
3) Vérification du bon fonctionnement de fuseki
Pour verifier le bon fonctionnement de Fuseki, tapez l'url http://localhost:3030
dans
votre navigateur. Vous devez obtenir une page similaire à celle affichée dans la figure
ci-dessous.
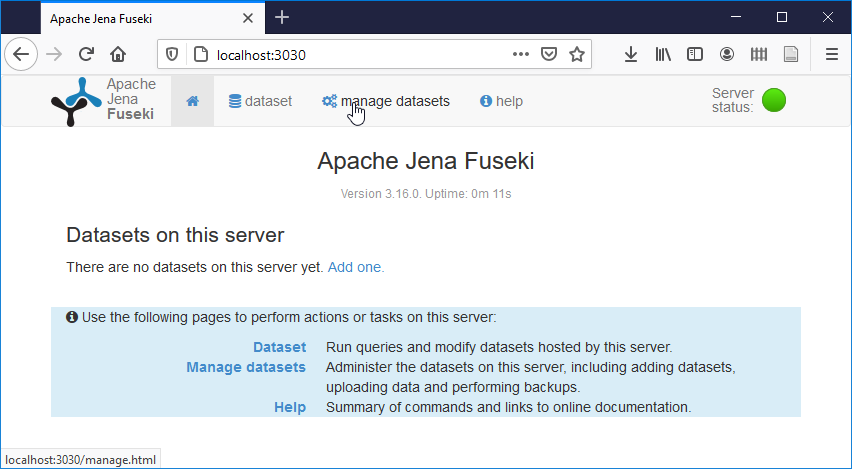
4) Charger un jeu de données
Vous allez maintenant charger vos données dans fuseki
1) sélectionnez l'onglet manage datasets
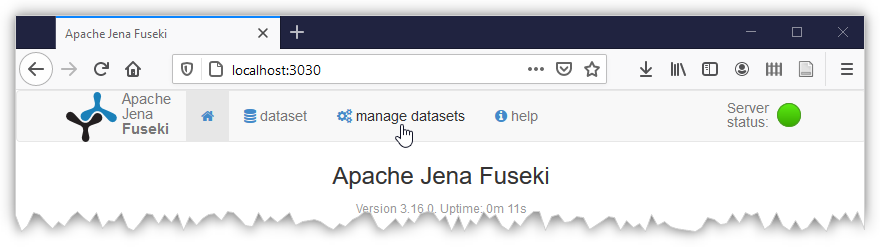
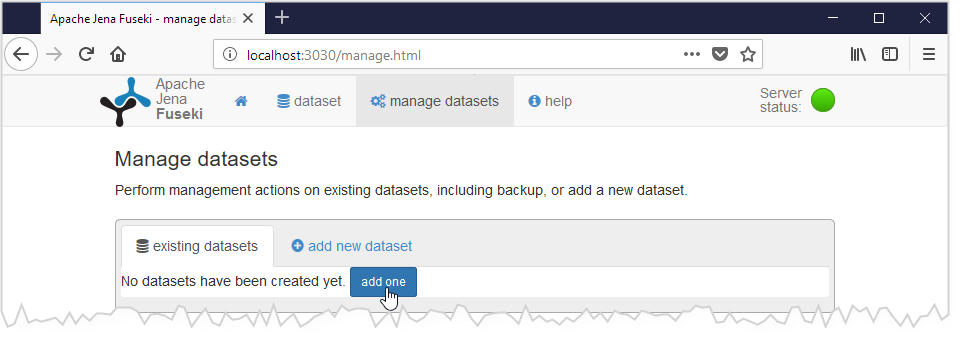
2) créez un nouveau dataset qui contiendra vos données
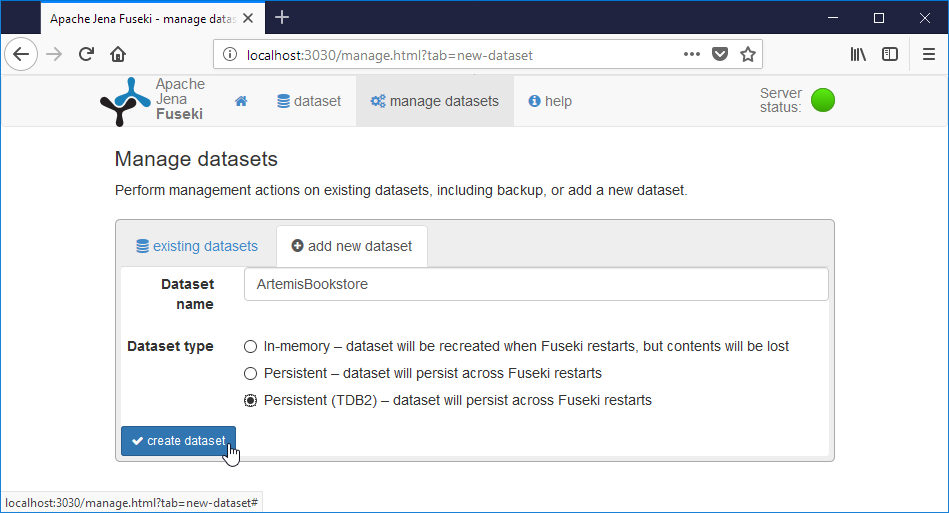
Nommez votre dataset et sélectionnez un dataset de type persistent (TDB2).
3) Chargez vos données dans le triplestore
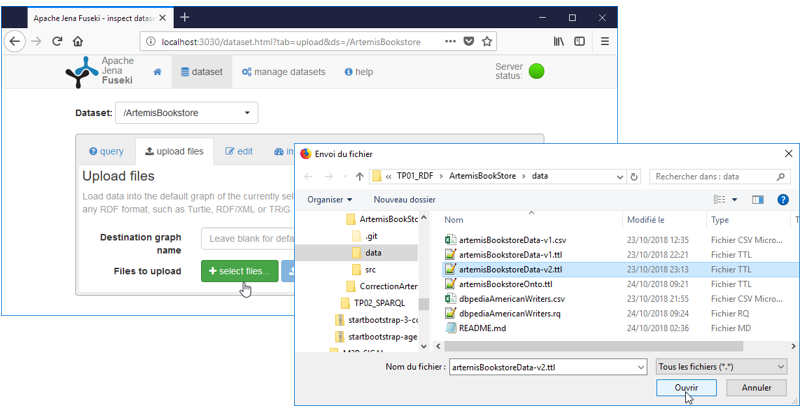
Sélectionnez le fichier RDF (au format turtle, XML/RDF ou JSON-LD) contenant vos données
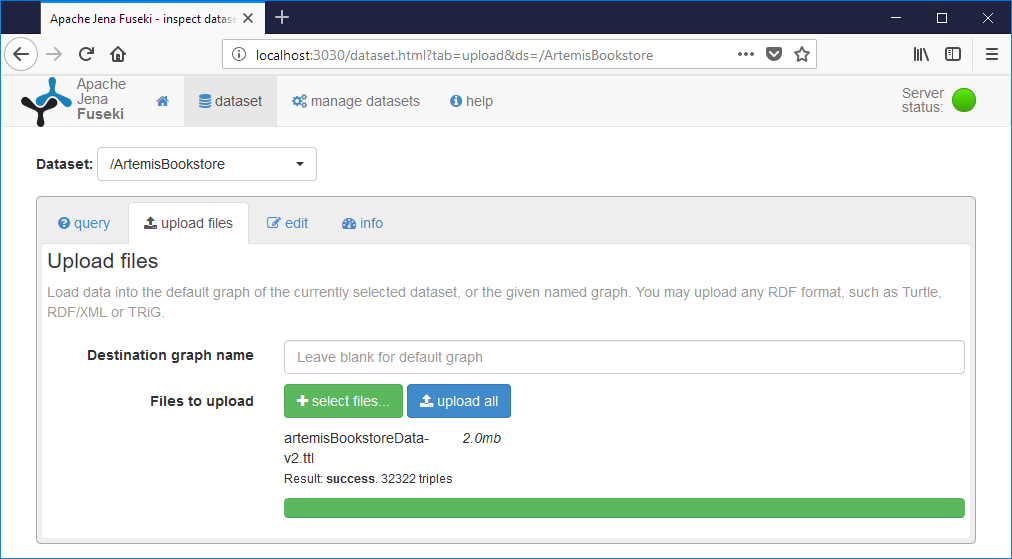
Lancez le chargement du fichier

Si le chargement a pu s'effectuer correctement une barre verte apparaît sous votre fichier de données.
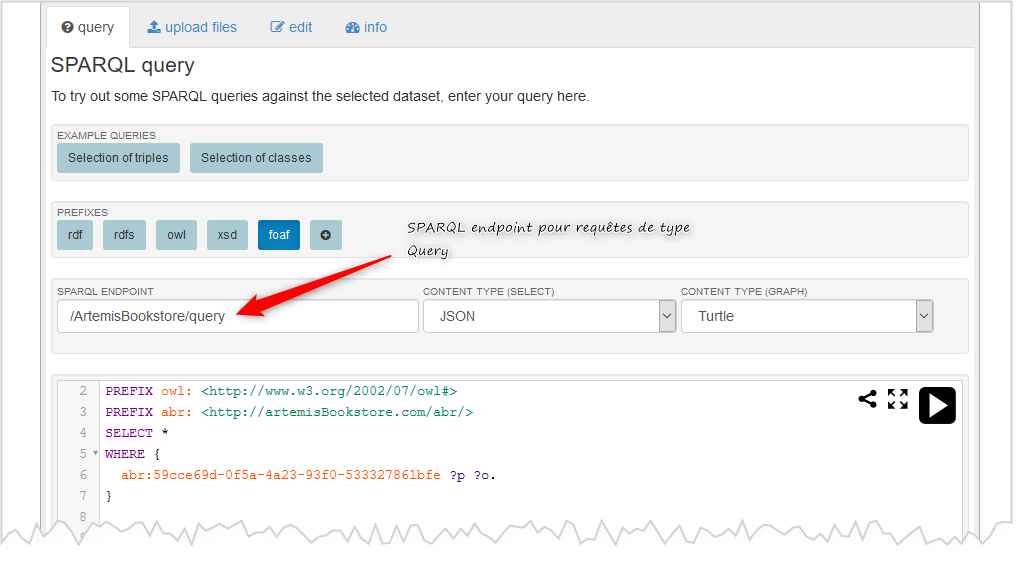
4) Utiliser l'interface fuseki pour des requêtes SPAQRL
Allez sur la page permettant de faire des requêtes SPARQL sur votre dataset
Dans cette fenêtre tapez une requête SPARQL

Exécutez la requête, vous devez obtenir sous la requête un tableau de résultats comme montré sur la figure ci-dessous.
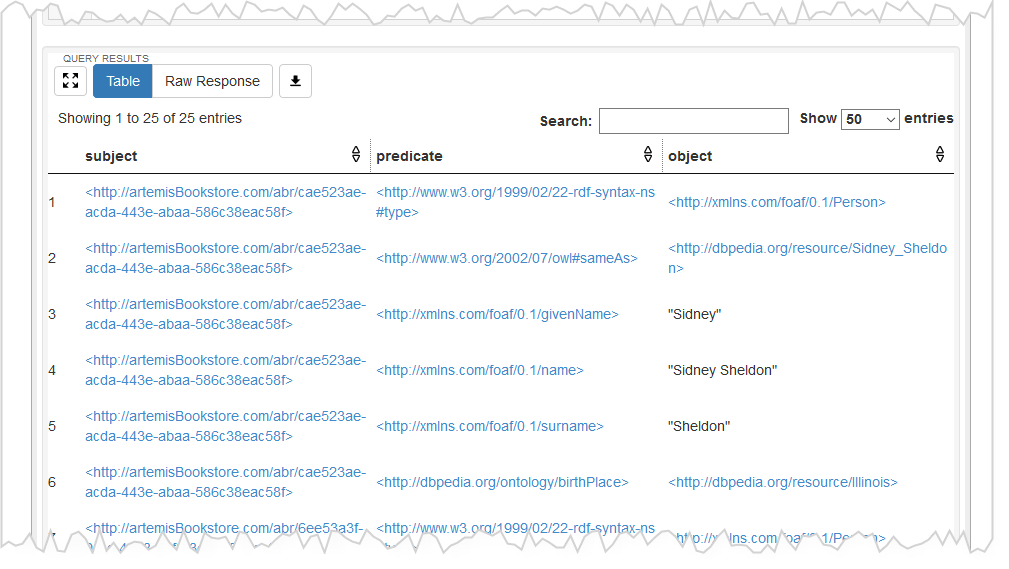
Exercice 1: Ecrivez et testez les requêtes permettant d'obtenir les informations suivantes suivantes
-
La liste des titres des livres écrits par Paul Auster, ordonnée par l'ordre alphabétique.
pour trier les résultats utilisez la clause ORDER BY
Solution -
La nombre d'écrivains présents dans le jeu de données.
pour compter les résultats utilisez l'opérateur d'aggrégation COUNT
Solution -
La nombre d'écrivains présents dans le jeu de données n'ayant pas de lien
owl:sameAsvers DBPedia.
pour tester l'absence d'un pattern dans le graphe utiliser le filtre de négation NOT EXISTS
Solution
3. Requêtes fédérées
Dans le TP précédent, il vous avait été demandé de lier les données de votre librairie avec
DBpedia
en recherchant des liens owl:sameAs entre les écrivains présents dans votre jeu de
données et
les écrivains présents dans DBpedia. Grâce aux requêtes fédérées
supportées par SPARQL 1.1, vous allez pouvoir utiliser ces liens pour interroger
votre jeu de données tout en exploitant les informations présentes dans DBpedia.
4. Requêtes de mise à jour (SPARQL 1.1)
SPARQL 1.1 Update définit des requêtes de modification d'un Graphe de données. Avec ces requêtes vous pouvez facilement insérer ou supprimer des triplets de votre triple store.
Pour vous montrer l'usage de requêtes Update, nous allons dans un premier insérer un lien
owl:sameAs vers DPpedia
pour l'écrivain Arthur Nersesian qui n'en possède pas.
Exercice 1:
Dans l'interface de requêtes
de Fuseki, ecrivez et exécutez une requête permettant d'afficher tous les triplets
concernant Arthur Nersesian
et vérifiez qu'il n'y a pas de lien owl:sameAs.
Solution
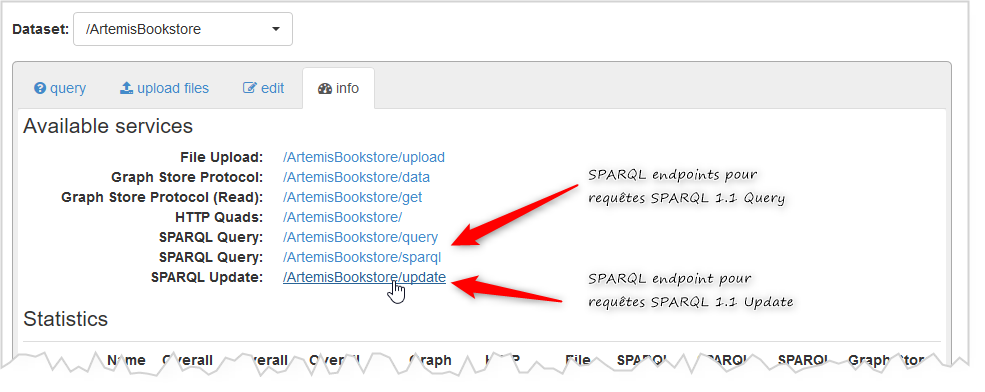
Pour effectuer des modificatiosn du graphe à l'aide de requêtes d'insertion ou délétion) sur
votre serveur Fuseki, il ne faut plus vous
adresser au SPARQL endpoint
http://localhost:3030/ArtemisBookstore/query qui ne permet de faire que des
requêtes de consultation, mais au SPARQL endpoint dédié
aux requêtes de type UpDate : http://localhost:3030/ArtemisBookstore/update, cela
permet au niveau du serveur de gérer différemment
les accès en mettant éventuellement un accès contrôlé pour les requêtes de mise à jour du
graphe.
Pour insérer un triplet liant Arthur Nersesian à sa resource DBpedia (d'URI
http://dbpedia.org/resource/Arthur_Nersesian,
vous pouvez procéder comme suit:
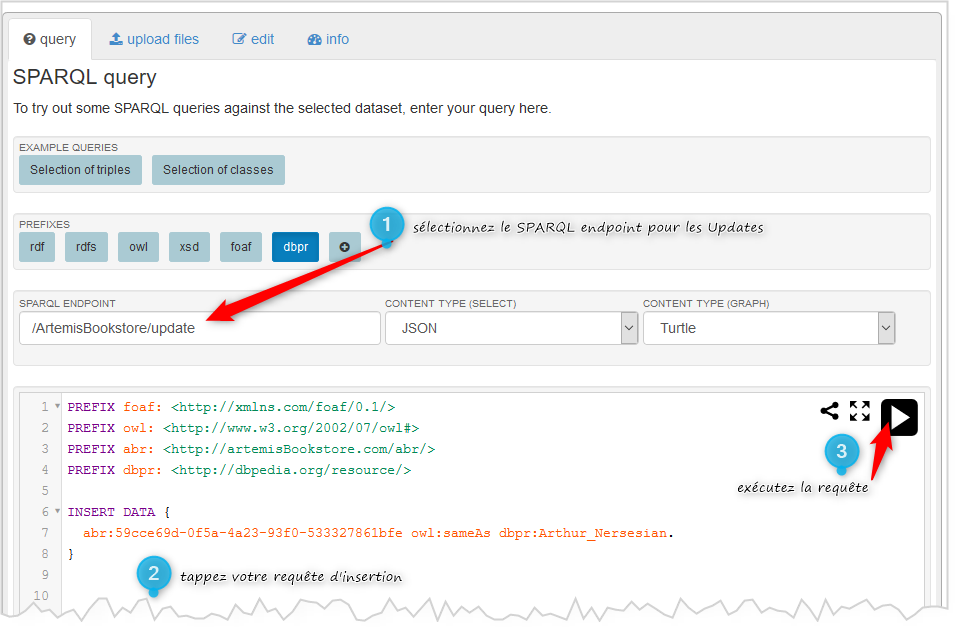
Si la requête s'est effectuée correctement vous devez obtenir le résultat suivant
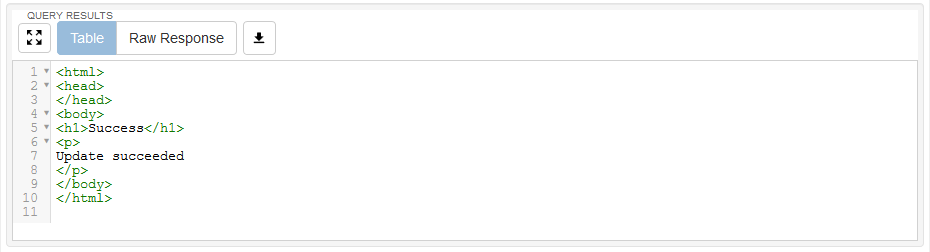
Exercice 2:
En combinant une requête INSERT/WHERE
(qui permet d'effectuer une insertion en utilisant les résultats d'une sélection) avec
une requête fédérée sur DBpedia, inserez dans votre graphe des données issues de DBpedia
indiquant l'état de naissance des
écrivains pour lequel on a un lien owl:sameAs vers DPpedia.
En d'autres termes il s'agit, pour chaque écrivain ?writer ayant un lien
owl:sameAs
de rajouter dans votre triple store les triplets
?writer dbo:birthPlace ?birthState.
?birthPlace rdfs:label ?stateLabel.
où ?birthPlace est l'URI de l'état de naissance de l'écrivain définie dans
DBpedia. Par exemple
dbr:New_Jersey pour Paul Auster.
Solution
Exercice 3: Un fois les insertions effectuées, réalisez
-
une requête permettant de trouver tous les écrivains nés en Californie.
-
une requête permettant de trouver tous les écrivains nés dans le même état que Paul Auster.
5. APIs JENA pour SPARQL
Jena offre des API permettant d'effectuer des requêtes SPARQL depuis un programme Java
Il existe dans Jena deux manières procéder pour effectuer des requêtes SPARQL
-
l'API ARQ 'classique', compatible avec les versions antérieures de Jena
-
l'API RDFConnection introduite avec la version 3.3 de Jena, qui d'une certaine manière rend la programmation moins lourde et exploite au mieux les possibilité de Java 8.
Exercice 1: Ecrivez un programme Java qui, pour un écrivain
donné (le nom de l'écrivain est entré par l'utilisateur), permet d'afficher
tous les écrivain nés dans le même état des Etats-Unis.
à la différence du programme ListBooks.java vu
dans la partie 1
qui chargeait en mémoire le jeu de données puis effectuait une recherche en utilisant
l'API Jena Core,
ici vous construirez votre résultat en effectuant une requête SPARQL sur votre serveur
Fuseki via les API Jena.
Exercice 2: Ecrivez un programme Java qui pour un écrivain donné permet d'afficher quelques éléments bibliographiques issus de DBpedia (sa date de naissance, son lieu de naissance, le résumé DBpedia).