| Table 12.1: Case studies in resource management
The case studies are classified according to the following criteria: nature of the
application (most applications are Internet services, with the special
case of a simple web server); supporting infrastructure (single
machine or cluster); model (empirical, analytic, "black-box" with
parameter identification); observed and controlled variables (through
sensors and actuators, respectively); support for differentiated service.
There are two main approaches to implement a resource management policy.
- Considering the managed system as a black box and installing the
management system outside this black box. Examples of this approach are
developed in 12.5.1 and 12.5.4.
- Embedding the management system within the managed system; this may be done at various levels, e.g., operating system, middleware, or application. Examples of this approach are
developed in 12.5.5 and 12.5.6.
The first approach has the advantage of being minimally invasive, and
to be independent of the internal structure of the managed system,
which may possibly be unknown, as is the case with legacy systems. The
second approach allows a finer grain control of the management policy,
but involves access to the internals of the managed systems. The
resource management programs also need to evolve together with the
application, which entails additional costs.
A mixed approach is to consider the system as an assembly of black boxes, and to
install the management system at the boundaries thus defined, provided that the
architecture of the managed system is indeed explicit. An example is presented
in 12.5.2.
12.5.1 Admission Control using a Black-Box Approach
As an example of the black-box approach, we present QUORUM
[Blanquer et al. 2005], a management system for cluster-based Internet
services. QUORUM aims at ensuring QoS guarantees for differentiated
classes of service. For each class of service, the SLA is composed of
two Service Level Objectives (SLO): minimum average throughput, and
maximum response time for 95% of the requests. The SLA may only be
guaranteed if it is feasible for the expected load and the cluster
capacity, i.e., if 1) the clients of each class announce the expected
computation requirements for the requests of the class; 2) the
incoming request rate for each class is kept below its guaranteed
throughput; and 3) the resources of the cluster are adequately
dimensioned. In line with the black-box approach, SLA guarantees are
defined at the boundary of the cluster.
QUORUM is implemented in a front-end node sitting between the clients
and the cluster on which the application is running; this node acts as
a load balancer (12.3.2), and is connected to the
nodes that support the first tier of the application.
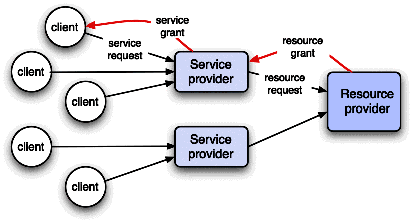
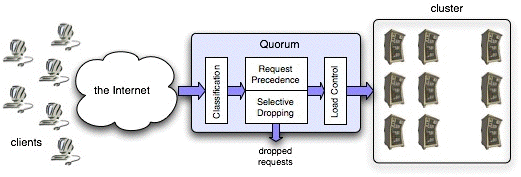 Figure 12.6: The architecture of QUORUM (from [Blanquer et al. 2005])
QUORUM is composed of four modules, which run on the front-end node
(Figure 12.6). Their function is as follows (more
details are provided further on).
Figure 12.6: The architecture of QUORUM (from [Blanquer et al. 2005])
QUORUM is composed of four modules, which run on the front-end node
(Figure 12.6). Their function is as follows (more
details are provided further on).
- The Classification module receives all client requests,
and determines the service class of each request.
- The Request Precedence module determines which proportion
of the requests within each class will be transmitted to the cluster.
- The Selective Dropping module performs admission control,
by discarding the requests for which the specified maximum response time
cannot be guaranteed.
- The Load Control module releases the surviving requests
into the cluster, and determines the rate of this request flow in
order to keep the load of the cluster within acceptable bounds.
Thus QUORUM controls both the requests to be forwarded to the cluster and the
flow rate of these requests.
Load Control regulates the input rate of the requests through a
sliding window mechanism similar to that of the TCP transport
protocol. The window size determines the number of outstanding
requests at any time; it is recomputed periodically (a typical period
is 500 ms, a compromise between fast reaction time and significant
observation time). The observed parameter is the most restrictive
response time for the set of service classes. The current algorithm
increments or decrements linearly the window size to keep the response
time within bounds.
Request Precedence virtually partitions the cluster resources among
the service classes, thus ensuring isolation between classes. The goal
is to ensure that the fraction of the global cluster capacity
allocated to each class allows the throughput guarantee for this class
to be met. The resource share allocated to each class is computed
from the guaranteed throughput for this class and the expected
computation requirements of the requests. Should the requests for a
class exceed these requirements (thus violating the client's part of
the contract), the throughput for that class would be reduced accordingly, thus
preserving the other classes' guarantees.
In summary, Request Precedence ensures the throughput SLO for each
class, while Load Control ensures the response time SLO. Selective
Dropping discards the requests for which the response time SLO
cannot be achieved under the resource partition needed to guarantee
throughput.
Experience with a medium-sized cluster (68 CPUs) and a load
replayed from traces of commercial applications shows that
QUORUM achieves its QoS objectives with a moderate performance
overhead (3%), and behaves well under wide fluctuations of
incoming traffic, or in the presence of misbehaving classes
(i.e., exceeding their announced computation requirements).
Other systems have experimented with the black-box approach for 3-tier applications.
GATEKEEPER [Elnikety et al. 2004] does not provide QoS guarantees,
but improves the overall performance of the system by delaying
thrashing, using admission control. In the absence of a client-side
contract, GATEKEEPER needs a preliminary setup phase in order to
determine the capacity of the system.
YAKSHA [Kamra et al. 2004] is based on a
queueing model of the managed system, and uses a PI (Proportional
Integral) feedback control loop to pilot admission control.
It does not provide service differentiation. The SLA only
specifies a maximum response time requirement; throughput is
subject to best effort. The system is shown to resist to
overload, and to rapidly adjust to changes in the workload.
12.5.2 Staged Admission Control
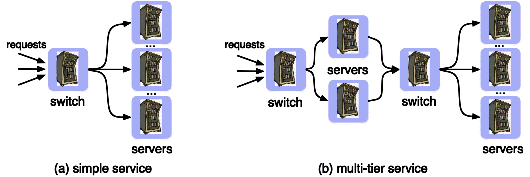
SEDA (Staged Event-Driven Architecture [Welsh et al. 2001],
[Welsh and Culler 2003]) is an architecture for building highly concurrent
Internet services. High concurrency aims at responding to massive
request loads. The traditional approach to designing concurrent
systems, by servicing each request by a distinct process or thread,
suffers from a high overhead under heavy load, both in switching time
and in memory footprint. SEDA explores an alternative approach, in
which an application is built as a network of event-driven stages
connected by event queues (Figure 12.7(a)). Within each
stage, execution is carried out by a small-sized thread pool. This
decomposition has the advantages of modularity, and the composition of
stages through event queues provide mutual performance isolation
between stages.
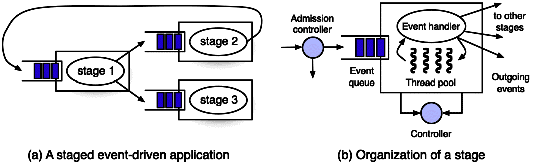 Figure 12.7: The architecture of SEDA (from [Welsh and Culler 2003])
The structure of a stage is shown on Figure 12.7(b). A
stage is organized around an application-specific event handler, which
schedules reactions to incoming events, by activating the threads in
the pool. Each invocation of the event handler treats a batch of events,
whose size is subject to control, as explained later.
The event handler acts as a finite state machine. In
addition to changing the local state, its execution generates zero or
more events, which are dispatched to event queues of other stages. To
ensure performance, the event handling programs should be
non-blocking; thus a non-blocking I/O library is used. Note that this
structure is similar to that of Click [Kohler et al. 2000], the
modular packet router described in 4.4.2
.
Two forms of control are used within each stage, in order to maintain
performance in the face of overload: admission control is applied to
each event queue, and resource allocation within a stage is also
subject to control.
Doing admission control on a per stage basis allows focusing
on overloaded stages. The admission control policy usually consists in
limiting the rate at which a stage accepts incoming events to keep the
observed performance at that stage within specified bounds. If an
event is rejected by this mechanism, it is the responsibility of the
stage that emitted the event to react to the rejection (e.g., by
sending the event to another stage, a form of load balancing). In the
experiments described, performance metrics is defined by the
90th-percentile response time, smoothed to prevent over-reaction in
case of sudden spikes. The policy also implements service
differentiation, by defining a separate instance of the admission
controller for each customer class. Thus a larger fraction of the
lower class requests are rejected, ensuring service guarantees to the
higher classes.
Within a stage, resources may be controlled by one or more specialized
controllers. One instance is the thread pool controller, which adjusts
the number of threads according to the current load of the stage,
estimated by the length of the event queue. Another instance is the
batching controller, which adjusts the size of the batch of events
processed by each invocation of the event handler. The goal of this
controller is to maintain a trade-off between the benefits of a large
batching factor (e.g., cache locality and task aggregation, which
increase throughput), and the overhead it places on response time.
Thus the controller attempts to keep the batch size at the smallest
value allowing high throughput.
Experiments on a SEDA-based mail server [Welsh and Culler 2003]
have shown that the admission control controller is effective in
reacting to load spikes, and keeps the response time close to the
target. However, the rejection rate may be as high as 80% for
massive load spikes. It has also been shown that per-stage
admission control rejects less requests than single point
admission control.
Another policy for responding to overload is to degrade the QoS of the
request being served, in order to reduce the rejection rate at the
expense of lower quality (see 12.1.3). Service degradation
gives best results when coupled with admission control.
In its current state, SEDA does not attempt to coordinate
the admission control decisions made at the different stages of an application.
Therefore, a request may be dropped at a late stage, when it has already
consumed a significant amount of resources.
The work presented in the next section addresses this problem.
Figure 12.7: The architecture of SEDA (from [Welsh and Culler 2003])
The structure of a stage is shown on Figure 12.7(b). A
stage is organized around an application-specific event handler, which
schedules reactions to incoming events, by activating the threads in
the pool. Each invocation of the event handler treats a batch of events,
whose size is subject to control, as explained later.
The event handler acts as a finite state machine. In
addition to changing the local state, its execution generates zero or
more events, which are dispatched to event queues of other stages. To
ensure performance, the event handling programs should be
non-blocking; thus a non-blocking I/O library is used. Note that this
structure is similar to that of Click [Kohler et al. 2000], the
modular packet router described in 4.4.2
.
Two forms of control are used within each stage, in order to maintain
performance in the face of overload: admission control is applied to
each event queue, and resource allocation within a stage is also
subject to control.
Doing admission control on a per stage basis allows focusing
on overloaded stages. The admission control policy usually consists in
limiting the rate at which a stage accepts incoming events to keep the
observed performance at that stage within specified bounds. If an
event is rejected by this mechanism, it is the responsibility of the
stage that emitted the event to react to the rejection (e.g., by
sending the event to another stage, a form of load balancing). In the
experiments described, performance metrics is defined by the
90th-percentile response time, smoothed to prevent over-reaction in
case of sudden spikes. The policy also implements service
differentiation, by defining a separate instance of the admission
controller for each customer class. Thus a larger fraction of the
lower class requests are rejected, ensuring service guarantees to the
higher classes.
Within a stage, resources may be controlled by one or more specialized
controllers. One instance is the thread pool controller, which adjusts
the number of threads according to the current load of the stage,
estimated by the length of the event queue. Another instance is the
batching controller, which adjusts the size of the batch of events
processed by each invocation of the event handler. The goal of this
controller is to maintain a trade-off between the benefits of a large
batching factor (e.g., cache locality and task aggregation, which
increase throughput), and the overhead it places on response time.
Thus the controller attempts to keep the batch size at the smallest
value allowing high throughput.
Experiments on a SEDA-based mail server [Welsh and Culler 2003]
have shown that the admission control controller is effective in
reacting to load spikes, and keeps the response time close to the
target. However, the rejection rate may be as high as 80% for
massive load spikes. It has also been shown that per-stage
admission control rejects less requests than single point
admission control.
Another policy for responding to overload is to degrade the QoS of the
request being served, in order to reduce the rejection rate at the
expense of lower quality (see 12.1.3). Service degradation
gives best results when coupled with admission control.
In its current state, SEDA does not attempt to coordinate
the admission control decisions made at the different stages of an application.
Therefore, a request may be dropped at a late stage, when it has already
consumed a significant amount of resources.
The work presented in the next section addresses this problem.
12.5.3 Session-Based Admission Control
Session-Based Admission Control [Cherkasova and Phaal 2002] is a method
used to improve the performance of commercial web sites by preventing
overload. This is essentially an improvement of a basic predictive
admission control method based on the individual processing of
independent requests, in which the admission algorithm keeps the
server close to its peak capacity, by detecting and rejecting requests
that would lead to overload.
This method is not suited for a commercial web site, in which the load
has the form of sessions. A session is a sequence of requests
separated by think intervals, each request depending on the previous
ones (e.g., browsing the site, making inquiries, moving items into the
cart, etc.). If the requests are admitted individually, request
rejection may occur anywhere in a session. Thus some sessions may be
interrupted and aborted before completion if retries are unsuccessful;
for such a session, all the work done till rejection will have been
wasted. As a consequence, although the server operates near its full
capacity, the fraction of its time devoted to useful work may be quite
low for a high server load (and thus a high rejection rate).
Therefore a more appropriate method is to consider sessions (rather than
individual requests) as units of admission, and to make the admission
decision as early as possible for a session. The admission criterion is based
on server utilization, assuming that the server is CPU-bound (the criterion
could be extended to include other resources such as I/O or network bandwidth).
A predefined threshold Umax specifies the critical server
utilization level (a typical value is 95%). The load of the server
is predicted periodically (typically every few seconds),
based on observations over the last time interval:
Ui+1predicted=f(i+1), where f is defined by: |
f(1)=Umax
and
f(i+1)=(1-k)f(i) + kUimeasured
Thus the predicted load for interval Ti+1 is estimated as a weighted
mean of the previous estimated load and the load actually measured
over the last interval Ti. The coefficient k (the weight of
measurement versus extrapolation) is set between 0 and 1. The admission
control algorithm is as follows.
- if Ui+1predicted > Umax, then any new session
arriving during Ti+1 will be rejected (a rejection message is
send to the client). The server will only process the already
accepted sessions.
- if Ui+1predicted � Umax, then the server will accept new sessions again.
The weighting factor k allows the algorithm to be tuned by
emphasizing responsiveness (k close to 1) or stability (k close to
0). A responsive algorithm (strong emphasis on current observation)
tends to be restrictive since it starts rejecting requests at the
first sign of overload; the risk is server underutilization. A stable
algorithm (strong emphasis on past history) is more permissive; the
risk is a higher rate of abortion of already started sessions if the
load increases in the future (a session in progress may be aborted in
an overloaded server, due to timeouts on delayed replies and to
limitation of the number of retries).
This algorithm has been extensively studied by simulation using
SpecWeb, a standardized benchmark for measuring basic
web server performance. Since sessions (rather than individual
requests) are defined as the resource principals, an important
parameter of the load is the average length (number of requests) of a
session. Thus the simulation was done with three session populations,
of respective average length 5, 15 and 50. We present a few typical
results (refer to the original paper for a detailed analysis).
With a fully responsive admission control algorithm (k = 1), a
sampling interval of 1 second, and a threshold Umax = 95%
- The throughput for completed sessions is improved for long
sessions (e.g., from 80% to 90% for length 50 at 250% server
load6); it is fairly stable for medium length sessions, and
worse for short sessions. This may be explained by the fact that
more short sessions are rejected at high load, with a corresponding
rise of the rejection overhead.
- The percentage of aborted sessions falls to zero for long and
medium sessions, at all server loads. It tends to rise for short
sessions at high loads (10% at 250% load, 55% at 300% load).
- The most important effect is the increase in useful server
utilization, i.e., the fraction of processor time spent in
processing sessions that run to completion (i.e., are not aborted
before they terminate). This factor improves from 15% to 70%, 85%
and 88% for short, medium and long sessions, respectively, for a
200% server load. This is correlated with result 2 (low rate of
aborted sessions).
Lowering the weighting factor k (going from responsive to stable)
has the expected effect of increasing the useful throughput at moderate
load, but of decreasing it at higher load, where more sessions are aborted
due to inaccurate prediction (the threshold load value is about 170%
for 15-request sessions). This suggests using an adaptive policy in
which k would be dynamically adjusted by observing the percentage of
refused connections and aborted requests. If this ratio rises, k is
increased to make the admission policy more restrictive; if it falls
to zero, k is gradually decreased.
Another dynamic strategy consists in trying to predict the number of
sessions that the server will be able to process in the next interval,
based on the observed load and on workload characterization. The
server rejects any new session above this quota.
Both dynamic strategies (adapting the responsiveness factor k and
predicting the acceptable load) have been tried with different load
patterns drawn from experience ("usual day" and "busy day"). Both
strategies were found to reduce the number of aborted sessions and
thus to improve the useful throughput, the predictive strategy giving
the best results.
12.5.4 Feedback Control of a Web Server
The work reported in [Diao et al. 2002a], [Diao et al. 2002b] is
an early attempt to apply feedback control to the management of an
Internet service (a single Apache web server delivering static content).
The controlled variables are CPU and memory utilization, denoted by CPU
and MEM, respectively, which are easily accessible low-level variables,
assuming that the settings of these variables are correlated to QoS
levels such as expressed in an SLA. The controlling variables are
those commonly used by system administrators, namely MaxClients (MC),
the maximum number of clients that can connect to the server, and
KeepAlive Timeout (KA), which determines how long an idle connection is
maintained in the HTTP 1.1 protocol. This parameter allows an inactive
client (or a client whose think time has exceeded a preset limit) to be
disconnected from the server, thus leaving room to serve other
clients.
The Apache web server is modeled by a black box, with two inputs (MC
and KA) and two outputs (CPU and MEM). The behavior of this
black box is assumed to be linear and time-invariant7
. In a
rough first approximation, CPU is strongly correlated with KA, and
MEM is strongly correlated with MC. This suggests modeling the
evolution of the server by the two Single Input, Single Output (SISO)
equations:
| |
CPU(k+1) = aCPUCPU(k) + bCPUKA(k) |
| |
| | MEM(k+1) = aMEMMEM(k) + bMEMMC(k) |
| |
|
where time is discretized (X(k) denotes the value of X at the k-th time step),
and the as and bs denotes constant coefficients, to be determined by
identification (least squares regression with discrete sine wave inputs).
A more general model, which does not assume a priori correlations, is the
Multiple Input, Multiple Output (MIMO) model:
in which
|
y(k) = |
�
�
�
|
|
|
�
�
�
|
,u(k) = |
�
�
�
|
|
|
�
�
�
|
, |
|
and A and B are 2×2 constant matrices, again
determined by identification.
The first step is to test the accuracy of the models. Experience with
a synthetic workload generator, comparing actual values with those
predicted by the model, gives the following results.
- While the SISO model of MEM is accurate, the SISO model of CPU provides
a poor fit to actual data, specially with multiple step inputs.
- Overall, the MIMO model gives a more accurate fit than the dual SISO model.
- The accuracy of the models degrades near the ends of the operating region,
showing the limits of the linearity assumption.
The second step is to use the model for feedback control. The
controller is Proportional Integral (PI), with gain coefficients
determined by classical controller design methods (pole placement
for SISO, and cost function minimization for MIMO).
Experience shows that the SISO model performs well in spite of its
inaccuracy, due to the limited degree of coupling between KA and MC.
However, the MIMO model does better overall, specially for heavy workload.
The contributions of this work are to show that control theory can
indeed be applied to Internet services, and that good results can be
obtained with a simple design. In that sense, this work is a proof of
concept experiment. However, being one of the first attempts at
modeling an Internet service, it suffers from some limitations.
- The model is linear, while experience shows that actual systems
exhibit a non-linear behavior due to saturation and thrashing.
- The model uses low-level system parameters as controlled variables, instead
of user-perceived QoS factors. In that sense, it does not solve the
SLA decomposition problem, as presented in 12.3.1.
- The model considers a single server, while clusters are more common.
- The workload generator does not create wide amplitude load peaks.
More recent models, such as that presented in the next section, aim at
overcoming these limitations.
Another early attempt at applying feedback control to web server performance
is [Abdelzaher et al. 2002]. They use a SISO algorithm, in which
the measured variable is system utilization and the controlled variable
is a single index that determines the fraction of clients to be served
at each service level (assuming the service to be available at
various levels of degradation). This index is the input of an admission
control actuator.
12.5.5 Resource Provisioning for a Multi-tier Service
The work reported in [Urgaonkar et al. 2007] differs from that presented in
the previous sections, in that it is based on an analytical model of
the managed system. This model may be used to predict response times,
and to drive resource allocation, using both dynamic resource
provisioning and admission control.
The class of systems under study is that of multi-tiered systems
(12.1.3). A multi-tiered system is represented as a
network of queues: queue Qi represents the i-th tier (i = 1, 2,�, M). In the first, basic, version of the model, there is a
single server per tier. A request goes from tier 1 to tier M,
receiving service at each tier, as shown on Figure
12.8, which represents a 3-tier service.
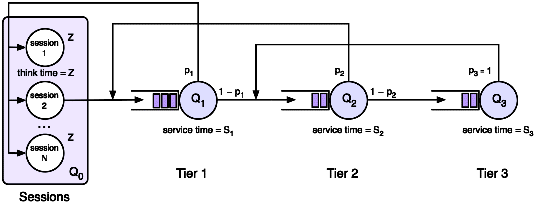 Figure 12.8: Queueing network for a 3-tier service (adapted from [Urgaonkar et al. 2007])
The model represents a session as a set of requests (cf
12.5.3). Sessions are represented by a special queueing
system, Q0, which consists of N "servers", which act as request
generators. Each server in Q0 represents a session: it emits
successive requests, separated by a think time. When a session
terminates, a new one is started at the same server; thus Q0
represents a steady load of N sessions.
The model takes the following aspects into account:
Figure 12.8: Queueing network for a 3-tier service (adapted from [Urgaonkar et al. 2007])
The model represents a session as a set of requests (cf
12.5.3). Sessions are represented by a special queueing
system, Q0, which consists of N "servers", which act as request
generators. Each server in Q0 represents a session: it emits
successive requests, separated by a think time. When a session
terminates, a new one is started at the same server; thus Q0
represents a steady load of N sessions.
The model takes the following aspects into account:
- A request may visit a tier (say number k) several times (e.g.,
if it makes several queries in a database).
- A request may go no further than a certain tier (e.g., because
the answer was found in a cache in that tier, and no further
processing is needed).
This is represented in the model by a transition from tier k to tier
k - 1. The two above cases are represented using different
transition probabilities. A request terminates when it goes back from
Q1 to Q0.
The parameters of the basic version of the model are the service times
Si at each tier i, the transition probabilities between queues
(pi is the transition probability from Qi to Qi - 1), and
the think time of the user, represented by the service time of the
servers in Q0. Numerical values of these parameters, for a specific
application, are estimated by monitoring the execution of this
application under a given workload. Once these parameters are known,
the system may be resolved, using the Mean-Value Analysis (MVA)
algorithm [Reiser and Lavenberg 1980] for closed queueing networks, to
compute the mean response time.
Several enhancement have been added to the basic version.
- Modeling multiple servers. Internet services running on clusters
use replicated tiers for efficiency and availability. This is
represented by multiple queues at each tier: the single queue Qi
is replaced by ri queues Qi,1, �, Qi,ri, where
ri is the degree of replication at tier i. As described in
12.3.2, a load balancer forwards requests from one
tier to the next, and dispatches them across replicas. A parameter
of the model captures the possible imbalance due to specific
constraints such as stateful servers or cache affinity.
- Handling concurrency limits. There is a limit to the number of
activities that a node may concurrently handle. This is represented
by a drop probability (some requests are dropped due to concurrency
limits).
- Handling multiple session classes. Given the parameters of each
class (think time, service times, etc.), the model allows the
average response time to be computed on a per-class basis.
The model has some limitations: a) Each tier is modeled by a single
queue, while requests actually compete for several different
resources: CPU, memory, network, disk. b) The model assumes that a
request uses the resources of one tier at a time. While this is true
for many Internet services, some applications such as streaming
servers use pipeline processing, not currently represented by the
model.
Experiments with synthetic loads have shown that the model predicts
the response time of applications within the 95% confidence interval.
In addition, the model has been used to assist two aspects of resource
management: dynamic resource provisioning (for predictable loads) and
admission control (for unexpected peaks).
- Dynamic resource provisioning. Assume that the workload
of the application may be predicted for the short term, in terms of
number of sessions and characteristics of the sessions. Then
resource provisioning works as follows: define an initial server
assignment for each tier (e.g., one server per tier). Use the model
to determine the average response time. If it is worse than the
target, examine the effect of adding one more server to each tier
that may be replicated. Repeat until the response time is below the
target. This assumes that the installation has sufficient capacity
(total number of servers to meet the target). The complexity of the
computation is of the order of M.N (M number of tiers, N
number of sessions), which is acceptable if resources are
provisioned for a fairly long period (hours).
- Admission control. Admission control is intended to react
to unexpected workload peaks. In the model under study, it is
performed by a front-end node, which turns out excess sessions to
guarantee the SLA (here the response time). The criterion for
dropping requests is to maximize a utility function, which is
application dependent. For example, the utility function may be a
global revenue generated by the admitted sessions; assigning a
revenue to each session class allows service differentiation. In the
experiments described, the system admits the sessions in
non-increasing order of generated revenue, determining the expected
response time according to the model, and drops a session if its
admission would violate the SLA for at least one session class.
The interest of this work is that it provides a complete analytical
model for a complex system: a multi-tiered application with replicated
tiers, in the presence of a complex load. The system is able to
represent such features as load unbalancing and caching effects,
and allows for differentiated service. Its main application is
capacity planning and dynamic resource provisioning for loads whose
characteristics may be predicted with fair accuracy.
Similar queueing models have been used for correlating SLOs with
system-level thresholds [Chen et al. 2007], and for identifying the
bottleneck tier in a multi-tier system, in order to apply a control
algorithm for service differentiation [Diao et al. 2006].
12.5.6 Real-Time Scheduling
[Lu et al. 2002] have explored the use of feedback control theory
for the systematic design of algorithms for real-time scheduling. This
is a single-resource problem: a number of tasks, both periodic and
aperiodic, compete for the CPU. Each task must meet a deadline; for
periodic tasks, the deadline is set for each period, and for
non-periodic tasks, the deadline is relative to the arrival time. The
arrival times (for aperiodic tasks) and CPU utilization rates are
unknown, but estimates are provided for each task.
The controlled variables, i.e., the performance metrics controlled by
the scheduler, are sampled at regular intervals (with a period W),
and defined over the kth sampling window [(k-1)W, kW]. These
variables include:
- The deadline miss ratio M(k), the number of deadline misses
divided by the number of completed and aborted tasks in the window.
- The CPU utilization U(k), the percentage of CPU busy time in
the window.
Reference values MS and US are set for these variables (e.g.
MS = 0 and US = 90%). Three variants of the control system have
been studied: FC-U, which only controls M(k), FC-M, which only controls
U(k), and FC-UM, which combines FC-U and FC-M as described later.
There is a single manipulated variable, on which the scheduler may act
to influence the system's behavior: B(k), the total estimated CPU
utilization of all tasks in the system. The actuator changes the value
of B(k) according to the control algorithm. Then an optimization
algorithm determines the precise allocation of CPU to tasks over the
(k+1)th window so that their total CPU utilization is B(k+1). In
addition to being called at each sampling instant, the actuator is
also invoked upon the arrival of each task, to correct prediction
errors on arrival times..
The optimization algorithm relies on the notions of QoS level and
value. Each task Ti is assigned a certain number (at least two) of
QoS levels, which determine possible conditions of execution, defined
by a few attributes associated with each level j, among which a
relative deadline Di[j], an estimated CPU utilization Bi[j] and
a value Vi[j]. Level 0 corresponds to the rejection of the task;
both Bi[0] and Vi[0] are set8 to 0. The
value Vi[j] expresses the contribution of the task (as estimated by
the application designer) if it meets its deadline Di[j] at level
j; if it misses the deadline, the contribution is Vi[0] (equal or
less than 0). Both Bi[j] and Vi[j] increase with j.
The optimization algorithm assigns a (non-zero) QoS level to each task
to maximize its value density (the ratio Vi[j]/Bi[j], defined as 0
for level 0), and then schedules the tasks in the order of decreasing
density until the total prescribed CPU utilization B(k) is reached.
Intuitively, a system with two levels of QoS corresponds to an
admission control algorithm: a task is either rejected (level 0) or
scheduled at its single QoS level (level 1); the value density
criterion gives priority to short, highly valued tasks. Increasing
the number of levels allows for a finer control over the relative
estimated value of a task's completion: instead of deciding to either
run or reject a task, the algorithm may chose to run it at an
intermediate level of QoS for which the ratio between contribution and
consumed resources qualifies the task for execution.
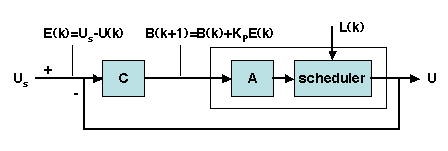 Figure 12.9: Feedback control of CPU scheduling
The controller algorithm uses a simple proportional control function
(Figure 12.9), i.e., the control function is
D(k) = K.E(k), where E(k) (the error), is the difference between
the reference value and the measured output, i.e., either MS - M(k)
or US - U(k) depending on the controlled variable. Then the command
to the actuator is B(k+1) = B(k) + D(k).
Combining FC-U and FC-M is done as follows: the two separate control
loops are set up, then the two command signals D(k) are compared, and
the lower signal is selected.
The disturbance is the actual load, which introduces an uncertainty factor
since the estimates of arrival times and CPU consumption may be incorrect.
A complete analysis of this system has been done, using the control
theory methodology. The system is non-linear, due to saturation. This
can be modeled by two different regimes separated by a threshold; each
of the regimes can be linearized. Then the analysis determines
stability conditions and allows the parameters to be tuned for various
load characteristics.
The experimental results obtained with various synthetic loads show
that the system is stable in the face of overload, that it has low
overshoot in transient states, and that it achieves an overall better
utilization of CPU than standard open-loop control algorithms such as
EDF. In addition, the system has all the benefits of the availability
of a model, i.e., performance prediction and help in parameter
selection.
Figure 12.9: Feedback control of CPU scheduling
The controller algorithm uses a simple proportional control function
(Figure 12.9), i.e., the control function is
D(k) = K.E(k), where E(k) (the error), is the difference between
the reference value and the measured output, i.e., either MS - M(k)
or US - U(k) depending on the controlled variable. Then the command
to the actuator is B(k+1) = B(k) + D(k).
Combining FC-U and FC-M is done as follows: the two separate control
loops are set up, then the two command signals D(k) are compared, and
the lower signal is selected.
The disturbance is the actual load, which introduces an uncertainty factor
since the estimates of arrival times and CPU consumption may be incorrect.
A complete analysis of this system has been done, using the control
theory methodology. The system is non-linear, due to saturation. This
can be modeled by two different regimes separated by a threshold; each
of the regimes can be linearized. Then the analysis determines
stability conditions and allows the parameters to be tuned for various
load characteristics.
The experimental results obtained with various synthetic loads show
that the system is stable in the face of overload, that it has low
overshoot in transient states, and that it achieves an overall better
utilization of CPU than standard open-loop control algorithms such as
EDF. In addition, the system has all the benefits of the availability
of a model, i.e., performance prediction and help in parameter
selection.
12.6 Conclusion
We summarize a few conclusions on resource management to achieve QoS
requirements.
- Resource management has long been guided by heuristics. The
situation is changing, due to a better understanding of SLA
decomposition (the relationship between user-perceived QoS and
internal resource occupation parameters). This in turn results from
the elaboration of more accurate models of the managed systems, and
from the development of better statistical correlation methods.
- The application of control theory to resource management is
still in an early stage. This may be explained by the inherent
complexity of the systems under study and by their highly non-linear
and time-dependent character. Control-based techniques should also
benefit from the above-mentioned progress in SLA decomposition.
Most likely, successful methods will combine predictive
(model-based) and reactive (feedback-controlled) algorithms.
- Admission control appears to be the dominant strategy for
dealing with unexpected load peaks. It may be made minimally invasive,
using a black box approach, and its actuators are easy to
implement.
However, this apparent simplicity should not offset the difficulty
of the design of a good admission control algorithm. As many
experiments have shown, a good knowledge of the load can be usefully
exploited, again mixing predictive and reactive approaches.
- A number of aspects need further investigation, e.g., allocation
problems for multiple resources, interaction between resource
management for multistage requests (such as multiple tiers), further
elaboration of the contract satisfaction criteria (probabilistic,
guaranteed).
12.7 Historical Note
Resource allocation was one the main areas of operating systems
research in the mid-1960s. The pitfalls of resource management, such
as deadlock and starvation, were identified at that time, and
solutions were proposed. The influence of resource allocation on
user-perceived performance was also investigated, using both queueing
models and empirical approaches. Capacity planning models were used
for dimensioning mainframes. The problems of resource overcommitment,
leading to thrashing, were understood in the late 1960s, and the
principle of their solution (threshold-based control of the
multiprogramming degree) is still valid today.
The notion of Quality of Service was not present as such for operating
systems (although similar concepts were underlying the area of
performance management). QoS was introduced in networking, first in
the form of support for differentiated service, then for
application-related performance. QoS emerged as an important area of
study with the advent of the first multimedia applications (e.g.,
streaming audio and video), for which the "best effort" philosophy
of the Internet Protocol was inappropriate. Techniques such as channel
reservation, traffic policing, scheduling algorithms, and congestion
avoidance were developed. [Wang 2001] presents the main
concepts and techniques of Internet QoS.
In the 1980s, heuristic-based feedback control methods were
successfully applied to network operation (e.g., for adaptive routing
in the Internet, for flow control in TCP). The extension of QoS to
middleware systems was initiated in the 1990s (see e.g.,
[Blair and Stefani 1997]).
The rapid rise of Internet services in the 2000s, and the growing
user demand for QoS guarantees, have stimulated efforts in this area.
As a part of the autonomic computing movement (see
9.2
), several projects have attempted to apply
control theory to the management of computing systems, specially for
performance guarantees. [Hellerstein et al. 2004] gives a detailed
account of these early efforts. In addition to feedback control,
current research topics are the development of accurate models for
complex Internet services, and the use of statistical methods to
characterize both the service request load and the behavior of the
managed systems.
References
- [Abdelzaher et al. 2002]
-
Abdelzaher, T. F., Shin, K. G., and Bhatti, N. (2002).
Performance guarantees for Web server end-systems: A
control-theoretical approach.
IEEE Transactions on Parallel and Distributed Systems,
13(1):80-96.
- [Amza et al. 2002]
-
Amza, C., Cecchet, E., Chanda, A., Cox, A., Elnikety, S., Gil, R., Marguerite,
J., Rajamani, K., and Zwaenepoel, W. (2002).
Specification and Implementation of Dynamic Web Site Benchmarks.
In WWC-5: IEEE 5th Annual Workshop on Workload
Characterization, Austin, TX, USA.
- [Appleby et al. 2001]
-
Appleby, K., Fakhouri, S., Fong, L., Goldszmidt, G., Kalantar, M.,
Krishnakumar, S., Pazel, D., Pershing, J., and Rochwerger, B. (2001).
Oceano - SLA based management of a computing utility.
In Proceedings of the 7th IFIP/IEEE International Symposium on
Integrated Network Management.
- [Aron et al. 2000]
-
Aron, M., Druschel, P., and Zwaenepoel, W. (2000).
Cluster reserves: a mechanism for resource management in
cluster-based network servers.
In Proceedings of the ACM SIGMETRICS Conference on Measurement
and Modeling of Computer Systems, pages 90-101, Santa Clara, California.
- [Balazinska et al. 2004]
-
Balazinska, M., Balakrishnan, H., and Stonebraker, M. (2004).
Contract-Based Load Management in Federated Distributed Systems.
In First USENIX Symposium on Networked Systems Design and
Implementation (NSDI'04), pages 197-210, San Francisco, CA, USA.
- [Banga et al. 1999]
-
Banga, G., Druschel, P., and Mogul, J. C. (1999).
Resource containers: A new facility for resource management in server
systems.
In Proceedings of the Third Symposium on Operating Systems
Design and Implementation (OSDI'99), New Orleans, Louisiana.
- [Bavier et al. 2004]
-
Bavier, A., Bowman, M., Chun, B., Culler, D., Karlin, S., Muir, S., Peterson,
L., Roscoe, T., Spalink, T., and Wawrzoniak, M. (2004).
Operating System Support for Planetary-Scale Network Services.
In First USENIX Symposium on Networked Systems Design and
Implementation (NSDI'04), pages 253-266, San Francisco, CA, USA.
- [Blair and Stefani 1997]
-
Blair, G. and Stefani, J.-B. (1997).
Open Distributed Processing and Multimedia.
Addison-Wesley.
452 pp.
- [Blanquer et al. 2005]
-
Blanquer, J. M., Batchelli, A., Schauser, K., and Wolski, R. (2005).
Quorum: Flexible Quality of Service for Internet Services.
In Second USENIX Symposium on Networked Systems Design and
Implementation (NSDI'05), pages 159-174, Boston, Mass., USA.
- [Brawn and Gustavson 1968]
-
Brawn, B. and Gustavson, F. (1968).
Program behavior in a paging environment.
In Proceedings of the AFIPS Fall Joint Computer Conference
(FJCC'68), pages 1019-1032.
- [Cardellini et al. 2002]
-
Cardellini, V., Casalicchio, E., Colajanni, M., and Yu, P. S. (2002).
The state of the art in locally distributed Web-server systems.
ACM Computing Surveys, 34(2):263-311.
- [Chase et al. 2003]
-
Chase, J. S., Irwin, D. E., Grit, L. E., Moore, J. D., and Sprenkle, S. E.
(2003).
Dynamic virtual clusters in a grid site manager.
In Proceedings 12th IEEE International Symposium on High
Performance Distributed Computing (HPDC'03), Seattle, Washington.
- [Chen et al. 2007]
-
Chen, Y., Iyer, S., Liu, X., Milojicic, D., and Sahai, A. (2007).
SLA Decomposition: Translating Service Level Objectives to System
Level Thresholds.
Technical Report HPL-2007-17, Hewlett-Packard Laboratories, Palo
Alto.
- [Cherkasova and Phaal 2002]
-
Cherkasova, L. and Phaal, P. (2002).
Session-Based Admission Control: A Mechanism for Peak Load
Management of Commercial Web Sites.
IEEE Transactions on Computers, 51(6):669-685.
- [Cohen et al. 2004]
-
Cohen, I., , Goldszmidt, M., Kelly, T., Symons, J., and Chase, J. S. (2004).
Correlating instrumentation data to system states: A building block
for automated diagnosis and control.
In Proceedings of the Sixth Symposium on Operating Systems
Design and Implementation (OSDI'04), pages 31-44, San Francisco, CA, USA.
- [Diao et al. 2002a]
-
Diao, Y., Gandhi, N., Hellerstein, J. L., Parekh, S., and Tilbury, D. M.
(2002a).
MIMO Control of an Apache Web Server: Modeling and Controller
Design.
In Proceeedings of the American Control Conference, volume 6,
pages 4922-4927.
- [Diao et al. 2002b]
-
Diao, Y., Gandhi, N., Hellerstein, J. L., Parekh, S., and Tilbury, D. M.
(2002b).
Using MIMO feedback control to enforce policies for interrelated
metrics with application to the Apache Web server.
In IEEE/IFIP Network Operations and Management Symposium
(NOMS'02), pages 219-234, Florence, Italy.
- [Diao et al. 2005]
-
Diao, Y., Hellerstein, J. L., Parekh, S., Griffith, R., Kaiser, G., and Phung,
D. (2005).
Self-Managing Systems: A Control Theory Foundation.
In 12th IEEE International Conference and Workshops on the
Engineering of Computer-Based Systems (ECBS'05), pages 441-448, Greenbelt,
MD, USA.
- [Diao et al. 2006]
-
Diao, Y., Hellerstein, J. L., Parekh, S., Shaikh, H., and Surendra, M. (2006).
Controlling Quality of Service in Multi-Tier Web Applications.
In 26st International Conference on Distributed Computing
Systems (ICDCS'06), pages 25-32, Lisboa, Portugal.
- [Doyle et al. 2003]
-
Doyle, R. P., Chase, J. S., Asad, O. M., Jin, W., and Vahdat, A. M. (2003).
Model-based Resource Provisioning in Web Service Utility.
In Proceedings of the USENIX Symposium on Internet
Technologies and Systems (USITS-03), Seattle, WA, USA.
- [Elnikety et al. 2004]
-
Elnikety, S., Nahum, E., Tracey, J., and Zwaenepoel, W. (2004).
A method for transparent admission control and request scheduling in
e-commerce web sites.
In Proceedings of the 13th International Conference on World
Wide Web (WWW'2004), pages 276-286, New York, NY, USA.
- [Feldman et al. 2005]
-
Feldman, M., Lai, K., and Zhang, L. (2005).
A price-anticipating resource allocation mechanism for distributed
shared clusters.
In Proceedings of the 6th ACM Conference on Electronic Commerce
(EC'05), pages 127-136, New York, NY, USA. ACM Press.
- [Friedman et al. 1997]
-
Friedman, N., Geiger, D., and Goldszmidt, M. (1997).
Bayesian network classifiers.
Machine Learning, 29(13):131-163.
- [Fu et al. 2003]
-
Fu, Y., Chase, J., Chun, B., Schwab, S., and Vahdat, A. (2003).
SHARP: an architecture for secure resource peering.
In Proceedings of the nineteenth ACM Symposium on Operating
Systems Principles (SOSP'03), pages 133-148. ACM Press.
- [Govil et al. 2000]
-
Govil, K., Teodosiu, D., Huang, Y., and Rosenblum, M. (2000).
Cellular Disco: Resource Management using Virtual Clusters on
Shared-memory Multiprocessors.
ACM Transactions on Computer Systems, 18(3):229-262.
- [Hellerstein 2004]
-
Hellerstein, J. L. (2004).
Challenges in Control Engineering of Computer Systems.
In Proceedings of the American Control Conference, pages
1970-1979, Boston, Mass, USA.
- [Hellerstein et al. 2004]
-
Hellerstein, J. L., Diao, Y., Tilbury, D. M., and Parekh, S. (2004).
Feedback Control of Computing Systems.
John Wiley and Sons.
429 pp.
- [Irwin et al. 2005]
-
Irwin, D., Chase, J., Grit, L., and Yumerefendi, A. (2005).
Self-recharging virtual currency.
In P2PECON '05: Proceedings of the 2005 ACM SIGCOMM Workshop on
Economics of Peer-to-Peer Systems, pages 93-98, New York, NY, USA. ACM
Press.
- [Kamra et al. 2004]
-
Kamra, A., Misra, V., and Nahum, E. (2004).
Yaksha: A Self-Tuning Controller for Managing the Performance of
3-Tiered Web Sites.
In International Workshop on Quality of Service (IWQoS).
- [Kohler et al. 2000]
-
Kohler, E., Morris, R., Chen, B., Jannotti, J., and Kaashoek, M. F. (2000).
The Click modular router.
ACM Transactions on Computer Systems, 18(3):263-297.
- [Lazowska et al. 1984]
-
Lazowska, E. D., Zahorjan, J., Graham, G. S., and Sevcik, K. C. (1984).
Quantitative System Performance : Computer system analysis using
queueing network models.
Prentice Hall.
417 pp., available on-line at
http://www.cs.washington.edu/homes/lazowska/qsp/.
- [Lu et al. 2002]
-
Lu, C., Stankovic, J. A., Tao, G., and Son, S. H. (2002).
Feedback Control Real-Time Scheduling: Framework, Modeling and
Algorithms.
Real Time Systems Journal, 23(1/2):85-126.
- [Menascé and Almeida 2001]
-
Menascé, D. A. and Almeida, V. A. F. (2001).
Capacity Planning for Web Services: metrics, models, and
methods.
Prentice Hall.
608 pp.
- [Moore et al. 2002]
-
Moore, J., Irwin, D., Grit, L., Sprenkle, S., , and Chase, J. (2002).
Managing mixed-use clusters with cluster-on-demand.
Technical report, Department of Computer Science, Duke University.
http://issg.cs.duke.edu/cod-arch.pdf.
- [Pai et al. 1998]
-
Pai, V. S., Aron, M., Banga, G., Svendsen, M., Druschel, P., Zwaenepoel, W.,
and Nahum, E. M. (1998).
Locality-aware request distribution in cluster-based network servers.
In Proceedings of the Eighth International Conference on
Architectural Support for Programming Languages and Operating Systems
(ASPLOS-VIII), pages 205-216.
- [Reiser and Lavenberg 1980]
-
Reiser, M. and Lavenberg, S. S. (1980).
Mean-value analysis of closed multichain queuing networks.
Journal of the Association for Computing Machinery,
27(2):313-322.
- [Schroeder et al. 2006]
-
Schroeder, B., Wierman, A., and Harchol-Balter, M. (2006).
Open versus closed: a cautionary tale.
In Third Symposium on Networked Systems Design & Implementation
(NSDI'06), pages 239-252. USENIX Association.
- [Sullivan et al. 1999]
-
Sullivan, D. G., Haas, R., and Seltzer, M. I. (1999).
Tickets and Currencies Revisited: Extensions to Multi-Resource
Lottery Scheduling.
In Workshop on Hot Topics in Operating Systems (HotOS VII),
pages 148-152.
- [Sutherland 1968]
-
Sutherland, I. E. (1968).
A futures market in computer time.
Commun. ACM, 11(6):449-451.
- [TPC 2006]
-
TPC (2006).
TPC Benchmarks.
Transaction Processing Performance Council.
http://www.tpc.org/.
- [Urgaonkar et al. 2007]
-
Urgaonkar, B., Pacifici, G., Shenoy, P., Spreitzer, M., and Tantawi, A. (2007).
An Analytical Model for Multi-tier Internet Services and its
Applications.
ACM Transactions on the Web, 1(1).
- [Urgaonkar and Shenoy 2004]
-
Urgaonkar, B. and Shenoy, P. (2004).
Sharc: Managing CPU and Network Bandwidth in Shared Clusters.
IEEE Transactions on Parallel and Distributed Systems,
15(1):2-17.
- [Urgaonkar et al. 2002]
-
Urgaonkar, B., Shenoy, P., and Roscoe, T. (2002).
Resource Overbooking and Application Profiling in Shared Hosting
Platforms.
In Proceedings of the Fifth Symposium on Operating Systems
Design and Implementation (OSDI'02), pages 239-254, Boston, MA.
- [Uttamchandani et al. 2005]
-
Uttamchandani, S., Yin, L., Alvarez, G., Palmer, J., and Agha, G. (2005).
Chameleon: a self-evolving, fully-adaptive resource arbitrator for
storage systems.
In Proceedings of the 2005 USENIX Technical Conference, pages
75-88, Anaheim, CA, USA.
- [Waldspurger and Weihl 1994]
-
Waldspurger, C. A. and Weihl, W. E. (1994).
Lottery scheduling: Flexible proportional-share resource management.
In Proceedings of the First Symposium on Operating Systems
Design and Implementation (OSDI'94), pages 1-11, Monterey, California.
- [Wang 2001]
-
Wang, Z. (2001).
Internet QoS.
Morgan Kaufmann.
240 pp.
- [Welsh and Culler 2003]
-
Welsh, M. and Culler, D. (2003).
Adaptive Overload Control for Busy Internet Servers.
In Proceedings of the USENIX Symposium on Internet
Technologies and Systems (USITS-03), Seattle, WA, USA.
- [Welsh et al. 2001]
-
Welsh, M., Culler, D., and Brewer, E. (2001).
SEDA: An Architecture for Well-Conditioned Scalable Internet
Services.
In Proceedings of the Eighteenth ACM Symposium on Operating
Systems Principles (SOSP'01), pages 230-243, Banff, Alberta, Canada.
- [Zhang et al. 2005]
-
Zhang, Q., Sun, W., Riska, A., Smirni, E., and Ciardo, G. (2005).
Workload-Aware Load Balancing for Clustered Web Servers.
IEEE Transactions on Parallel and Distributed Systems,
16(3):219-233.
Footnotes:
1This term comes from network technology:
traffic policing means controlling the maximum rate of
traffic sent or received on a network interface, in order to
preserve network QoS.
2If the binding changes frequently,
rescheduling the thread at each change may prove costly; thus the
scheduling of a shared thread is based on a combined allocation of
the set of containers to which it is bound, and this set is
periodically recomputed; thus the rescheduling period may be
controlled, at the expense of fine grain accuracy.
3This term has a different
meaning from that used in Chapter 8
.
4called agent in
[Fu et al. 2003].
5http://www.cs.washington.edu/homes/lazowska/qsp/
6the server load is the ratio between the aggregated
load generated by the requests and the server processing
capacity.
7A system
with input u and output y is linear if
y(au) = ay(u) and
y(u1+u2) = y(u1) + y(u2). It is time-invariant if its
behavior is insensitive to a change of the origin of time.
8Vi[0] may also be set
to a negative value, which corresponds to a penalty.
File translated from
TEX
by
TTH,
version 3.40.
On 27 Feb 2009, 12:58.
|