289 EventChannelImpl(String address, int port, String type,
290 EventChannelFactory binder) throws JonathanException {
291 id=(EBinder.EId)binder.getEBinder().newId(address,port,type);
292 SessionIdentifier ep=id.getSessionIdentifier();
293 Context hints = JContextFactory.instance.newContext();
294 hints.addElement("interface_type",String.class,type,(char) 0);
295 proxy=binder.newStub(ep,new Identifier[] {id}, hints);
296 hints.release();
297 this.binder=binder;
298 }
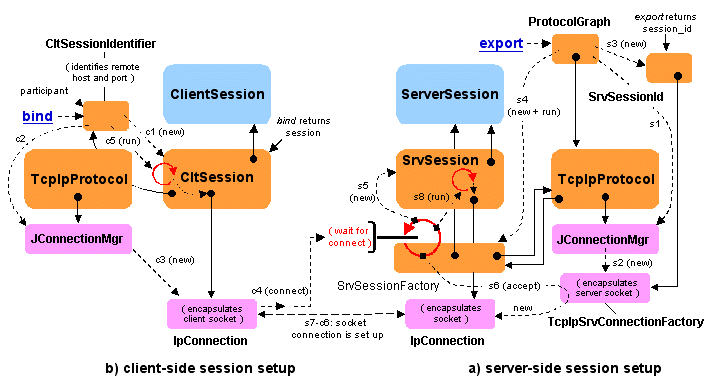
On line 291, a new EId is created by the EBinder, with the
given address and port. On line 292, a new session is associated with
this EId, using the underlying RTP and IP Multicast protocols.
Finally, a proxy (stub) is created using this session. This proxy is
ready to be delivered to any source willing to send events to the
channel, through the following method:
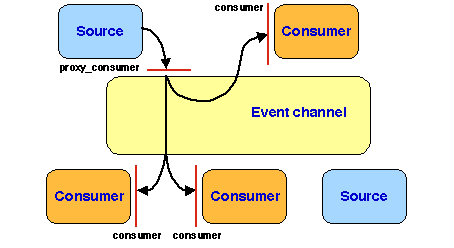
328 public Object getConsumerProxy() throws JonathanException {
329 return proxy;
330 }
A consumer connects to the event channel by calling the following method:
301 public void addConsumer(Object consumer) throws JonathanException {
302 a: if(binder==null) {
303 if (proxy instanceof StdStub) {
304 Identifier[] ids =
305 ((JRMIRef) ((StdStub) proxy).getRef()).getIdentifiers();
306 Object cid;
307 for (int i = 0; i < ids.length; i++) {
308 cid = ids[i];
309 while (cid instanceof Identifier) {
310 if (cid instanceof EBinder.EId) {
311 id = (EBinder.EId) cid;
312 binder = (EventChannelFactory) id.getContext();
313 break a;
314 } else {
315 cid = ((Identifier) cid).resolve();
316 }
317 }
318 }
319 }
320 throw new BindException("Unbound channel");
321 }
322 binder.getEBinder().bindConsumer(new OneWaySkeleton(consumer),id);
323 }
The key operation here is on line 322: the consumer builds a skeleton
that will act as an event receiver interface for it, then binds that
skeleton to the event channel using the bindConsumer method of
the EBinder, as described above. Lines 302 to 321 illustrate
another (classical) situation in the binding process: if the factory
associated with the channel is not known (e.g., because the event
channel reference has been sent over the network), the method tries to
retrieve it using one of the identifiers associated with the stub, by
iteratively resolving the identifier chain until the factory
(binder) is found, or until the search fails.
4.6.4 Conclusion
Jonathan is based on the ideas introduced by the x-kernel, but
improves on the following aspects:
- It follows a systematic approach to naming and binding through the use of the
export-bind pattern (3.3.3
)
- It is based on an object-oriented language (Java); the objects defined in the framework are represented by Java objects.
The aspects related to deployment and configuration have not been described.
Jonathan uses configuration files, which allow a configuration description
to be separated from the code of the implementation.
Although Jonathan itself is no longer in use, its main design
principles have been adopted by Carol [Carol 2005], an open source
framework that provides a common base for building Remote Method
Invocation (RMI) implementations (5.4
).
4.7 Historical Note
Communication systems cover a wide area, and a discussion of their
history is well outside the scope of this book. In accordance with
our general approach, we restrict our interest to networking systems
(the infrastructure upon which middleware is built), and we briefly
examine their evolution from an architectural point of view.
Although dedicated networks existed before this period, interest in
networking started in the mid 1960s (packet switching techniques were
developed in the early 1960s and the first nodes of the ARPAnet were
deployed in 1969). The notion of a protocol (then called a "message
protocol") was already present at that time, as a systematic approach
to the problem of interconnecting heterogeneous computers.
As the use of networks was developing, the need for standards
for the interconnection of heterogeneous computers was recognized.
In 1977, the International Standards Organization (ISO) started
work that led to the proposal of the 7-layer OSI reference model
[Zimmermann 1980]. By that time, however, the main protocols
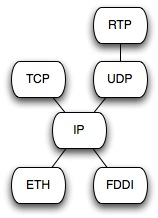
of the future global Internet (IP, TCP, and UDP) were already in wide use, and became
the de facto standards, while the OSI model essentially remained
a common conceptual framework.
The Internet underwent a major evolution in the mid-1980s, in response to
the increase in the number of its nodes: the introduction of the Domain
Name System (DNS), and the extension of TCP to achieve congestion control.
A brief history of the Internet, written by its main actors, may be
found in [Leiner et al. 2003].
The 1990s were marked by important changes. The advent of the World
Wide Web opened the Internet to a wide audience and led the way to
a variety of distributed applications. At about the same time, the
first object-based middleware systems appeared, stressing the
importance of application-level protocols. New applications imposed
more stringent requirements on the communication protocols, both on
the functional aspects (e.g., multicast, totally ordered broadcast)
and on quality of service (performance, reliability, security).
In the 2000s, two main trends are visible: the development of new
usages of the Internet, exemplified by overlay networks (e.g.,
[Andersen et al. 2001]) for various functions, from content distribution to peer
to peer systems; and the rise of wireless communications
[Stallings 2005], which generates new forms of access to
the Internet, but also wholly new application areas such as sensor
networks [Zhao and Guibas 2004] or spontaneous ad hoc networks. Both
trends are leading to a reassessment of the basic services provided by the
Internet (whose main transport protocols are still basically those
developed in the 1980s) and to the search for new architectural
patterns, of which the SensorNet research (4.5.2) is a
typical example. Peer to peer and ad hoc networks call for new
application-level protocols, such as gossip-based algorithms
[Kermarrec and van Steen 2007a].
On the architecture front, the x-kernel [Hutchinson and Peterson 1991,Abbott and Peterson 1993] and related systems opened the way to a
systematic approach to the modular design of communication protocols.
Initially based on objects in the 1990s, this approach followed the
transition from objects to components and is now applied to the new
above-mentioned applications areas. The trend towards fine-grain
protocol decomposition (as illustrated in 4.5.2) is
imposed both by economy of resource usage and by the search for
increased adaptability and customization. The strive for a balance
between abstraction and efficiency, an everlasting concern, is still
present under new forms.
References
- [Abbott and Peterson 1993]
-
Abbott, M. B. and Peterson, L. L. (1993).
A language-based approach to protocol implementation.
IEEE ACM Transactions on Networking, 1(1):4-19.
- [Aberer et al. 2005]
-
Aberer, K., Alima, L. O., Ghodsi, A., Girdzijauskas, S., Hauswirth, M., and
Haridi, S. (2005).
The essence of P2P: A reference architecture for overlay networks.
In Proceedings of 5th IEEE International Conference on
Peer-to-Peer Computing, pages 11-20, Konstanz, Germany.
- [Alvisi et al. 2007]
-
Alvisi, L., Doumen, J., Guerraoui, R., Koldehofe, B., Li, H., van Renesse,
R., and Tredan, G. (2007).
How robust are gossip-based communication protocols?
ACM SIGOPS Operating Systems Review, Special Issue on
Gossip-Based Networking, pages 14-18.
- [Andersen et al. 2001]
-
Andersen, D. G., Balakrishnan, H., Kaashoek, M. F., and Morris, R. (2001).
Resilient Overlay Networks.
In Proceedings of the Eighteenth ACM Symposium on Operating
Systems Principles (SOSP'01), Banff, Canada.
- [Babaoglu and Marzullo 1993]
-
Babaoglu, Ö. and Marzullo, K. (1993).
Consistent Global States of Distributed Systems: Fundamental
Concepts and Mechanisms.
In Mullender, S., editor, Distributed Systems, pages 55-96.
Addison-Wesley.
- [Birman 2007]
-
Birman, K. (2007).
How robust are gossip-based communication protocols?
ACM SIGOPS Operating Systems Review, Special Issue on
Gossip-Based Networking, pages 8-13.
- [Carol 2005]
-
Carol (2005).
Common Architecture for RMI ObjectWeb Layer.
The ObjectWeb Consortium.
http://carol.objectweb.org.
- [Chockler et al. 2001]
-
Chockler, G. V., Keidar, I., and Vitenberg, R. (2001).
Group Communication Specifications: a Comprehensive Study.
ACM Computing Surveys, 33(4):427-469.
- [Condie et al. 2005]
-
Condie, T., Hellerstein, J. M., Maniatis, P., Rhea, S., and Roscoe, T. (2005).
Finally, a use for componentized transport protocols.
In Proceedings of the Fourth Workshop on Hot Topics in Networks
(HotNets IV), College Park, MD, USA.
- [Coulouris et al. 2005]
-
Coulouris, G., Dollimore, J., and Kindberg, T. (2005).
Distributed Systems - Concepts and Design.
Addison-Wesley, 4th edition.
928 pp.
- [Culler et al. 2005]
-
Culler, D., Dutta, P., Ee, C. T., Fonseca, R., Hui, J., Levis, P., Polastre,
J., Shenker, S., Stoica, I., Tolle, G., and Zhao, J. (2005).
Towards a Sensor Network Architecture: Lowering the Waistline.
In Proceedings of the Tenth International Workshop on Hot Topics
in Operating Systems (HotOS X), Santa Fe, NM, USA.
- [Demers et al. 1987]
-
Demers, A., Greene, D., Hauser, C., Irish, W., Larson, J., Shenker, S.,
Sturgis, H., Swinehart, D., and Terry, D. (1987).
Epidemic algorithms for replicated database maintenance.
In Proceedings of the Sixth ACM Symposium on Principles of
Distributed Computing (PODC '87), pages 1-12, New York, NY, USA. ACM.
- [Dumant et al. 1998]
-
Dumant, B., Horn, F., Tran, F. D., and Stefani, J.-B. (1998).
Jonathan: an Open Distributed Processing Environment in Java.
In Davies, R., Raymond, K., and Seitz, J., editors, Proceedings
of Middleware'98: IFIP International Conference on Distributed Systems
Platforms and Open Distributed Processing, pages 175-190, The Lake
District, UK. Springer.
- [Ee et al. 2006]
-
Ee, C. T., Fonseca, R., Kim, S., Moon, D., Tavakoli, A., Culler, D., Shenker,
S., and Stoica, I. (2006).
A modular network layer for sensornets.
In Proceedings of the Seventh Symposium on Operating Systems
Design and Implementation (OSDI'06), pages 249-262, Seattle, WA, USA.
- [Eugster et al. 2003]
-
Eugster, P. Th., Felber, P., Guerraoui, R., and Kermarrec, A.-M.
(2003).
The Many Faces of Publish/Subscribe.
ACM Computing Surveys, 35(2):114-131.
- [Hadzilacos and Toueg 1993]
-
Hadzilacos, V. and Toueg, S. (1993).
Fault-Tolerant Broadcasts and Related Problems.
In Mullender, S., editor, Distributed Systems, pages 97-168.
Addison-Wesley.
- [Hutchinson and Peterson 1991]
-
Hutchinson, N. C. and Peterson, L. L. (1991).
The x-Kernel: An architecture for implementing network
protocols.
IEEE Transactions on Software Engineering, 17(1):64-76.
- [Jannotti et al. 2000]
-
Jannotti, J., Gifford, D. K., Johnson, K. L., Kaashoek, M. F., and O'Toole,
Jr., J. W. (2000).
Overcast: Reliable multicasting with an overlay network.
In Proceedings of the Fourth Symposium on Operating Systems
Design and Implementation (OSDI), pages 197-212, San Diego, CA, USA.
- [Kermarrec and van Steen 2007a]
-
Kermarrec, A.-M. and van Steen, M., editors (2007a).
Gossip-Based Computer Networking, volume 41(5), Special Topic
of ACM Operating Systems Review.
- [Kermarrec and van Steen 2007b]
-
Kermarrec, A.-M. and van Steen, M. (2007b).
Gossiping in distributed systems.
ACM SIGOPS Operating Systems Review, Special Issue on
Gossip-Based Networking, pages 2-7.
- [Kohler et al. 2000]
-
Kohler, E., Morris, R., Chen, B., Jannotti, J., and Kaashoek, M. F. (2000).
The Click modular router.
ACM Transactions on Computer Systems, 18(3):263-297.
- [Kurose and Ross 2004]
-
Kurose, J. F. and Ross, K. W. (2004).
Computer Networking: A Top-Down Approach Featuring the
Internet, 2nd ed.
Addison-Wesley.
- [Lamport 1978]
-
Lamport, L. (1978).
Time, Clocks, and the Ordering of Events in a Distributed System.
Communications of the ACM, 21(7):558-56.
- [Leclercq et al. 2005]
-
Leclercq, M., Quéma, V., and Stefani, J.-B. (2005).
DREAM: a Component Framework for the Construction of Resource-Aware,
Configurable MOMs.
IEEE Distributed Systems Online, 6(9).
- [Leiner et al. 2003]
-
Leiner, B. M., Cerf, V. G., Clark, D. D., Kahn, R. E., Kleinrock, L., Lynch,
D. C., Postel, J., Roberts, L. G., and Wolff, S. (2003).
A Brief History of the Internet.
The Internet Society.
http://www.isoc.org/internet/history/brief.shtml.
- [Loo et al. 2005]
-
Loo, B., Condie, T., Hellerstein, J., Maniatis, P., Roscoe, T., and Stoica, I.
(2005).
Implementing declarative overlays.
In Proceedings of the 20th ACM Symposium on Operating System
Principles (SOSP'05), pages 75-90, Brighton, UK.
- [Miranda et al. 2001]
-
Miranda, H., Pinto, A., and Rodrigues, L. (2001).
Appia: A flexible protocol kernel supporting multiple coordinated
channels.
In Proc. 21st International conference on Distributed Computing
Systems (ICDCS'01), pages 707-710, Phoenix, Arizona, USA. IEEE Computer
Society.
- [Mosberger and Peterson 1996]
-
Mosberger, D. and Peterson, L. L. (1996).
Making paths explicit in the Scout operating system.
In Operating Systems Design and Implementation (OSDI'96), pages
153-167.
- [Peterson et al. 2004]
-
Peterson, L., Shenker, S., and Turner, J. (2004).
Overcoming the Internet impasse through virtualization.
In Third Workshop on Hot Topics in Networking (HotNets-III),
San Diego, CA.
- [Peterson and Davie 2003]
-
Peterson, L. L. and Davie, B. S. (2003).
Computer Networks - a Systems Approach.
Morgan Kaufmann, 3rd edition.
815 pp.
- [Polastre et al. 2005]
-
Polastre, J., Hui, J., Levis, P., Zhao, J., Culler, D., Shenker, S., and
Stoica, I. (2005).
A unifying link abstraction for wireless sensor networks.
In Proceedings of the Third ACM Conference on Embedded Networked
Sensor Systems (SenSys).
- [Ratnasamy et al. 2001]
-
Ratnasamy, S., Francis, P., Handley, M., Karp, R., and Shenker., S. (2001).
A scalable content-addressable network.
In Proceedings of the ACM SIGCOMM Symposium on Communication,
Architecture, and Protocols, pages 161-172, San Diego, CA, USA.
- [Rowstron and Druschel 2001]
-
Rowstron, A. and Druschel, P. (2001).
Pastry: Scalable, decentralized object location and routing for
large-scale peer-to-peer systems.
In IFIP/ACM International Conference on Distributed Systems
Platforms (Middleware), pages 329-350, Heidelberg, Germany.
- [Saltzer et al. 1984]
-
Saltzer, J. H., Reed, D. P., and Clark, D. D. (1984).
End-to-end arguments in system design.
ACM Transactions on Computer Systems, 2(4):277-288.
- [Stallings 2005]
-
Stallings, W. (2005).
Wireless Communications & Networks.
Prentice Hall, 2nd edition.
- [Stevens et al. 2004]
-
Stevens, W. R., Fenner, B., and Rudoff, A. M. (2004).
Unix Network Programming, vol. 1.
Addison-Wesley.
- [Stoica et al. 2003]
-
Stoica, I., Morris, R., Liben-Nowell, D., Karger, D. R., Kaashoek, M., Dabek,
F., and Balakrishnan, H. (2003).
Chord: a scalable peer-to-peer lookup protocol for Internet
applications.
IEEE/ACM Transactions on Networking, 11(1):17-32.
- [Svetz et al. 1996]
-
Svetz, K., Randall, N., and Lepage, Y. (1996).
MBone: Multicasting Tomorrows's Internet.
IDG Books Worldwide.
Online at http://www.savetz.com/mbone/.
- [Tai and Rouvellou 2000]
-
Tai, S. and Rouvellou, I. (2000).
Strategies for integrating messaging and distributed object
transactions.
In Sventek, J. and Coulson, G., editors, Middleware 2000,
Proceedings IFIP/ACM International Conference on Distributed Systems
Platforms, volume 1795 of Lecture Notes in Computer Science, pages
308-330. Springer-Verlag.
- [Tanenbaum and van Steen 2006]
-
Tanenbaum, A. S. and van Steen, M. (2006).
Distributed Systems: Principles and Paradigms.
Prentice Hall, 2nd edition.
686 pp.
- [van Renesse et al. 1996]
-
van Renesse, R., Birman, K. P., and Maffeis, S. (1996).
Horus: a flexible group communication system.
Communications of the ACM, 39(4):76-83.
- [Wang 2001]
-
Wang, Z. (2001).
Internet QoS.
Morgan Kaufmann.
240 pp.
- [Zhao and Guibas 2004]
-
Zhao, F. and Guibas, L. (2004).
Wireless Sensor Networks: An Information Processing Approach.
Morgan Kaufmann.
- [Zimmermann 1980]
-
Zimmermann, H. (1980).
OSI Reference Model-The ISO Model of Architecture for Open Systems
Interconnection.
IEEE Transactions on Communications, 28(4):425-432.