CNRS MASTODONS ELM
ELM: Employees’ Lives Matter : Transparency and Discrimination in Crowdsourcing
CrowdFair : Un outil d’aide à la non-discrimination dans les plateformes participatives
Sihem Amer-Yahia (LIG/CNRS)
Collaborateurs : Aida Bennini (MDF – CESICE / UGA), Sabrina Mraouahi (MDC UGA), Shady ElBassuoni (Prof., AUB, Liban), Christine El Atie (étudiante en Master, AUB, Liban), Bilel Oualha (étudiant ENSTA),
Le thème :
Nous traitons de la question de la discrimination dans les plateformes participatives avec comme objectif de développer un modèle et des algorithmes pour tester la discrimination dans l’assignation de tâches postées par des requesters (fournisseurs de tâches) aux participants (workers), i.e., le task assignment (voir Figure ci-contre). La discrimination algorithmique est un sujet récent qui prend de l’ampleur dans les communautés de l’apprentissage (biais dans la prise de décision) et de la fouille de données (biais dans les tendances) [1]. L’espace des données en entrée et celui des décisions en sortie sont supposés être des espaces métriques afin de calculer la discrimination comme des distances.
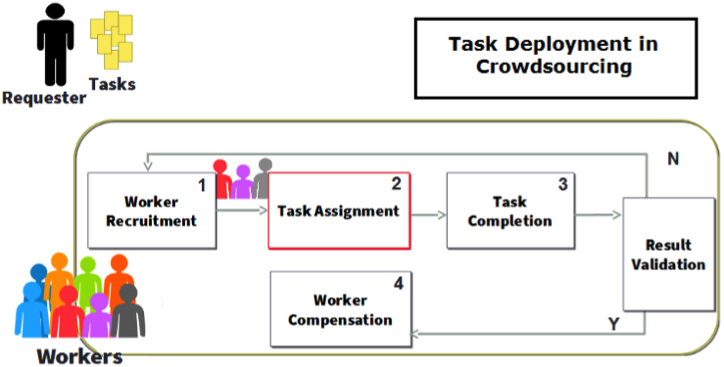
Bien que plusieurs définitions de la discrimination existent, l’approche la plus utilisée aujourd’hui est celle de partitionner les données en entrée de sorte à ce qu’un algorithme ne discrimine pas entre les partitions [2][3][4][5][6][7]. Par exemple, une partition sur le lieu d’habitation permettrait de dire si un algorithme de décision (ex., admission à l’université) discrimine sur la base de la provenance des individus en calculant la distance entre les données en entrée d’un côté, et les décisions en sortie de l’autre. On parle alors de distorsion et de tolérance de distorsion lorsque différentes décisions pour différentes partitions sont comparées.
Le projet MASTODONS ELM (Employees Lives Matter) est le premier projet à s’intéresser à formaliser et vérifier la discrimination dans les plateformes participatives. Nous avons étudié la discrimination dans le choix des tâches à attribuer aux participants. Les travaux sur la discrimination algorithmiques ont jusque là supposé que les données en entrée sont transparentes (afin de constituer des partitions et de calculer des distances) et que le processus de décision ne l’est pas (ce qui reflète la réalité en général). Dans ELM, nous avons généralisé ces hypothèses et adopté deux approches pour évaluer la discrimination : une approche basée sur des juges humains et une approche algorithmique. Nous nous sommes d’abord posé la question de la sensibilité des participants à rendre leurs données transparentes et de la capacité des juges à
évaluer la discrimination selon que les données ou les processus soient transparents ou opaques. Nous avons ensuite développé un simulateur pour étudier le pouvoir discriminatoire de fonctions d’assignation de tâches pour différents partitionnement des participants. Nos résultats, aujourd’hui empiriques, sont une preuve de concept qui justifie le développement d’un cadre formel et d’algorithmes afin d’aider les requesters à choisir les fonctions d’assignation les moins discriminatives possible.
Résultats actuels :
1. Du point de vue juridique, nous avons réalisé une recherche documentaire en droit des affaires et droit social sur le crowdsourcing, une typologie du crowdsourcing et une confirmation de l’état de l’art en droits interne et européen. Le crowdsourcing est une forme de collaboration entre consommateurs qui peut être assimilée à un contrat de
travail. Néanmoins, il n’existe pas de cadre juridique clair (ex., prestation de service?) permettant de régir les liens entre les différentes parties, i.e., plateforme et participants (workers et requesters). Nous avons fait une revue des conditions générales de la plateforme française FouleFactory (https://www.foulefactory.com/) et une prise de contact pour définir le périmètre juridique. Nous réfléchissons à une ébauche couvrant la discrimination dans l’assignation de tâches. Les conditions générales de la plateforme et l’énoncé même des tâches sont une base de contrat entre les participants et la plateforme dans un cas, et les participants et les requesters dans l’autre. Le droit pénal sanctionne les comportements discriminatoires. L’article 225-1 du Code pénal compte 23 motifs discriminatoires différents dont l’origine, le sexe, la situation de famille, l’apparence physique, le lieu de résidence, et l’état de santé. Ce sont ces 23 motifs que nous avons utilisés dans notre évaluation empirique.
2. Du point de vue informatique, nous avons déployé des tâches permettant à des juges d’évaluer la discrimination sous différentes conditions de transparence. Nous avons trouvé que les juges préfèrent la transparence des données à la transparence du processus d’assignation. En effet, ils considèrent pouvoir mieux juger le pouvoir discriminatoire d’une assignation (même opaque !) si les données des participants et les tâches qui leur sont assignées leur sont fournies. Nous avons également trouvé que les participants (workers) ne sont pas sensibles à l’exposition de leurs données personnelles aux requesters et qu’ils préfèrent que leurs données soient mises à disposition des requesters (considérant que l’assignation de tâches leur sera plus juste). Enfin, nous avons confirmé une ancienne théorie selon laquelle les participants préfèrent faire partie d’un processus d’assignation transparent plutôt qu’un processus opaque même si ce dernier est dit plus juste à leur égard ! Nous avons aujourd’hui un cadre dans lequel nous pouvons tester algorithmiquement différentes distances entre des décisions d’assignation de tâches. Nous comptons utiliser ce cadre pour développer notre prochain outil, CrowdFair.
3. Publication d’une article à la conférence EDBT 2017 [2], participation à un panel à EDBT sur l’éthique du data management, mention dans l’article «La justice à l’heure des algorithmes et du Big Data : https://lejournal.cnrs.fr/articles/la-justice-a-lheure-desalgorithmes-et-du-big-data, publication d’un extrait de cet article dans la revue Carnets de science, CNRS Editions : https://carnetsdescience-larevue.fr/, participation à la conférence de l’Association Française du droit du travail du 19 mai 2017 à Paris, participation aux journées sur les Convergences du droit et du numérique en septembre 2017 à Bordeaux sur les contours du droit du travail face à l’ubérisation des rapports de travail et rédaction d’une note sur les enjeux juridiques du crowdsourcing, soumission d’un papier avec Christine et Shady à la première AAAI/ACM Conference on AI, Ethics, and Society – AIES 2018 : http://www.aies-conference.com/ et préparation d’un nouveau papier sur les approches algorithmiques de la détection et réparation de la discrimination.
Justification scientifique :
L’objectif de notre nouvelle demande de développer CrowdFair, un outil permettant de répondre à des questions comme : pour un ensemble de participants et un ensemble de fonctions d’assignation, trouver le meilleur partitionnement des participants pour chaque fonction, i.e., celui offrant le moins de discrimination. Nous aimerions ensuite étudier cette question dans le cas où l’ensemble des participants évolue. Nous aimerions continuer sur la lancée très positive du projet pour permettre une soumission ANR l’année prochaine.
Justification logistique :
ELM est un projet CNRS MASTODONS (financement 2017) dont l’objectif était de rapprocher des juristes de l’UGA (Aida Bennini et Sabrina Mraouhi) et des informaticiens (Sihem Amer-Yahia) pour l’étude de la transparence et de la discrimination dans les plateformes participatives. Nous avons reçu 15000 euros ce qui a permis d’aller en mission, de rémunérer des travailleurs sur les plateformes de crowdsourcing (Amazon Mechanical Turk, FouleFactory et Prolific Academic), de prendre trois stagiaires (un stagiaire 2ème année ingénieur de l’ENSTA, une stagiaire en droit, et une stagiaire en Master à l’Université Américaine de Beyrouth). ELM a permis de lancer une collaboration avec Prof. Shady ElBassuoni de l’Université Américaine de Beyrouth.
Résultats escomptés :
L’outil CrowdFair, trois publications scientifiques (une soumission conférence avec Christine et Shady, une soumission de démonstration de CrowdFair, et une soumission à une revue avec les juristes). Nous aimerions nous rapprocher davantage de la plateforme française FouleFactory qui nous a donné un accord de principe pour l’utilisation de leur sandbox pour tester différentes approches d’assignation de tâches.
Références :
[1] Friedler, S. A.; Scheidegger, C.; and Venkatasubramanian, S. On the (im)possibility of fairness. CoRR abs/1609.07236, 2016.
[2] Borromeo, R. M.; Laurent, T.; Toyama, M.; and Amer-Yahia, S. Fairness and transparency in crowdsourcing. In EDBT 2017.
[3] Kirkpatrick, K. Battling algorithmic bias: how do we ensure algorithms treat us fairly? Commun. ACM 59:16–17, 2016.
[4] Luca, M., and Fisman, R. Fixing discrimination in online marketplaces. Harvard Business Review 2016.
[5] Sweeney, L.. Discrimination in online ad delivery. CoRR abs/1301.6822, 2013.
[6] Tramer, F.; Atlidakis, V.; Geambasu, R.; Hsu, D. J.; Hubaux, J.; Humbert, M.; Juels, A.; and Lin, H. Discovering unwarranted associations in data-driven applications with the fairtest testing toolkit. CoRR abs/1510.02377, 2015.
[7] Zafar, M. B.; Valera, I.; Rodriguez, M. G.; and Gummadi, K. P. 2017a. Fairness beyond disparate treatment & disparate impact. In WWW 2017.