public aspect MethodWrapping{
/* point cut definition */
pointcut Wrappable(): call(public * MyClass.*(..));
/* advice definition */
around(): Wrappable() {
/* prelude: a sequence of code to be inserted before the call */
proceed (); /* performs the call to the original method */
/* postlude: a sequence of code to be inserted after the call */
}
}
The first part of the description defines a point cut as the set of
invocations of any public method of class MyClass. The
advice part says that a call to such a method should be replaced by
a specified prelude, followed by a call to the original method,
followed by a specified postlude. In effect, this amounts to placing a
simple wrapper (without interface modification) around each method
call specified in the pointcut definition. This may be used to add
logging facilities to an existing application, or to insert testing code
to evaluate pre- and post-conditions for implementing design by
contract (2.1.3).
Another capability of AspectJ is introduction, which allows
additional declarations and methods to be inserted at specified places
in an existing class or interface. This facility should be used with
care, since it may break the encapsulation principle.
JAC
JAC (Java Aspect Components) has similar goals to AspectJ. It allows
additional capabilities (method wrapping, introduction) to be added to
an existing application. JAC differs from AspectJ on the following points.
- JAC is not a language extension, but a framework that may be used at
run time. Thus aspects may be dynamically added to a running application.
JAC uses bytecode modification, and the code of the application classes
are modified at class loading time.
- The point cuts and the advices are defined separately. The
binding between point cuts and advices is delayed till the weaving
phase; it relies on information provided in a separate configuration
file. Aspect composition is defined by a meta-object protocol.
Thus JAC provides added flexibility, but at the expense of a higher runtime
overhead due to the dynamic weaving of the aspects into the bytecode.
2.4.3 Pragmatic Approaches
Pragmatic approaches to reflection in middleware borrow features
from the above systematic approaches, but tend to apply them in an ad hoc
fashion, essentially for efficiency reasons. These approaches are essentially based on
interception.
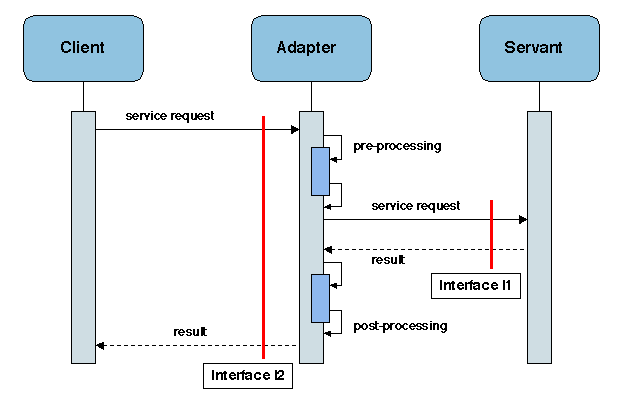
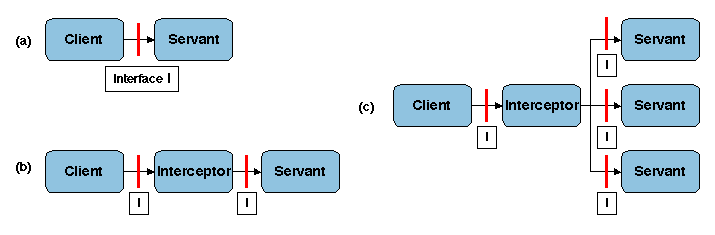
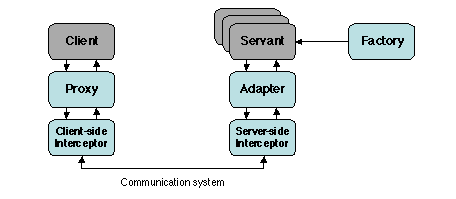
Many middleware systems involve an invocation path from a client to
a remote server, traversing several layers (application, middleware,
operating system, communication protocols). Interceptors may be
inserted at various points of this path, e.g. at the send and
receive operations of requests and replies.
Inserting interceptors allows non-intrusive extension of middleware
functionality, without modifying the application code or the
middleware itself. This technique may be considered as an ad hoc way
of implementing AOP: the insertion points are the join points and the
interceptors directly implement aspects. By adequately specifying the
insertion points for a given class of middleware, conforming to a
specific standard (e.g. CORBA, EJB), the interceptors can be made
generic and may be reused with different implementations of the
standard. The functions that may be added or modified through
interceptors include monitoring, logging and measurement, security,
caching, load balancing, replication.
A detailed example of using interceptors in CORBA may be found in
Chapter 5
.
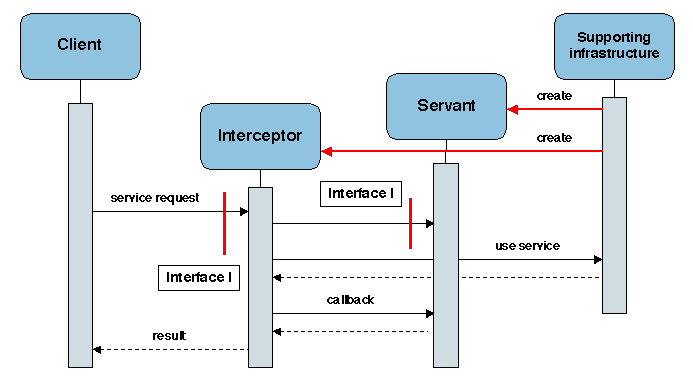
This technique may also be combined with a meta-object protocol, i.e.
the interceptors may be inserted in the reified section of the
invocation path (i.e. within a meta-level).
Interception techniques entail a run time overhead. This may be
alleviated by using code injection, i.e. directly integrating
the code of the interceptor into the code of the client or the server
(this is the analog of inlining the code of procedures in an
optimizing compiler). To be efficient, this injection must be done at
a low level, i.e. in assembly code, or (for Java) at the bytecode
level, using bytecode manipulation tools such as BCEL [BCEL ],
Javassist [Tatsubori et al. 2001], or ASM [ASM ]. To maintain
flexibility, it should be possible to revert the code injection
process by going back to the separate interception form. An example
of use of code injection may be found in [Hagimont and De Palma 2002].
2.4.4 Comparing Approaches
The main approaches to separation of concerns in middleware may be compared
as follows.
- Approaches based on meta-object protocols are the more general
and systematic. However, they entail a potential overhead due to the
back and forth interaction between meta- and base-levels.
- Approaches based on aspects operate on a finer grain that those
based on MOPs and provide more flexibility, at the expense of generality.
The two approaches may be combined, e.g. aspects can be used to modify
operations both at the base and meta levels.
- Approaches based on interception provide restricted capabilities with
respect to MOP or AOP, but provide acceptable solutions for a number of
frequent situations. They are still lacking a formal model on which design
and verification tools could be based.
In all cases, optimization techniques based on low-level code manipulation
may be applied. This area is the subject of active research.
2.5 Historical Note
Architectural concerns in software design appeared in the late 1960s.
The THE operating system [Dijkstra 1968] was an early example of a
complex system designed as a hierarchy of abstract machines. The
notion of object-oriented programming was introduced in the Simula-67
language [Dahl et al. 1970]. Modular construction, an approach to
systematic program composition as an assembly of parts, appeared in
the same period. Design principles developed for architecture and city
planning [Alexander 1964] were transposed to program design and had
a significant influence on the emergence of software engineering as a
discipline [Naur and Randell 1969].
The notion of a design pattern came from the same source a decade
later [Alexander et al. 1977]. Even before that notion was systematically
used, the elementary patterns described in the present chapter had been
identified. Simple forms of wrappers were developed for
converting data from one format to another one, e.g. in the context of
database systems, before being used to transform access methods. An
early use of interceptors is found in the implementation of the first
distributed file system, Unix United [Brownbridge et al. 1982]: a software
layer interposed at the Unix system call interface allows operations
on remote files to be transparently redirected. This method was
later extended [Jones 1993] to include user code in
system calls. Stacked interceptors, both on the client and server
side, were introduced in [Hamilton et al. 1993] under the name of
subcontracts. Various forms of proxies have been used to implement
remote execution, before the pattern was identified
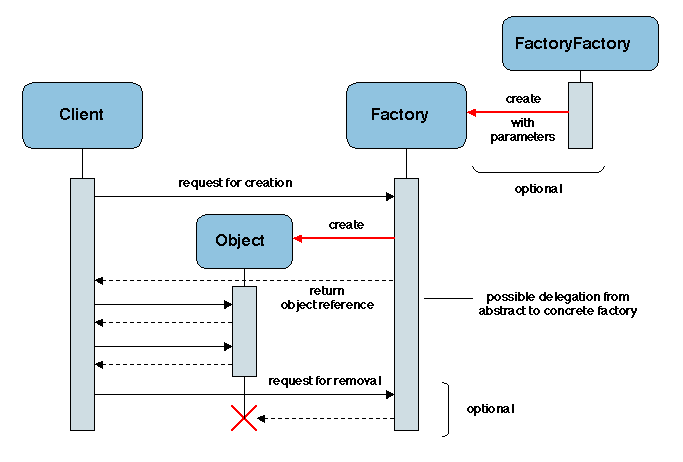
[Shapiro 1986]. Factories seem to have first appeared in the
design of graphical user interfaces (e.g. [Weinand et al. 1988]), in which a
number of parameterized objects (buttons, window frames, menus, etc.) are
dynamically created.
A systematic exploration of software design patterns was initiated in
the late 1980s. After the publication of [Gamma et al. 1994], activity
expanded in this area, with the launching of the PLoP conference
series [PLoP ] and the publication of several specialized books
[Buschmann et al. 1995,Schmidt et al. 2000,Völter et al. 2002].
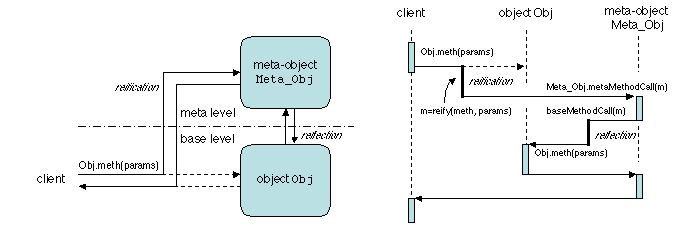
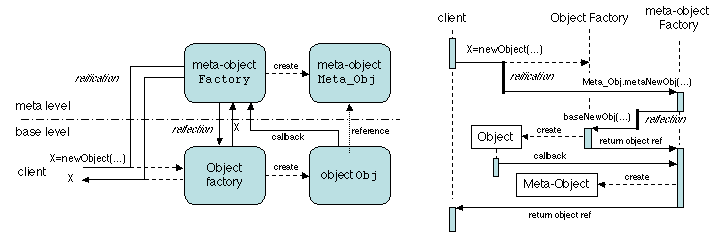
The idea of reflective programming was present in various forms since
the early days of computing (e.g. in the evaluation mechanism of
functional languages such as Lisp). First attempts towards a systematic
use of this notion date from the early 1980s (e.g. the metaclass
mechanism in Smalltalk-80); the foundations of reflective computing were
laid out in [Smith 1982]. The notion of a meta-object protocol
[Kiczales et al. 1991] was introduced for the CLOS language, an object
extension of Lisp. Reflective middleware [Kon et al. 2002] has
been the subject of active research since the mid-1990s, and some of its
notions begin to slowly penetrate commercial systems (e.g. through the
CORBA standard for portable interceptors).
References
- [Alexander 1964]
-
Alexander, C. (1964).
Notes on the Synthesis of Form.
Harvard University Press.
- [Alexander et al. 1977]
-
Alexander, C., Ishikawa, S., and Silverstein, M. (1977).
A Pattern Language: Towns, Buildings, Construction.
Oxford University Press.
1216 pp.
- [ASM ]
-
ASM.
A Java bytecode manipulation framework.
http://www.objectweb.org/asm.
- [BCEL ]
-
BCEL.
Byte Code Engineering Library.
http://jakarta.apache.org/bcel.
- [Beugnard et al. 1999]
-
Beugnard, A., J�z�quel, J.-M., Plouzeau, N., and Watkins, D. (1999).
Making Components Contract Aware.
IEEE Computer, 32(7):38-45.
- [Bieber and Carpenter 2002]
-
Bieber, G. and Carpenter, J. (2002).
Introduction to Service-Oriented Programming.
http://www.openwings.org.
- [Brownbridge et al. 1982]
-
Brownbridge, D. R., Marshall, L. F., and Randell, B. (1982).
The Newcastle Connection - or UNIXes of the World Unite!
Software-Practice and Experience, 12(12):1147-1162.
- [Bruneton 2001]
-
Bruneton, É. (2001).
Un support d'ex�cution pour l'adaptation des aspects
non-fonctionnels des applications r�parties.
PhD thesis, Institut National Polytechnique de Grenoble.
- [Buschmann et al. 1995]
-
Buschmann, F., Meunier, R., Rohnert, H., Sommerlad, P., and Stal, M. (1995).
Pattern-Oriented Software Architecture, Volume 1: A System of
Patterns.
John Wiley & Sons.
467 pp.
- [CACM 1993]
-
CACM (1993).
Communications of the ACM, special issue on concurrent
object-oriented programming.
36(9).
- [Campbell and Habermann 1974]
-
Campbell, R. H. and Habermann, A. N. (1974).
The specification of process synchronization by path expressions.
In Gelenbe, E. and Kaiser, C., editors, Operating Systems, an
International Symposium, volume 16 of Lecture Notes in Computer
Science, pages 89-102. Springer Verlag.
- [Chakrabarti et al. 2002]
-
Chakrabarti, A., de Alfaro, L., Henzinger, T. A., Jurdzinski, M., and Mang,
F. Y. (2002).
Interface Compatibility Checking for Software Modules.
In Proceedings of the 14th International Conference on
Computer-Aided Verification (CAV), volume 2404 of Lecture Notes in
Computer Science, pages 428-441. Springer-Verlag.
- [Dahl et al. 1970]
-
Dahl, O.-J., Myhrhaug, B., and Nygaard, K. (1970).
The SIMULA 67 common base language.
Technical Report S-22, Norwegian Computing Center, Oslo, Norway.
- [Dijkstra 1968]
-
Dijkstra, E. W. (1968).
The Structure of the THE Multiprogramming System.
Communications of the ACM, 11(5):341-346.
- [Gamma et al. 1994]
-
Gamma, E., Helm, R., Johnson, R., and Vlissides, J. (1994).
Design Patterns: Elements of Reusable Object Oriented Software.
Addison-Wesley.
416 pp.
- [Hagimont and De Palma 2002]
-
Hagimont, D. and De Palma, N. (2002).
Removing Indirection Objects for Non-functional Properties.
In Proceedings of the 2002 International Conference on Parallel
and Distributed Processing Techniques and Applications.
- [Hamilton et al. 1993]
-
Hamilton, G., Powell, M. L., and Mitchell, J. G. (1993).
Subcontract: A flexible base for distributed programming.
In Proceedings of the 14th ACM Symposium on Operating Systems
Principles, volume 27 of Operating Systems Review, pages 69-79,
Asheville, NC (USA).
- [Hoare 1969]
-
Hoare, C. A. R. (1969).
An axiomatic basis for computer programming.
Communications of the ACM, 12(10):576-585.
- [Jones 1993]
-
Jones, M. B. (1993).
Interposition agents: Transparently interposing user code at the
system interface.
In Proceedings of the 14th ACM Symposium on Operating Systems
Principles, pages 80-93, Asheville, NC (USA).
- [Kiczales 1996]
-
Kiczales, G. (1996).
Aspect-Oriented Programming.
ACM Computing Surveys, 28(4):154.
- [Kiczales et al. 1991]
-
Kiczales, G., des Rivières, J., and Bobrow, D. G. (1991).
The Art of the Metaobject Protocol.
MIT Press.
345 pp.
- [Kiczales et al. 2001]
-
Kiczales, G., Hilsdale, E., Hugunin, J., Kersten, M., Palm, J., and Griswold,
W. G. (2001).
An overview of AspectJ.
In Proceedings of ECOOP 2001, volume 2072 of Lecture Notes
in Computer Science, pages 327-355, Budapest, Hungary. Springer-Verlag.
- [Kon et al. 2002]
-
Kon, F., Costa, F., Blair, G., and Campbell, R. (2002).
The case for reflective middleware.
Communications of the ACM, 45(6):33-38.
- [Kramer 1998]
-
Kramer, R. (1998).
iContract - The Java Design by Contract Tool.
In Proceedings of the Technology of Object-Oriented Languages
and Systems (TOOLS) Conference, pages 295-307.
- [Lindholm and Yellin 1996]
-
Lindholm, T. and Yellin, F. (1996).
The Java Virtual Machine Specification.
Addison-Wesley.
475 pp.
- [Meyer 1992]
-
Meyer, B. (1992).
Applying Design by Contract.
IEEE Computer, 25(10):40-52.
- [Naur and Randell 1969]
-
Naur, P. and Randell, B., editors (1969).
Software Engineering: A Report On a Conference Sponsored by the
NATO Science Committee, 7-11 Oct. 1968.
Scientific Affairs Division, NATO.
231 pp.
- [Pawlak et al. 2001]
-
Pawlak, R., Duchien, L., Florin, G., and Seinturier, L. (2001).
JAC : a flexible solution for aspect oriented programming in
Java.
In Yonezawa, A. and Matsuoka, S., editors, Proceedings of
Reflection 2001, the Third International Conference on Metalevel
Architectures and Separation of Crosscutting Concerns, volume 2192 of
Lecture Notes in Computer Science, pages 1-24, Kyoto, Japan.
Springer-Verlag.
- [PLoP ]
-
PLoP.
The Pattern Languages of Programs (PLoP) Conference Series.
http://www.hillside.net/conferences/plop.htm.
- [RM 2000]
-
RM (2000).
Workshop on Reflective Middleware. Held in conjunction with
Middleware 2000, 7-8 April 2000.
http://www.comp.lancs.ac.uk/computing/RM2000/.
- [Schmidt et al. 2000]
-
Schmidt, D. C., Stal, M., Rohnert, H., and Buschmann, F. (2000).
Pattern-Oriented Software Architecture, Volume 2: Patterns for
Concurrent and Networked Objects.
John Wiley & Sons.
666 pp.
- [Shapiro 1986]
-
Shapiro, M. (1986).
Structure and encapsulation in distributed systems: The proxy
principle.
In Proc. of the 6th International Conference on Distributed
Computing Systems, pages 198-204, Cambridge, Mass. (USA). IEEE.
- [Smith 1982]
-
Smith, B. C. (1982).
Reflection And Semantics In A Procedural Language.
PhD thesis, Massachusetts Institute of Technology.
MIT/LCS/TR-272.
- [Smith and Nair 2005]
-
Smith, J. E. and Nair, R. (2005).
Virtual Machines: Versatile Platforms for Systems and
Processes.
Morgan Kaufmann.
638 pp.
- [Tatsubori et al. 2001]
-
Tatsubori, M., Sasaki, T., Chiba, S., and Itano, K. (2001).
A Bytecode Translator for Distributed Execution of "Legacy" Java
Software.
In ECOOP 2001 - Object-Oriented Programming, volume 2072 of
Lecture Notes in Computer Science, pages 236-255. Springer Verlag.
- [Völter et al. 2002]
-
Völter, M., Schmid, A., and Wolff, E. (2002).
Server Component Patterns.
John Wiley & Sons.
462 pp.
- [Weinand et al. 1988]
-
Weinand, A., Gamma, E., and Marty, R. (1988).
ET++ - An Object-Oriented Application Framework in C++.
In Proceedings of OOPSLA 1988, pages 46-57.