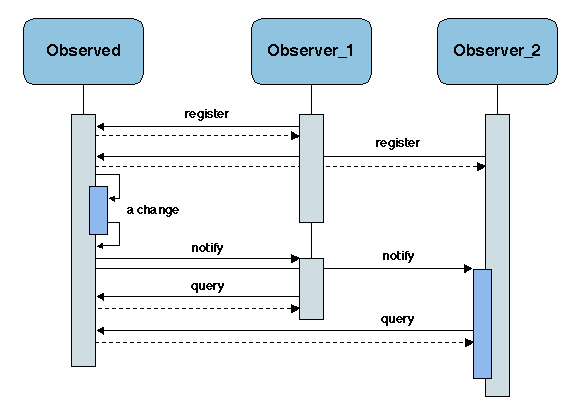
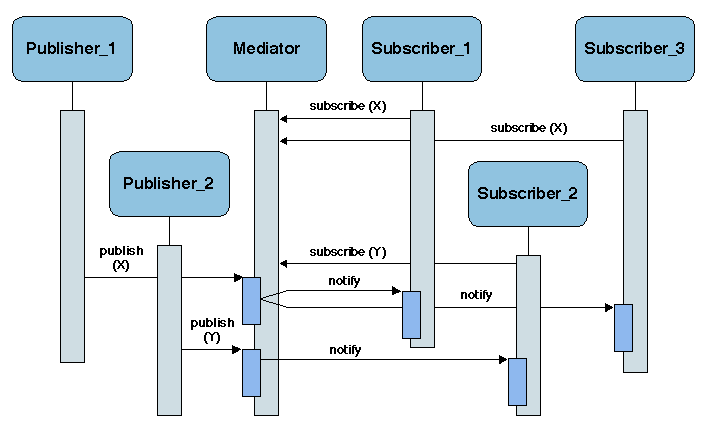
| Currently not available. The examples should include: Gryphon [Banavar et al. 1999] [Aguilera et al. 1999] Siena [Carzaniga et al. 2001] [Rosenblum and Wolf 1997] Infobus [Oki et al. 1993] JEDI [Cugola et al. 2001] |
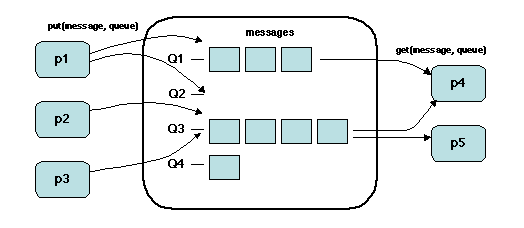
| Currently not available. |
| Currently not available. |
| Currently not available. |
| Currently not available. |
| Currently not available. |